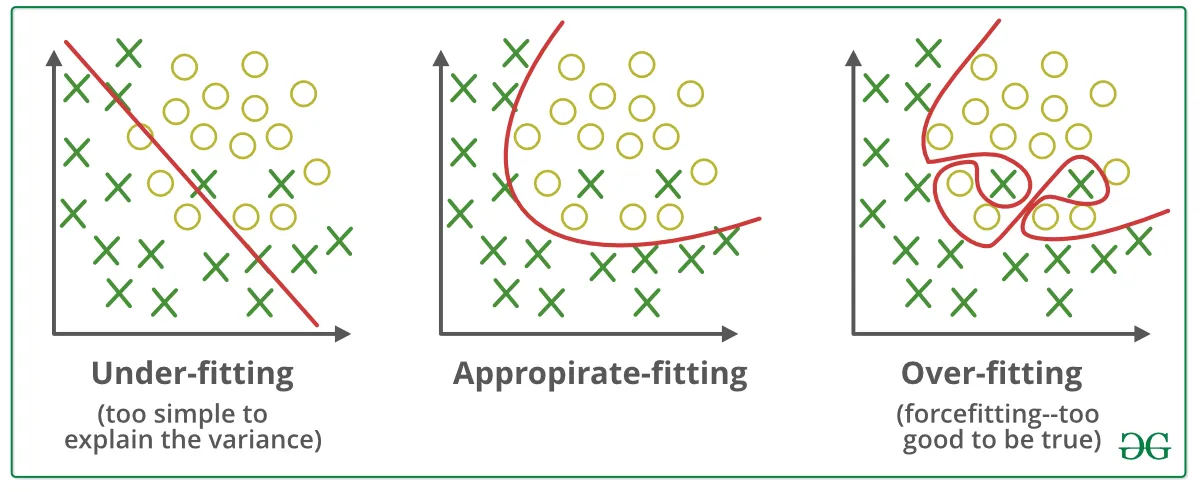
Regularization is a set of techniques which can help avoid overfitting in neural networks, thereby improving the accuracy of deep learning models when it is fed entirely new data from the problem domain. There are various regularization techniques, some of the most popular ones are — L1, L2, dropout, early stopping, and data augmentation.
Why is Regularization Required?
The characteristic of a good machine learning model is its ability to generalise well from the training data to any data from the problem domain; this allows it to make good predictions on the data that model has never seen. To define generalisation, it refers to how well the model has learnt the concepts to apply to any data rather than just with the specific data it was trained on during the training process.
#data-science