Topic modeling is an unsupervised learning approach to document clustering based on the topics of their content.
In this article, we will create a model using a topic modeling technique called Non-Negative Matrix Factorization (NMF) to infer the main themes existing in a dataset of hotel reviews, analyze how accurate this classification is across all documents, and predict the topic of a new document with our trained model.
Introduction to Topic Modeling
In this domain, a topic refers to a collection of terms that are frequently used in combination with documents of the same theme. Therefore, topic modeling key outputs are: a list of topics and the list of documents that are correlated with each topic.
Topic modeling has several practical applications in NLP, such as for example:
- Deciding the conversation subject for Chatbots.
- Detecting similar user opinions for a given topic.
- Inferring hidden topics within a set of documents.
- Clustering customer feedback.
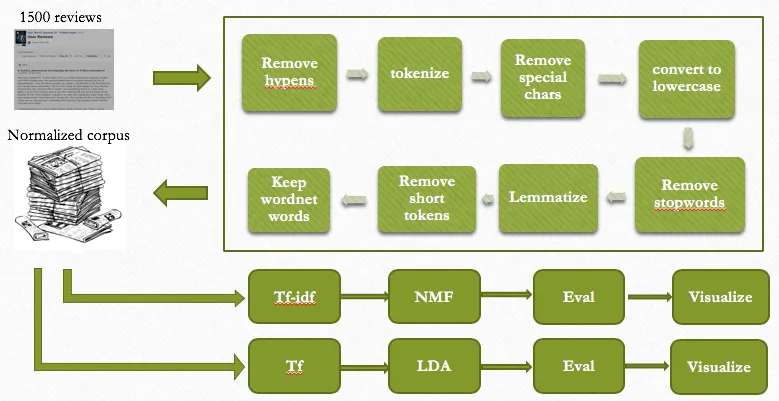
Data pre-processing
For this article, we will be using this dataset available in Kaggle that contains 515k customer reviews in English rating their experience in hotels across Europe.
import pandas as pd
df = pd.read_csv('data/Hotel_Reviews.csv')
## Join positive and negative review
df["Review"] = df["Negative_Review"] + " " + df["Positive_Review"]
## Keep only relevant columns
df = df[['Review']]
#nlp-tutorial #data-science #nlp #machine-learning #topic-modeling