MyScale:用于可扩展数据处理的 Python 客户端
MyScale 是一个 Python 客户端,允许您在分布式集群上运行数据处理任务。在本教程中了解如何安装、配置和使用 MyScale。
什么是 MyScale?
MyScale (打开新窗口) 是一个基于云的 SQL 矢量数据库,专门设计和优化,用于管理 AI 应用程序的大量数据。它构建于ClickHouse(打开一个新窗口)(SQL 数据库)之上,将矢量相似性搜索功能与完整 SQL 相结合支持。在单个界面中,SQL 查询可以同时快速地利用不同的数据模式来处理复杂的 AI 需求,否则需要更多的步骤和时间。
与专门的矢量数据库不同,MyScale 将矢量搜索算法与结构化数据库和谐地结合在一起,从而可以在同一数据库中管理矢量和结构化数据。这种集成带来的好处包括简化的通信、适应性强的元数据过滤、对 SQL 和向量联合查询的支持,以及与通常与多功能通用数据库相关的成熟工具的兼容性。从本质上讲,MyScale 提供了一个统一的解决方案,提供了一种全面、高效且易于学习的方法来解决 AI 数据管理的复杂性。
如何在 MyScale 中启动集群
在开始在项目中使用 MyScale 之前,您需要做的第一件事是创建一个帐户并创建一个用于存储数据的集群。下面我们向您展示步骤:
- 登录/注册 MyScale 帐户myscale.com(打开新窗口)
- 创建帐户后,单击“+ New Cluster”页面右侧的按钮
- 输入集群的名称,然后按“下一步”按钮
- 等待集群创建;这需要几秒钟
创建集群后,您将看到文本“集群启动成功”。在弹出按钮上。
笔记:
创建集群后,如果您没有自己的数据,您还可以选择将现成的示例数据导入到集群中。但是,在本教程中,我们将加载我们自己的数据。
现在,下一步是设置工作环境并访问正在运行的集群。让我们这样做吧。
设置环境
要在您的环境中使用 MyScale,您需要:
