Getting Started with Web Scraping with Node.js
So what’s web scraping anyway? It involves automating away the laborious task of collecting information from websites.
There are a lot of use cases for web scraping: you might want to collect prices from various e-commerce sites for a price comparison site. Or perhaps you need flight times and hotel/AirBNB listings for a travel site. Maybe you want to collect emails from various directories for sales leads, or use data from the internet to train machine learning/AI models. Or you could even be wanting to build a search engine like Google!
Getting started with web scraping is easy, and the process can be broken down into two main parts:
- acquiring the data using an HTML request library or a headless browser,
- and parsing the data to get the exact information you want.
This guide will walk you through the process with the popular Node.js request-promise module, CheerioJS, and Puppeteer. Working through the examples in this guide, you will learn all the tips and tricks you need to become a pro at gathering any data you need with Node.js!
We will be gathering a list of all the names and birthdays of U.S. presidents from Wikipedia and the titles of all the posts on the front page of Reddit.
First things first: Let’s install the libraries we’ll be using in this guide (Puppeteer will take a while to install as it needs to download Chromium as well).
Making your first request
npm install --save request request-promise cheerio puppeteer
Next, let’s open a new text file (name the file potusScraper.js), and write a quick function to get the HTML of the Wikipedia “List of Presidents” page.
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
});
Output:
<!DOCTYPE html>
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>List of Presidents of the United States - Wikipedia</title>
...
Using Chrome DevTools
Cool, we got the raw HTML from the web page! But now we need to make sense of this giant blob of text. To do that, we’ll need to use Chrome DevTools to allow us to easily search through the HTML of a web page.
Using Chrome DevTools is easy: simply open Google Chrome, and right click on the element you would like to scrape (in this case I am right clicking on George Washington, because we want to get links to all of the individual presidents’ Wikipedia pages):
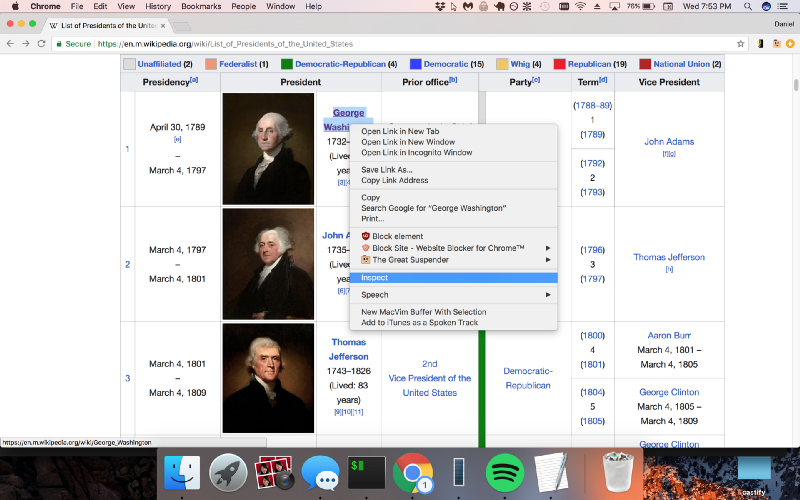
Now, simply click inspect, and Chrome will bring up its DevTools pane, allowing you to easily inspect the page’s source HTML.
