Introduction
K-means is one of the most widely used unsupervised clustering methods.
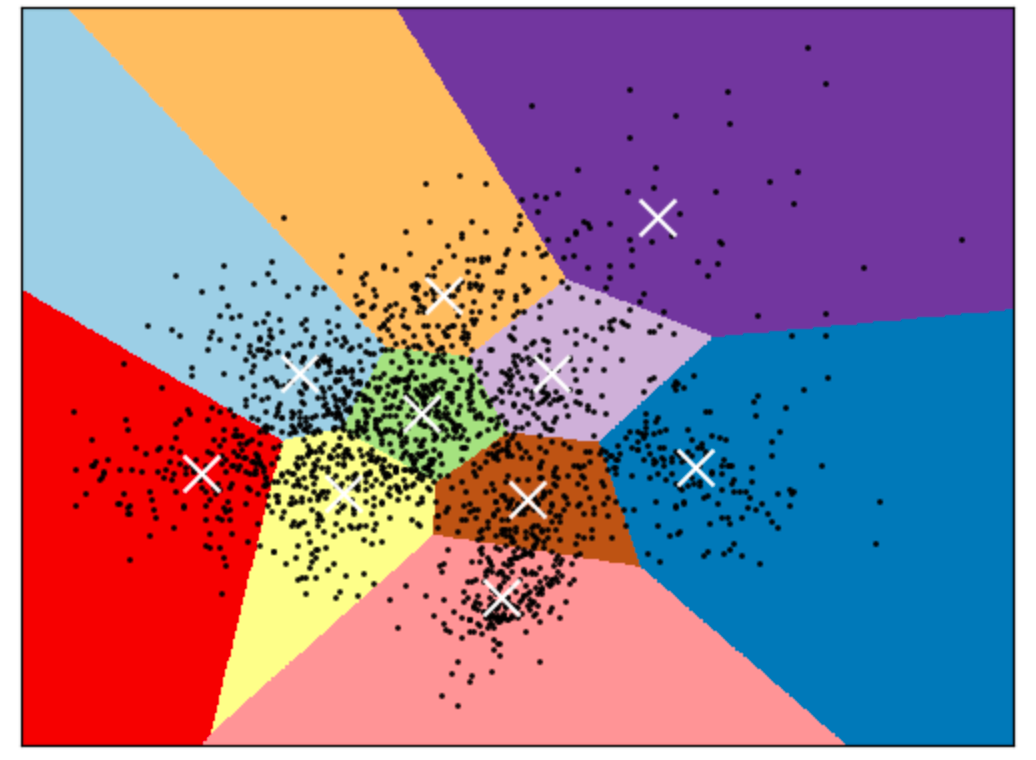
The **K-means **algorithm clusters the data at hand by trying to separate samples into K groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares. This algorithm requires the number of clusters to be specified. It scales well to large number of samples and has been used across a large range of application areas in many different fields.
The k-means algorithm divides a set of **N **samples (stored in a data matrix X) into K disjoint clusters C, each described by the mean **μj**of the samples in the cluster. The means are commonly called the cluster “centroids”.
**K-means **algorithm falls into the family of unsupervised machine learning algorithms/methods. For this family of models, the research needs to have at hand a dataset with some observations without the need of having also the labels/classes of the observations. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabeled data.
Now let’s discover the mathematical foundations of the algorithm.
#artificial-intelligence #clustering #data-science #cluster-analysis #machine-learning