- Python:MyScale 提供了一个用于与数据库交互的 Python 客户端库,因此您需要在系统上安装 Python。如果您的电脑上没有安装 Python,您可以从Python 官方网站(打开一个新窗口)下载它.
- MyScale Python 客户端:使用 ClickHouse 客户端(打开新窗口) 安装包>pip:
pip install clickhouse-connect执行完成后,可以输入以下命令确认安装:
pip show clickhouse-connect如果安装了该库,您将看到有关该包的信息;否则,您会看到错误。
与集群的连接
下一步是将 Python 应用程序与集群连接,为了连接,我们需要以下详细信息:
- 集群主机
- 用户名
- 密码
要获取详细信息,您可以返回 MyScale 配置文件,将鼠标悬停在“操作”下方的三个垂直对齐的点上。文本,然后单击连接详细信息。
单击“连接详细信息”后,您将看到以下框:
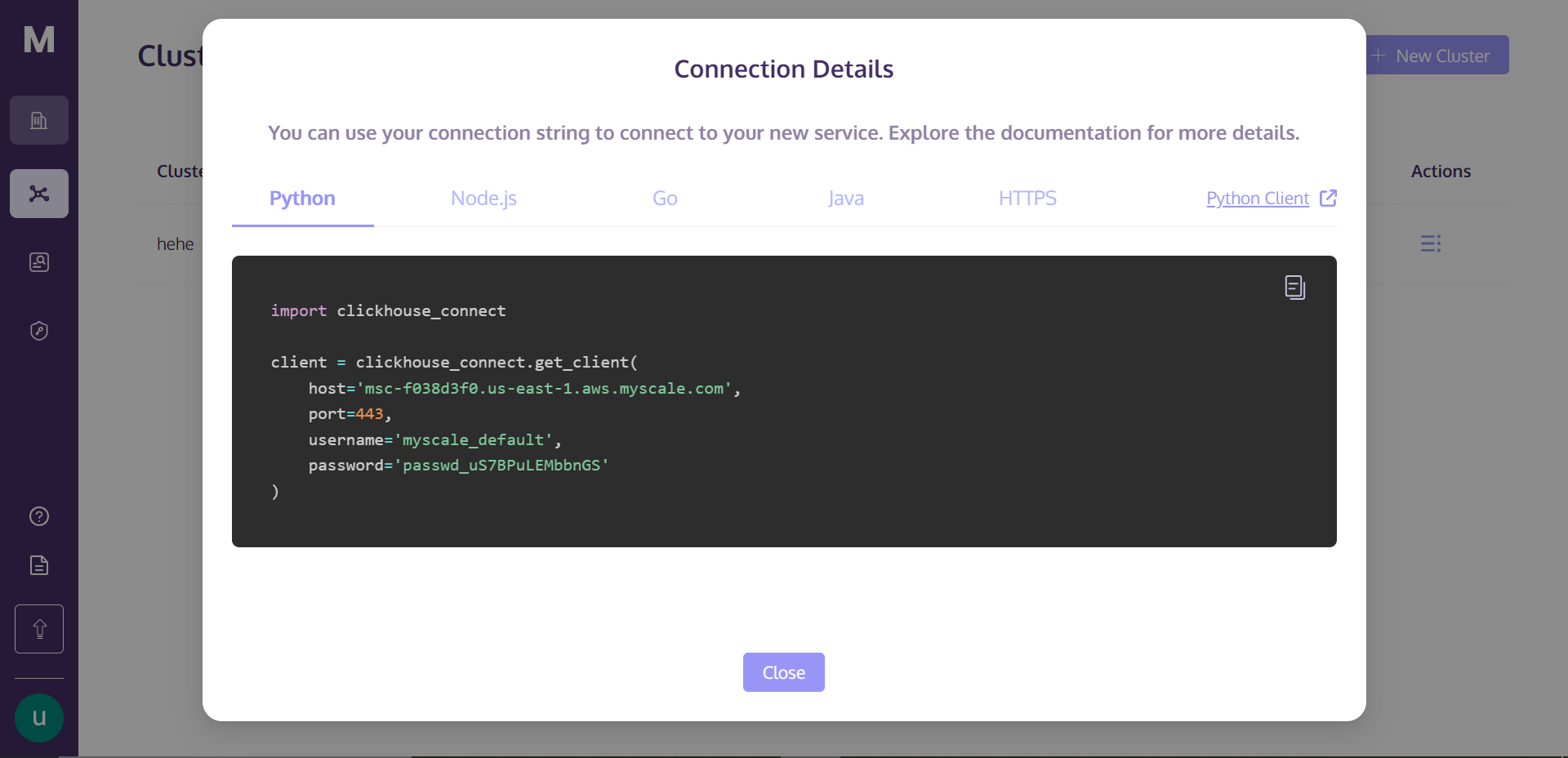
这些是连接到集群所需的连接详细信息。只需在目录中创建一个 Python 笔记本文件,将以下代码复制粘贴到笔记本单元中,然后运行该单元。它将与您的集群建立连接。
创建数据库
下一步是在集群上创建数据库。让我们看看如何做到这一点:
client.command("""
CREATE DATABASE IF NOT EXISTS getStart;
"""该命令首先检查同名数据库是否存在。如果没有,它将创建一个名为 getStart 的数据库。
使用 MyScale 创建表
在MyScale中创建表的基本语法如下:
CREATE TABLE [IF NOT EXISTS] db_name.table_name
(
column_name1 data_type [options],
column_name2 data_type [options],
...
