If you are already familiar with NumPy, Pandas is just a package build on top of it. Pandas provide more flexibility than NumPy to work with data. While in NumPy we can only store values of single data type(dtype) Pandas has the flexibility to store values of multiple data type. Hence, we say Pandas is heterogeneous. We will unpack several more advantages of Pandas today.
Since we will be referring to NumPy in every section, I’m assuming you have knowledge of NumPy if not I will be dropping links to resources at the end of the article.
I’m considering the very popular Titanic datset to unpack the abilities of Pandas. You don’t have to worry because I will still be introducing the concepts of Pandas step-by-step keeping in mind you are a newbie to Pandas package.
Let’s just quickly import Pandas, Numpy, and load the Titanic dataset.
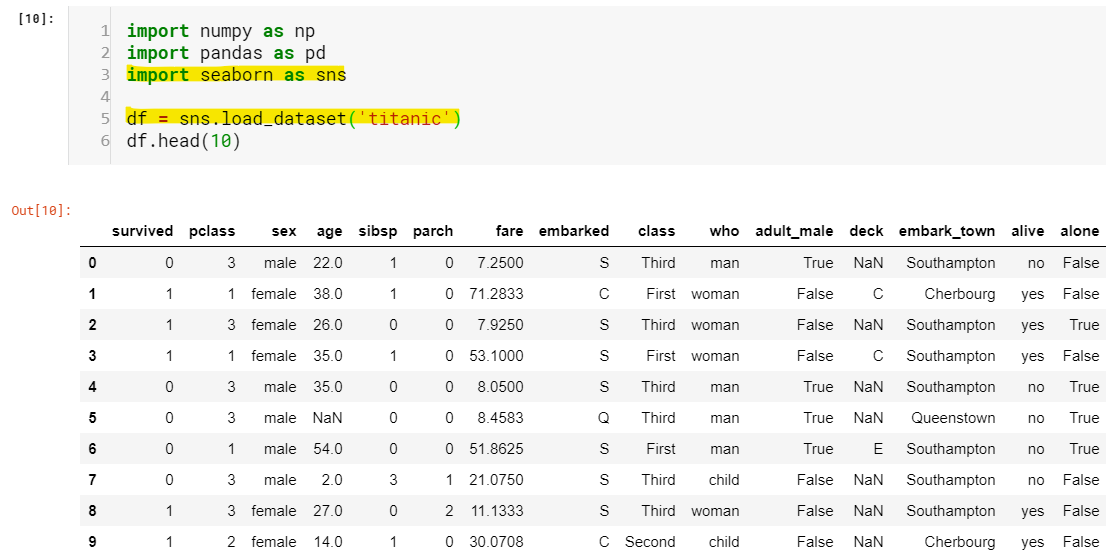
Figure-0
I know, a lot to digest at once but we will break it down at the course of time. For now, don’t worry about line 3 and line 5(highlighted). Just understand that the seaborn package has the dataset in it and we loaded it, that’s all. You might have already figured out that ‘df’ holds our entire dataset but wait, what is the data type of 'df’? and what on Earth is ‘df.head(10)’. This brings us to our first topic Pandas objects: Series and DataFrame.
#python #data-analysis #pandas-dataframe #data-science #pandas
