A continuation of an earlier article
Please find the link for part 1
Artificial Neural Networks- An intuitive approach Part 1
A comprehensive yet simple approach to the basics of deep learning
Contents
- Perceptron Learning
- Methods of updating the weights
- Weight decay learning rate
- learning rate
- Hyperparameter fixing:
Perceptron Learning

Let us recap what the Perceptron’s do in it’s most basic function.
- Perceptrons take inputs , scale/multiple them with weights , sum them up and then pass them through an activation function to obtain a result.
- The weights are initialized randomly for the first instance to obtain an output.
- The weights are then adjusted to minimize the error using optimization of a loss function and regularization(Please go through the concept of regularization)
- Gradient descent is used to optimize the loss function to obtain a minimum value of error.
Note: For a quick refresher on gradient descent it is recommended to go through the below link
Understanding the Mathematics behind Gradient Descent.
Methods of updating the weights:
There are multiple methods of updating the weights:
After the loss is calculated, the gradient of the loss is calculated with respect to the weights, since the loss function is actually a function of the weights of the neural network which are independent of each other. It’s like the loss is a multi variable function of the weights. The weights now are updated in a direction opposite to the gradient. This will decrease the loss function. That’s the aim. Over the training process, the weights which were initialized randomly or with some initial value, keep on updating such that the loss function is minimized.
Note: Online and stochastic gradient descent are the same things

Multiple methods of updating the weights
One epoch typically means your algorithm sees every training instance once. Now assuming you have “nn” training instances:
If you run batch update, every parameter update requires your algorithm see each of the “nn” training instances exactly once, i.e., every epoch your parameters are updated once.
If you run mini-batch update with batch size = bb, every parameter update requires your algorithm see “bb” of “nn” training instances, i.e., every epoch your parameters are updated about n/bn/b times.
If you run SGD(Stochastic Gradient descent)update, every parameter update requires your algorithm to see 1 of nn training instances, i.e., every epoch your parameters are updated about nn times.
to make the above points clearer let us take an example:
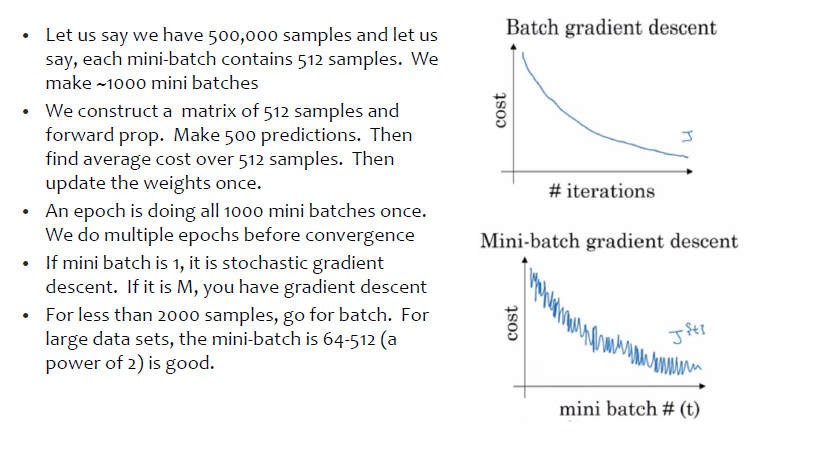
In Gradient Descent or Batch Gradient Descent, we use the whole training data per epoch whereas, in Stochastic Gradient Descent(online), we use only single training example per epoch and Mini-batch Gradient Descent lies in between of these two extremes, in which we can use a mini-batch(small portion) of training data per epoch.
Now let us introduce two important concepts Weight decay and Learning Rate.
Weight decay:
Neural networks learn a set of weights through iterations while propagating the error backwards
A network with large we_ights may _signal an unstable network as small changes in the input could lead to large changes in the output. This might indicate that the the network has overfit on the training data and will fit poorly on the test data
Large weights make the network unstable. Although the weight will be specialized to the training dataset, minor variation or statistical noise on the expected inputs will result in large differences in the output.
A solution to this problem is to update the learning algorithm to encourage the network to keep the weights small. This is called weight regularization and it can be used as a general technique to reduce overfitting of the training dataset and improve the generalization of the model.
Since regularization is a basic concept ( I expect the readers to be aware of regularization concepts) though we will recap some of the basics here
Another possible issue is that there may be many input variables, each with different levels of relevance to the output variable. Sometimes we can use methods to aid in selecting input variables, but often the interrelationships between variables is not obvious.
Having small weights or even zero weights for less relevant or irrelevant inputs to the network will allow the model to focus learning. This too will result in a simpler model.
Encourage Small Weights
The learning algorithm can be updated to encourage the network toward using small weights.
One way to do this is to change the calculation of loss used in the optimization of the network to also consider the size of the weights.
The addition of a weight size penalty or weight regularization to a neural network has the effect of reducing generalization error and of allowing the model to pay less attention to less relevant input variables.
#mini-batch-gradient #weight-updates #artificial-neural-network #deep-learning #perceptron #deep learning