Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets, and can also distribute data processing tasks across multiple computers, either on its own or in tandem with other distributed computing tools. These two qualities are key to the worlds of big data and machine learning, which require the marshalling of massive computing power to crunch through large data stores. Spark also takes some of the programming burdens of these tasks off the shoulders of developers with an easy-to-use API that abstracts away much of the grunt work of distributed computing and big data processing.
To run your spark jobs in full power, it is important to configure and tune them properly. A single common configuration or style may not suit all the use cases, so it is very important to first understand a use case and then configure the spark jobs based on that.
This article will focus on the common Apache spark recommended configurations as well as on factors that help decide these configurations. We will also cover how to write/code the spark jobs in a more efficient manner to enhance the speed and optimise the memory utilisations.
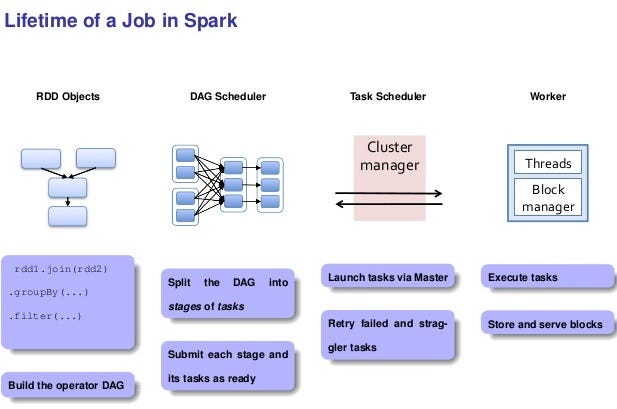
When you write Apache Spark code and page through the public APIs, you come across words like transformation, action, and RDD. Understanding Spark at this level is vital for writing Spark programs. Similarly, when things start to fail, or when you venture into the web UI to try to understand why your application is taking so long, you’re confronted with a new vocabulary of words like job, stage, and task. Understanding Spark at this level is vital for writing good Spark programs, and of course by good, I mean fast. To write a Spark program that will execute efficiently, it is very, very helpful to understand Spark’s underlying execution model.
Before we begin, lets understand a few important spark terms :-
#spark-sql #big-data #spark #apache-spark