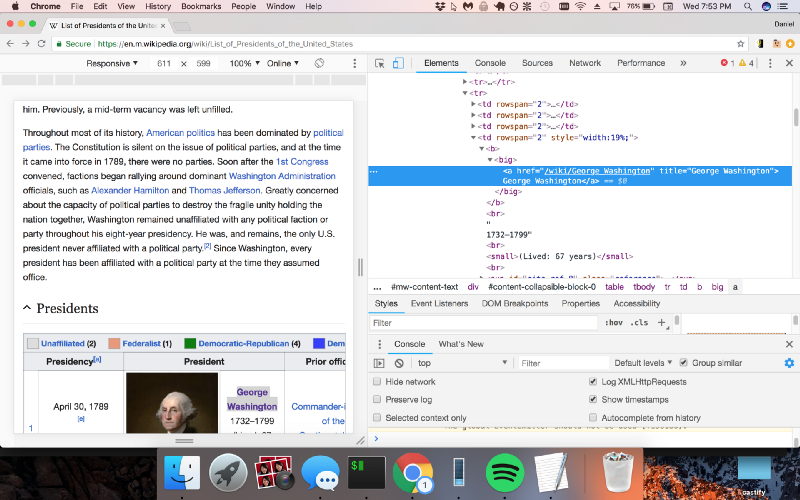
Parsing HTML with Cheerio.js
Awesome, Chrome DevTools is now showing us the exact pattern we should be looking for in the code (a “big” tag with a hyperlink inside of it). Let’s use Cheerio.js to parse the HTML we received earlier to return a list of links to the individual Wikipedia pages of U.S. presidents.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
console.log($('big > a', html).length);
console.log($('big > a', html));
})
.catch(function(err){
//handle error
});
Output:
45
{ '0':
{ type: 'tag',
name: 'a',
attribs: { href: '/wiki/George_Washington', title: 'George Washington' },
children: [ [Object] ],
next: null,
prev: null,
parent:
{ type: 'tag',
name: 'big',
attribs: {},
children: [Array],
next: null,
prev: null,
parent: [Object] } },
'1':
{ type: 'tag'
...
We check to make sure there are exactly 45 elements returned (the number of U.S. presidents), meaning there aren’t any extra hidden “big” tags elsewhere on the page. Now, we can go through and grab a list of links to all 45 presidential Wikipedia pages by getting them from the “attribs” section of each element.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html){
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('big > a', html)[i].attribs.href);
}
console.log(wikiUrls);
})
.catch(function(err){
//handle error
});
Output:
[
'/wiki/George_Washington',
'/wiki/John_Adams',
'/wiki/Thomas_Jefferson',
'/wiki/James_Madison',
'/wiki/James_Monroe',
'/wiki/John_Quincy_Adams',
'/wiki/Andrew_Jackson',
...
]
Now we have a list of all 45 presidential Wikipedia pages. Let’s create a new file (named potusParse.js), which will contain a function to take a presidential Wikipedia page and return the president’s name and birthday. First things first, let’s get the raw HTML from George Washington’s Wikipedia page.
const rp = require('request-promise');
const url = 'https://en.wikipedia.org/wiki/George_Washington';
rp(url)
.then(function(html) {
console.log(html);
})
.catch(function(err) {
//handle error
});
Output:
<html class="client-nojs" lang="en" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>George Washington - Wikipedia</title>
...
Let’s once again use Chrome DevTools to find the syntax of the code we want to parse, so that we can extract the name and birthday with Cheerio.js.
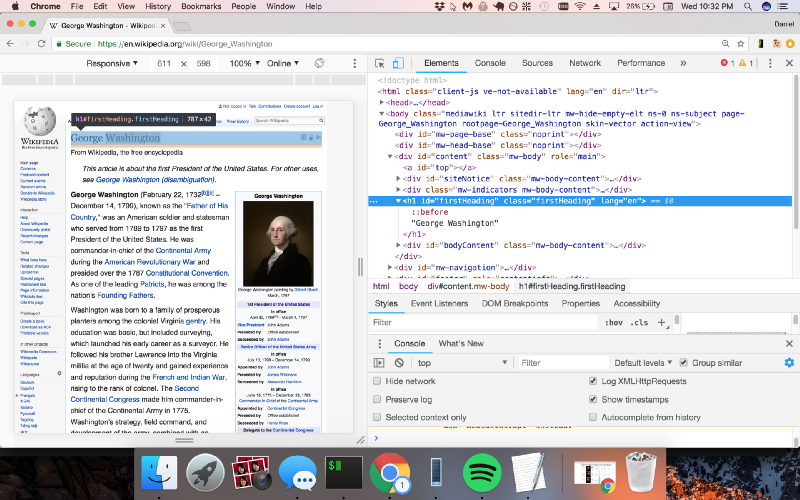
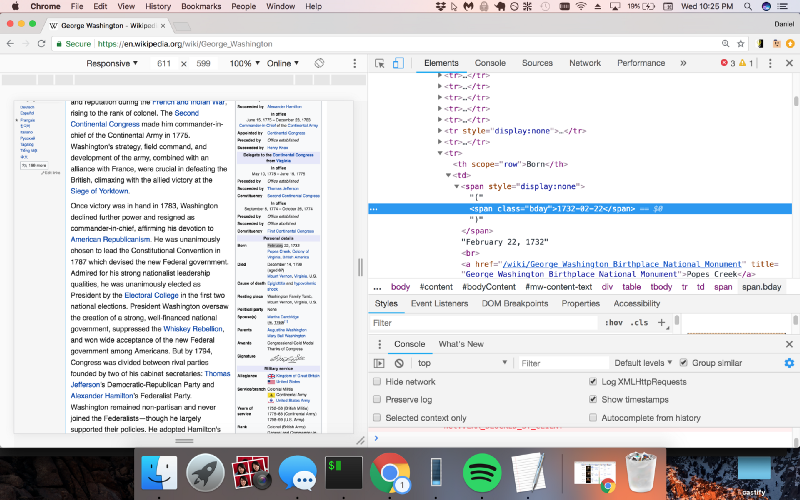
So we see that the name is in a class called “firstHeading” and the birthday is in a class called “bday”. Let’s modify our code to use Cheerio.js to extract these two classes.
