These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / **Next LectureWelcome back to deep learning and you can see in the video, I have a couple of upgrades. We have a much better recording quality now and I hope you can also see that I finally fixed the sound problem. You should be able to hear me much better right now. We are back for a new session and we want to talk about a couple of exciting topics. So, let’s see what I’ve got for you. So today I want to start discussing different architectures. In particular, in the first couple of videos, I want to talk a bit about the early architectures. the things that we’ve seen in the very early days of deep learning. We will follow then by looking into deeper models in later videos and in the end we want to talk about learning architectures.

To test architectures more quickly, smaller data set can be employed. Image under [CC BY 4.0] from the [Deep Learning Lecture]
A lot of what we’ll see in the next couple of slides and videos have of course being developed for image recognition and object detection tasks. In particular two data sets are very important for these kinds of tasks. This is the ImageNet data set which you find in [11]. It has something like a thousand classes and more than 14 million images. Subsets have been used for the ImageNet large-scale visual recognition challenges. It contains natural images of varying sizes. So, a lot of these images have actually been downloaded from the internet. There are also smaller data sets if you don’t want to train with like millions of images right away. So, they are also very important. CIFAR 10 and CIFAR 100 have 10 and 100 classes respectively. In both, we only have 50k training and 10k testing images. The images have reduced size: 32 x 32 in order to very quickly be able to explore different architectures. If you have these smaller data sets then it also doesn’t take so long for training. So this is also a very common data set if you want to evaluate your architecture.
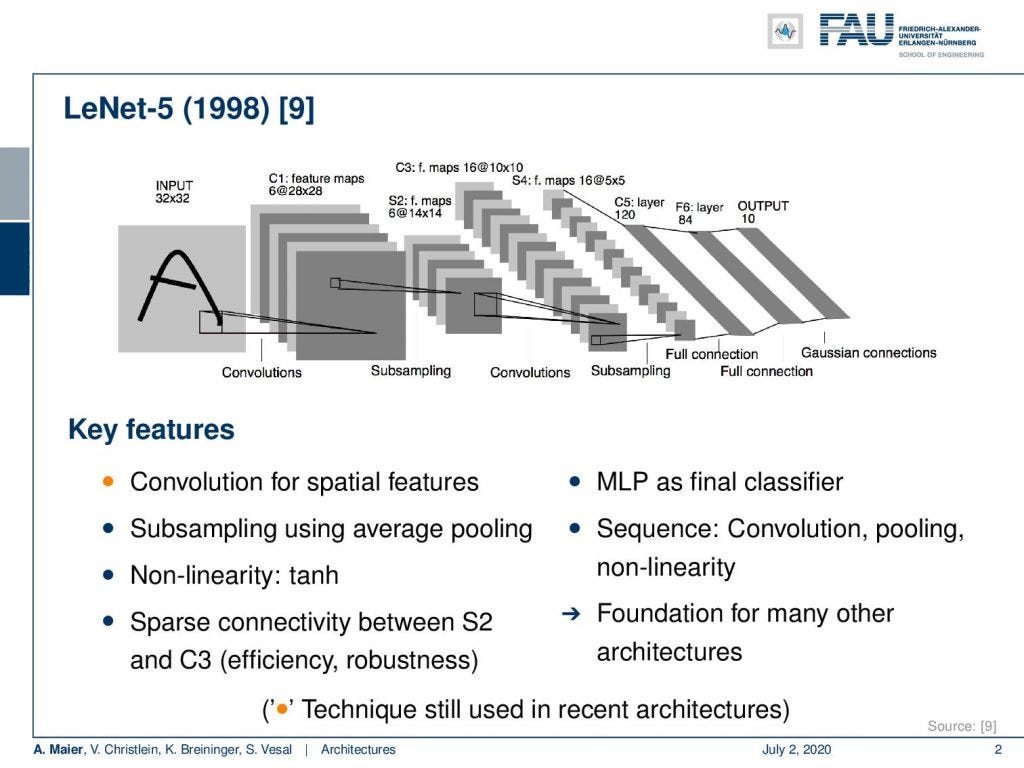
LeNet by Yann LeCun is a milestone architecture in the short history of deep learning from the [Deep Learning Lecture]
Based on these different data sets, we then want to go ahead and look into the early architectures. I think one of the most important ones is LeNet which was published in 1998 in [9]. You can see this is essentially the convolutional neural network (CNN) that we have been discussing so far. It has been used for example for letter recognition. We have the convolutional layers that have trainable kernels and pooling, another set of convolutional layers, and another pooling operation, and then towards the end, we are going into fully connected layers. Hence, we gradually reduce dimensionality and at the very end, we have the output layer that corresponds to the number of classes. This is a very typical CNN type of architecture and this kind of approach has been used in many papers. This has inspired a lot of work. We have for every architecture here key features and you can see, here, most of the bullets are in gray. That means that most of these features did not survive. Of course, what survived here was convolution for spatial features. This is the main idea that is still prevalent. All the other things like subsampling using average pooling did not take the test of time. It still used as non-linearity the hyperbolic tangent. So, it’s a not-so-deep model, right? Then, it had sparse connectivity between S2 and C3 layers, as you see here in the figure. So also not that common anymore is the multi-layer perceptron as the final classifier. This is something that we see no longer because it has been replaced by for example fully convolutional networks. This is a much more flexible approach and also the sequence of convolution pooling and non-linearity is kind of fixed. Today, we will do that in a much better way but of course, this architecture is fundamental for many of the further developments. So, I think it’s really important that we are also listing it here.

#fau-lecture-notes #machine-learning #deep-learning #artificial-intelligence #data-science #deep learning
