Introduction
SQL Server Always On is a disaster and high availability feature. In the previous articles, we explored the following features.
- AG failover in case of primary replica goes down
- Manual failover
- Database level health detection that initiates a failover in case any AG database changes its state from online and SQL Server not able to write in the transaction log
In the above points, we safeguard SQL Server for the instance and DB failover. Suppose your AG replica is healthy, but one of your AG databases becomes corrupt. You get a logical consistency error if you execute the DBCC CHECKDB command. You might have an excellent copy of that database page in another participating replica. Let’s find the answer to a few questions in this article.
- How does SQL Server Always On help us to recover the corrupt page in this scenario?
- What happens if a page corrupts in the AG database on the primary replica?
Prerequisites
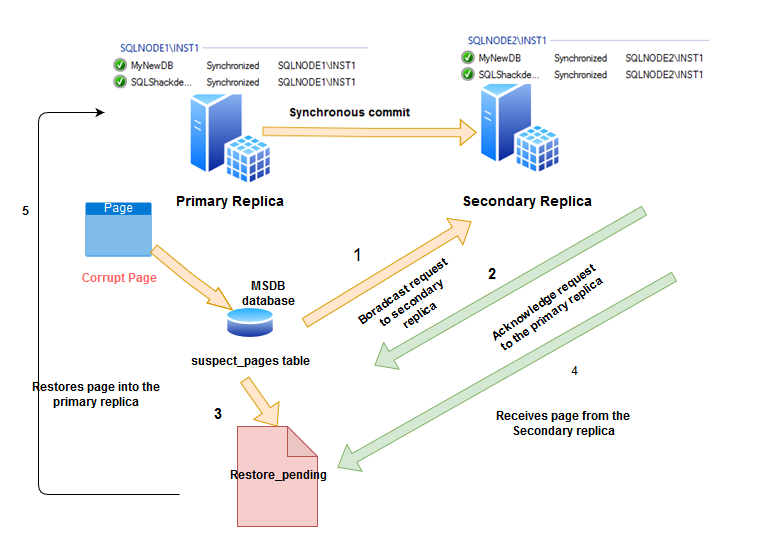
You can follow the series articles and prepare a two-node SQL Server Always On Availability Group, as shown below.
- Current Primary replica: SQLNode1\INST1
- Current Secondary replica: SQLNode2\INST1
- AG Mode: Synchronous commit
Automatic Page Repair in SQL Server Always On Availability Groups
SQL Server supports automatic page repair for the databases participating in AG configuration. If SQL detects specific corruption errors (Error id 823,824 & 829) for an AG database, SQL Server tries to restore the page from the corresponding replica(primary or secondary).
It works for the following consistency errors.
- Error 823: We get this error if the operating system performs a cyclic redundancy check that failed on the data
- Error 824: Logical consistency errors such as bad page checksum, torn page detection
- Error 829: SQL Server raises error 829 if a page is marked as restore pending
Resolve a page corruption issues on the Primary replica in SQL Server Always On Availability Groups
Let us consider that my AG database is in the synchronized state and communicating with the secondary replica. Now, you get the IO error in an AG database on the primary replica. The below diagram shows the high-level steps for the automatic page repair if any page corrupts at the primary replica.
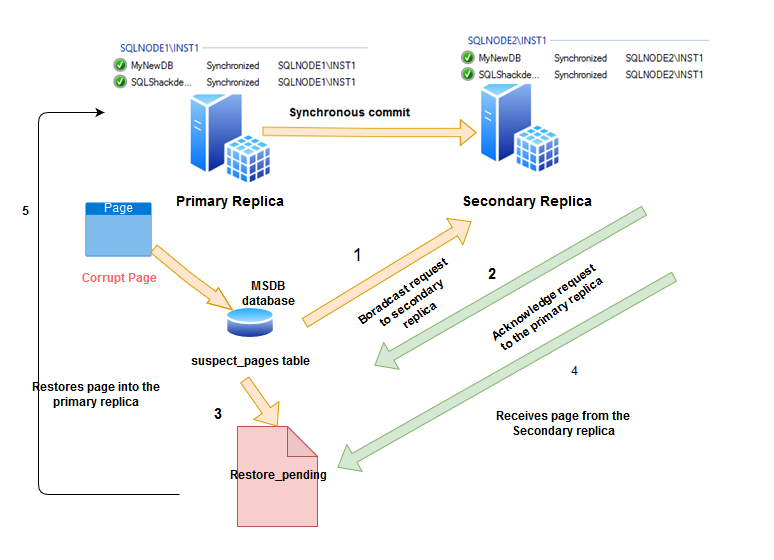
- It inserts a row in the [suspect_pages](https://docs.microsoft.com/en-us/sql/relational-databases/system-tables/suspect-pages-transact-sql?view=sql-server-ver15) table in the MSDB system database. This table logs the corruption information such as the database id, file id, page id, error id
- It broadcasts a request to all secondary replica
- It might get a response from the multiple secondary replicas. It gets the page from the replica that responds first. This request also specifies the page ID and LSN that is currently at the end of the log
- SQL Server marks the specified page as restore pending. If any user tries to access the page status restore pending, he gets error 829
- Once the secondary replica receives a page request, it waits until it has redone the log up to the LSN primary replica specified in the request
- Secondary replica access the required page and sends it to the primary replica. If the secondary replica could not access the page, it returns an error to the primary replica. It causes the failure of automatic page repair
- If the automatic page repair is successful, it marks the status of the page in the suspect_pages table as restored (event_type 5)
- SQL Server tries to resolve the deferred transactions after the successful page repair
Let’s simulate the automatic page repair in the SQL Server Always On Availability Group
#alwayson availability groups #sql