const rp = require('request-promise');
const $ = require('cheerio');
const url = 'https://en.wikipedia.org/wiki/George_Washington';
rp(url)
.then(function(html) {
console.log($('.firstHeading', html).text());
console.log($('.bday', html).text());
})
.catch(function(err) {
//handle error
});
Output:
George Washington
1732-02-22
Putting it all together
Perfect! Now let’s wrap this up into a function and export it from this module.
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = function(url) {
return rp(url)
.then(function(html) {
return {
name: $('.firstHeading', html).text(),
birthday: $('.bday', html).text(),
};
})
.catch(function(err) {
//handle error
});
};
module.exports = potusParse;
Now let’s return to our original file potusScraper.js and require the potusParse.js module. We’ll then apply it to the list of wikiUrls we gathered earlier.
const rp = require('request-promise');
const $ = require('cheerio');
const potusParse = require('./potusParse');
const url = 'https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States';
rp(url)
.then(function(html) {
//success!
const wikiUrls = [];
for (let i = 0; i < 45; i++) {
wikiUrls.push($('big > a', html)[i].attribs.href);
}
return Promise.all(
wikiUrls.map(function(url) {
return potusParse('https://en.wikipedia.org' + url);
})
);
})
.then(function(presidents) {
console.log(presidents);
})
.catch(function(err) {
//handle error
console.log(err);
});
Output:
[
{ name: 'George Washington', birthday: '1732-02-22' },
{ name: 'John Adams', birthday: '1735-10-30' },
{ name: 'Thomas Jefferson', birthday: '1743-04-13' },
{ name: 'James Madison', birthday: '1751-03-16' },
{ name: 'James Monroe', birthday: '1758-04-28' },
{ name: 'John Quincy Adams', birthday: '1767-07-11' },
{ name: 'Andrew Jackson', birthday: '1767-03-15' },
{ name: 'Martin Van Buren', birthday: '1782-12-05' },
{ name: 'William Henry Harrison', birthday: '1773-02-09' },
{ name: 'John Tyler', birthday: '1790-03-29' },
{ name: 'James K. Polk', birthday: '1795-11-02' },
{ name: 'Zachary Taylor', birthday: '1784-11-24' },
{ name: 'Millard Fillmore', birthday: '1800-01-07' },
{ name: 'Franklin Pierce', birthday: '1804-11-23' },
{ name: 'James Buchanan', birthday: '1791-04-23' },
{ name: 'Abraham Lincoln', birthday: '1809-02-12' },
{ name: 'Andrew Johnson', birthday: '1808-12-29' },
{ name: 'Ulysses S. Grant', birthday: '1822-04-27' },
{ name: 'Rutherford B. Hayes', birthday: '1822-10-04' },
{ name: 'James A. Garfield', birthday: '1831-11-19' },
{ name: 'Chester A. Arthur', birthday: '1829-10-05' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'Benjamin Harrison', birthday: '1833-08-20' },
{ name: 'Grover Cleveland', birthday: '1837-03-18' },
{ name: 'William McKinley', birthday: '1843-01-29' },
{ name: 'Theodore Roosevelt', birthday: '1858-10-27' },
{ name: 'William Howard Taft', birthday: '1857-09-15' },
