It’s one of the most simple and basic models of machine learning, which can be used both for classification and regression. Let’s dive into the understanding of the decision tree, in our familiar question and answer style. We also have a video lecture for the theory here and hands-on using python here.
What are the components of a decision tree?
The basic constituents are
a**) Root Node:** This will typically have the entire training data available in the node. Data from all classes will be intermixed.
b)** Decision Nodes: **Typically it will have a format like Attribute ‘A’ some condition ‘k’. For example Age > 30, which creates two further nodes.
c) **Internal node and Terminal Node: **The internal nodes are the result of decision nodes, if they are pure enough they can be Terminal nodes, else they are internal nodes, which will need to go through again decision nodes._ The decision node can clearly tell us, what an unknown observation will be labeled if they land at that node._
Let’s illustrate with a very simple example, let’s say we have 10 student’s data, their scores in Verbal ability and Maths. The students are categorized into there classes based on the placement success of the students. The three classes are Placed Immediately (PI), Placed After some-time (PA), Unplaced (U) respectively.
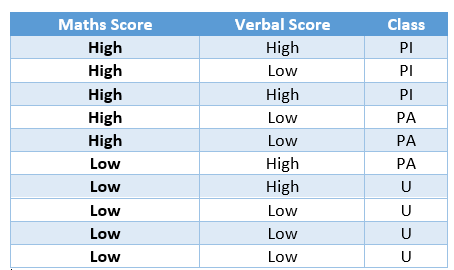
Figure 1: Sample Student Placement Data ( Source: Author)
When a decision tree, it will have a structure as below, for the above data. The tree has one root node, two decision nodes ( Maths = High, English = High), and three-terminal nodes corresponding to the three classes.
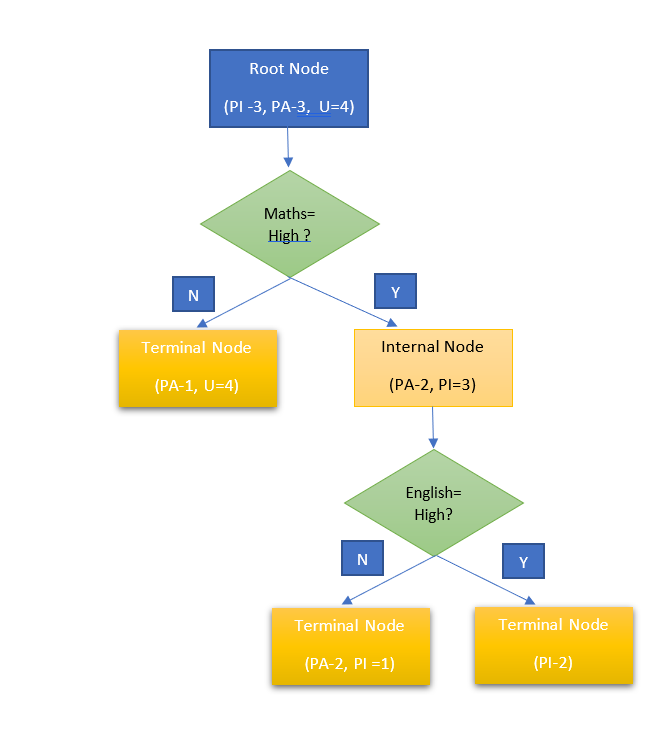
Figure 2: Decision Tree on the Student Placement Data
Observations:
- The root node is very mixed as far as classes are concerned, as we move to terminal nodes the nodes are having a more homogeneous population ( Maximum of 2 classes and 1 class is the majority).
- Now, if we have a student Sam and we know that he scores high in both Maths and English, following the decision tree, we know, his chance of being placed immediately is very high.
So, a moot point is we want to move towards the more homogeneous terminal nodes. This necessitates defining a measure of homogeneity or the lack of it.
How do we formally measure homogeneity or heterogeneity of a node?
This needs an introduction to a concept called Entropy.
Entropy:
It is a measure of the uncertainty that is present in a random variable. The root nodes have a mix from all classes, so if we randomly pick one, the uncertainty is highest in the root node and we move towards the terminal node this uncertainty gradually decreases. We call this_ information gain_.
We do understand, by now, entropy will be a function of the probability.
#decision-tree #classification #entropy #algorithms #machine-learning #deep learning
