Machine learning practitioners and data engineers are well aware of the repeatable nature of data sourcing, gathering, cleaning, transforming, merging, and labeling. The purpose of these activities are to prepare data for reduction, exploratory analysis, or modeling. scikit-learn, for example, has done a fantastic job at abstracting data pipelines via their Pipeline class. Still, the problem of pulling data from multiple sources remains as there are not many simple abstractions making the data wrangler’s life easier.
Problem Statement: Disparate data are disparate and cumbersome to coalesce.
Solution: Develop a pythonic database abstraction to coalesce your data in an easy-to-use, robust, and production-ready way.
Table of Contents
- Abstractions
- Database — Without a Database — Abstraction
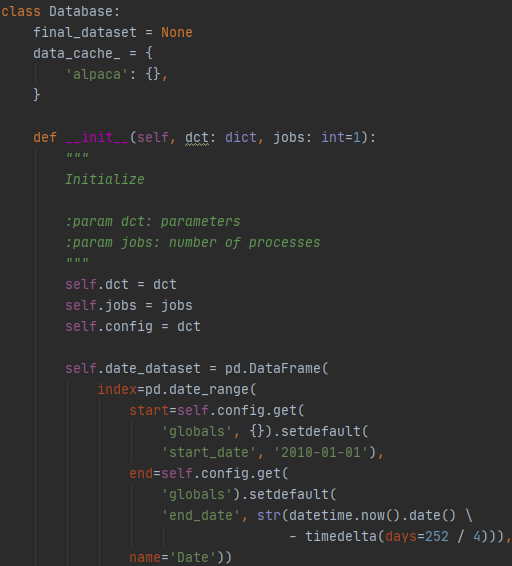
- Introducing A Python Database Abstraction
- How To
Key Concepts
Abstractions make programming life more manageable. A database — without a database — abstraction will make your data wrangling life more comfortable, and will be a robust addition to your production pipeline.
1. Abstractions
In an effort not to duplicate the articles on the web, I will not explain abstractions, but here are two references:
- “Critical Concept: Abstraction” (via Medium)
- “OOP Concept for Beginners: What is Abstraction?” (via Stackify)
An abstraction is defined as something that sits on top of something more complex and makes it more simple for the user. — Matt Burgess in “Critical Concept: Abstraction”
#python #abstraction #database #data-wrangling #data-science