{ name: 'Woodrow Wilson', birthday: '1856-12-28' },
{ name: 'Warren G. Harding', birthday: '1865-11-02' },
{ name: 'Calvin Coolidge', birthday: '1872-07-04' },
{ name: 'Herbert Hoover', birthday: '1874-08-10' },
{ name: 'Franklin D. Roosevelt', birthday: '1882-01-30' },
{ name: 'Harry S. Truman', birthday: '1884-05-08' },
{ name: 'Dwight D. Eisenhower', birthday: '1890-10-14' },
{ name: 'John F. Kennedy', birthday: '1917-05-29' },
{ name: 'Lyndon B. Johnson', birthday: '1908-08-27' },
{ name: 'Richard Nixon', birthday: '1913-01-09' },
{ name: 'Gerald Ford', birthday: '1913-07-14' },
{ name: 'Jimmy Carter', birthday: '1924-10-01' },
{ name: 'Ronald Reagan', birthday: '1911-02-06' },
{ name: 'George H. W. Bush', birthday: '1924-06-12' },
{ name: 'Bill Clinton', birthday: '1946-08-19' },
{ name: 'George W. Bush', birthday: '1946-07-06' },
{ name: 'Barack Obama', birthday: '1961-08-04' },
{ name: 'Donald Trump', birthday: '1946-06-14' }
]
Rendering JavaScript Pages
Voilà! A list of the names and birthdays of all 45 U.S. presidents. Using just the request-promise module and Cheerio.js should allow you to scrape the vast majority of sites on the internet.
Recently, however, many sites have begun using JavaScript to generate dynamic content on their websites. This causes a problem for request-promise and other similar HTTP request libraries (such as axios and fetch), because they only get the response from the initial request, but they cannot execute the JavaScript the way a web browser can.
Thus, to scrape sites that require JavaScript execution, we need another solution. In our next example, we will get the titles for all of the posts on the front page of Reddit. Let’s see what happens when we try to use request-promise as we did in the previous example.
Output:
const rp = require('request-promise');
const url = 'https://www.reddit.com';
rp(url)
.then(function(html){
//success!
console.log(html);
})
.catch(function(err){
//handle error
});
}
Here’s what the output looks like:
<!DOCTYPE html><html
lang="en"><head><title>reddit: the front page of the
internet</title>
...
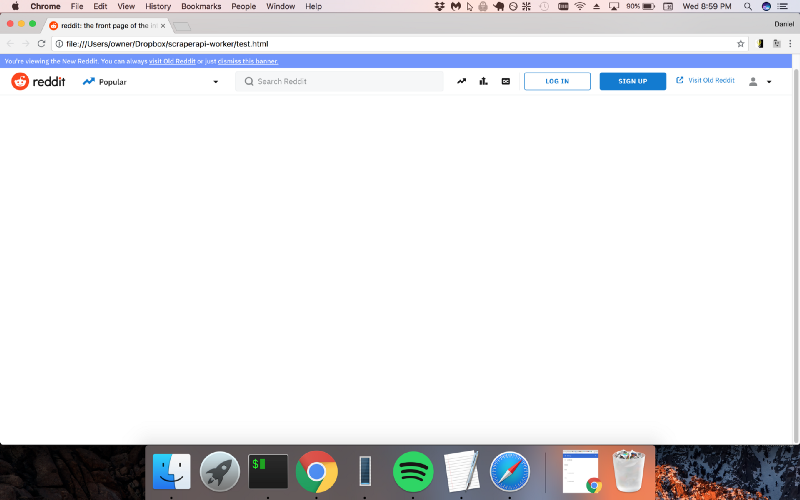
Hmmm…not quite what we want. That’s because getting the actual content requires you to run the JavaScript on the page! With Puppeteer, that’s no problem.
Puppeteer is an extremely popular new module brought to you by the Google Chrome team that allows you to control a headless browser. This is perfect for programmatically scraping pages that require JavaScript execution. Let’s get the HTML from the front page of Reddit using Puppeteer instead of request-promise.
const puppeteer = require('puppeteer');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
console.log(html);
})
.catch(function(err) {
//handle error
});
Output:
<!DOCTYPE html><html lang="en"><head><link
href="//c.amazon-adsystem.com/aax2/apstag.js" rel="preload"
as="script">
...
