This article is the successor to my previous article on Quantization. In this article, we’re going to go over the mechanics of model pruning in the context of deep learning. Model pruning is the art of discarding those weights that do not signify a model’s performance. Carefully pruned networks lead to their better-compressed versions and they often become suitable for on-device deployment scenarios.The content of the article is structured into the following sections:
- The notion of “Non-Significance” in Functions and Neural NetworksPruning a Trained Neural NetworkCode Snippets and Performance Comparisons between Different ModelsModern Pruning TechniquesFinal Thoughts and Conclusion
(The code snippets that we’ll be discussing will be based on TensorFlow (2) and the TensorFlow Model Optimization Toolkit)Note: The article is mirrored here.
Notion of “Non-Significance” in Functions
Neural networks are function approximators. We train them to learn functions that capture underlying representations formulating the input data points. The weights and the biases of a neural network are referred to as its (learnable) parameters. Often, the weights are referred to as coefficients of the function being learned.Consider the following function -
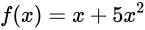
In the above function, we have two terms on the RHS: x and x². The coefficients are 1 and 5 respectively. In the following figure, we can see that the behavior of the function does not change much when the first coefficient is nudged.
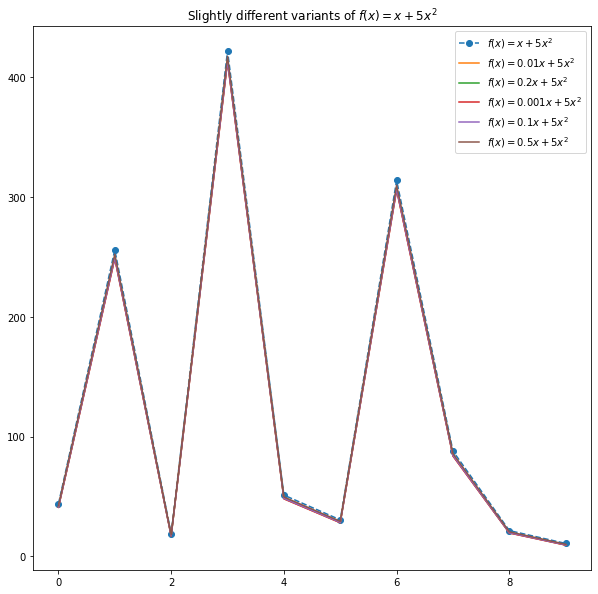
Here are the coefficients in the different variants of the original function can be referred to as non-significant. Discarding those coefficients won’t really change the behavior of the function.
Extension to Neural Networks
The above concept can be applied to neural networks as well. This needs a bit more details to be unfolded. Consider the weights of a trained network. How could we make sense of the weights that are non-significant? What’s the premise here?For this to be answered, consider the optimization process with gradient descent. Not all the weights are updated using the same gradient magnitudes. The gradients of a given loss function are taken with respect to the weights (and biases). During the optimization process, some of the weights are updated with larger gradient magnitudes (both positive and negative) than the others. These weights are considered to be significant by the optimizer to minimize the training objective. The weights that receive relatively smaller gradients can be considered as non-significant.After the training is complete, we can inspect the weight magnitudes of a network layer by layer and figure out the weights that are significant. This decision be made using several heuristics -
- We can sort the weight magnitudes in a descending manner and pick up the ones that appear earlier in the queue. This is typically combined with a sparsity level (percentage of weights to be pruned) we would want to achieve.We can specify a threshold and all the weights whose magnitudes would lie above that threshold would be considered as significant. This scheme can have several flavors:
i. The threshold can be the weight magnitude that is the lowest inside the entire network.ii. The threshold can be the weight magnitude local to the layers inside a network. In this case, the significant weights are filtered out on a layer by layer basis.If all of these are becoming hard to comprehend, don’t worry. In the next section, things will become clearer.
Pruning a Trained Neural Network
Now that we have a fair bit of understanding of what could be called significant weights, we can discuss magnitude-based pruning. In magnitude-based pruning, we consider weight magnitude to be the criteria for pruning. By pruning what we really mean is zeroing out the non-significant weights. Following code, snippet might be helpful to understand this -
# Copy the kernel weights and get ranked indices of the
# column-wise L2 Norms
kernel_weights = np.copy(k_weights)
ind = np.argsort(np.linalg.norm(kernel_weights, axis=0))
# Number of indices to be set to 0
sparsity_percentage = 0.7
cutoff = int(len(ind)*sparsity_percentage)
# The indices in the 2D kernel weight matrix to be set to 0
sparse_cutoff_inds = ind[0:cutoff]
kernel_weights[:,sparse_cutoff_inds] = 0.
view raw
magnitude_pruning_l2.py hosted with ❤ by GitHub
(This code snippet comes from here)Here’s a pictorial representation of the transformation that would be happening to the weights after they have been learned -

It can be applied to the biases also. It’s important to note that here we consider an entire layer receiving an input of shape (1,2) and containing 3 neurons. It’s often advisable to retrain the network after it is pruned to compensate for any drop in its performance. When doing such retraining it’s important to note that, the weights that were pruned, won’t be updated during the retraining.
Seeing Things in Action
Enough jibber-jabber! Let’s see these things in action. To keep things simple we’ll be testing these concepts on the MNIST dataset but you should be able to extend them to more complex datasets as well. We’ll be using a shallow fully-connected network having the following topology -
#production-ml #model-optimization #keras #wandb #tensorflow #deep learning