Nice! The page is filled with the correct content!
Now we can use Chrome DevTools like we did in the previous example.
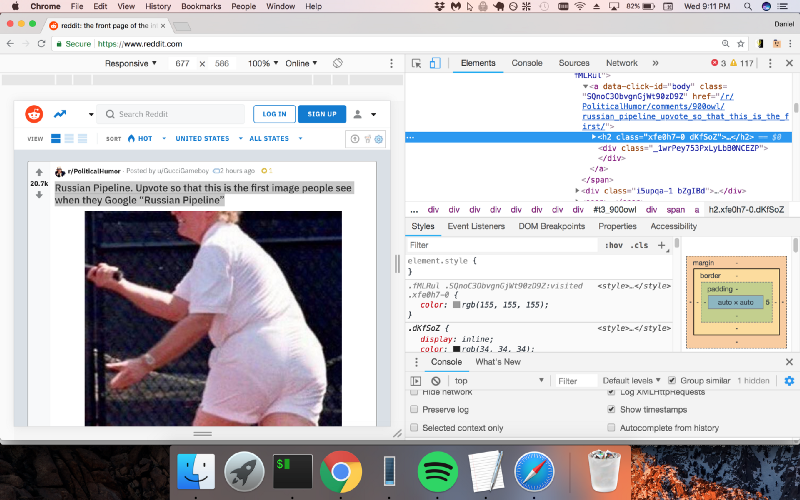
It looks like Reddit is putting the titles inside “h2” tags. Let’s use Cheerio.js to extract the h2 tags from the page.
const puppeteer = require('puppeteer');
const $ = require('cheerio');
const url = 'https://www.reddit.com';
puppeteer
.launch()
.then(function(browser) {
return browser.newPage();
})
.then(function(page) {
return page.goto(url).then(function() {
return page.content();
});
})
.then(function(html) {
$('h2', html).each(function() {
console.log($(this).text());
});
})
.catch(function(err) {
//handle error
});
Output:
Russian Pipeline. Upvote so that this is the first image people see when they Google “Russian Pipeline”
John F. Kennedy Jr. Sitting in the pilot seat of the Marine One circa 1963
I didn't take it as a compliment.
How beautiful is this
Hustle like Faye
The power of a salt water crocodile's tail.
I'm 36, and will be dead inside of a year.
F***ing genius.
TIL Anthony Daniels, who endured years of discomfort in the C-3PO costume, was so annoyed by Alan Tudyk (Rogue One) playing K-2SO in the comfort of a motion-capture suit that he cursed at Tudyk. Tudyk later joked that a "fuck you" from Daniels was among the highest compliments he had ever received.
Reminder about the fact UC Davis paid over $100k to remove this photo from the internet.
King of the Hill reruns will start airing on Comedy Central July 24th
[Image] Slow and steady
White House: Trump open to Russia questioning US citizens
Godzilla: King of the Monsters Teaser Banner
He tried
Soldier reunited with his dog after being away.
Hiring a hitman on yourself and preparing for battle is the ultimate extreme sport.
Two paintballs colliding midair
My thoughts & prayers are with those ears
When even your fantasy starts dropping hints
Elon Musk's apology is out
"When you're going private so you plant trees to throw some last shade at TDNW before you vanish." Thanos' farm advances. The soul children will have full bellies. 1024 points will give him the resources to double, and irrigate, his farm. (See comment)
Some leaders prefer chess, others prefer hungry hippos. Travis Chapman, oil, 2018
The S.S. Ste. Claire, retired from ferrying amusement park goers, now ferries The Damned across the river Styx.
A soldier is reunited with his dog
*hits blunt*
Today I Learned
Black Panther Scene Representing the Pan-African Flag
The precision of this hydraulic press.
Let bring the game to another level
When you're fighting a Dark Souls boss and you gamble to get 'just one extra hit' in instead of rolling out of range.
"I check for traps"
Anon finds his home at last
He’s hungry
Being a single mother is a thankless job.
TIL That when you're pulling out Minigun, you're actually pulling out suitcase that then transforms into Minigun.
OMG guys don’t look!!! 🙈🙈🙈
hyubsama's emote of his own face denied for political reasons because twitch thinks its a picture of Kim Jong Un
#Nodejs #WebDev #JavaScript #HTML #node-js