)
ENGINE = engine_type
[ORDER BY expression]
[PRIMARY KEY expression];在上面的语法中,您可以根据您的选择替换 db_name 和 table_name。在括号内,您可以定义表的列。每列(column_name1、column_name2 等)均使用其各自的数据类型 (data_type) 进行定义,并且您可以选择包括附加列选项([options]),例如默认值或约束。
注意:我们只是看看如何在 MyScale 中创建表。我们将在下一步中根据我们的数据创建一个实际的表。
ENGINE = engine_type 子句对于确定数据存储和处理至关重要。您可以指定 ORDER BY expression,它确定数据在表中的物理存储方式。这个PRIMARY KEY expression是用来提高数据检索的效率的。与传统的 SQL 数据库不同,ClickHouse 中的主键并不强制唯一性,而是用作性能优化工具来加速查询处理。
导入表数据并创建索引
让我们通过导入数据集来获得实践经验,然后您将学习根据数据集创建列。
import pandas as pd
# URL of the data
url = 'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv'
# Reading the data directly into a pandas DataFrame
data = pd.read_csv(url)这应该从提供的 URL 下载数据集并将其保存为数据框。数据应如下所示:
| id | data | date | label |
|-------|---------------------------------------------------|------------|----------|
| 0 | [0,0,1,8,7,3,2,5,0,0,3,5,7,11,31,13,0,0,0,... | 2030-09-26 | person |
| 1 | [65,35,8,0,0,0,1,63,48,27,31,19,16,34,96,114,3... | 1996-06-22 | building |
| 2 | [0,0,0,0,0,0,0,4,1,15,0,0,0,0,49,27,0,0,0,... | 1975-10-07 | animal |
| 3 | [3,9,45,22,28,11,4,3,77,10,4,1,1,4,3,11,23,0,... | 2024-08-11 | animal |
| 4 | [6,4,3,7,80,122,62,19,2,0,0,0,32,60,10,19,4,0,... | 1970-01-31 | animal |
| ... | ... | ... | ... |
| 99995 | [9,69,14,0,0,0,1,24,109,33,2,0,1,6,13,12,41,... | 1990-06-24 | animal |
| 99996 | [29,31,1,1,0,0,2,8,8,3,2,19,19,41,20,8,5,0,0,6... | 1987-04-11 | person |
| 99997 | [0,1,116,99,2,0,0,0,0,2,97,117,6,0,5,2,101,86,... | 2012-12-15 | person |
| 99998 | [0,20,120,67,76,12,0,0,8,63,120,55,12,0,0,0,... | 1999-03-05 | building |
| 99999 | [48,124,18,0,0,1,6,13,14,70,78,3,0,0,9,15,49,4... | 1972-04-20 | building |下一步是在 MyScale 集群上创建一个实际的表并存储该数据。让我们这样做吧。
client.command("""
CREATE TABLE getStart.First_Table (
id UInt32,
data Array(Float32),
date Date,
label String,
CONSTRAINT check_data_length CHECK length(data) = 128
) ENGINE = MergeTree()
ORDER BY id
"""上述命令将创建一个名为First_Table的表。此处还给出了具有数据类型的列名称。选择约束的原因是我们希望数据列的向量完全相同,因为在后面的部分中,我们将对该列应用向量搜索。
将数据插入到定义的表中
创建表过程之后,下一步是将数据插入表中。因此,我们将插入之前下载的数据。
# Convert the data vectors to float, so that it can meet the defined datatype of the column
data['data'] = data['data'].apply(lambda x: [float(i) for i in ast.literal_eval(x)])
# Convert the 'date' column to the 'YYYY-MM-DD' string format
data['date'] = pd.to_datetime(data['date']).dt.date
# Define batch size and insert data in batches
batch_size = 1000 # Adjust based on your needs
num_batches = len(data) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = data[start_idx:end_idx]
client.insert("getStart.First_Table", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")上面的代码根据定义的表更改了某些列的数据类型。由于数据量较大,我们是以批量的形式插入数据。因此,我们正在创建批次1000。
创建向量索引
因此,下一步是创建向量索引。让我们看看它是如何完成的。
client.command("""
ALTER TABLE getStart.First_Table
ADD VECTOR INDEX vector_index data
TYPE MSTG
""")注意:创建向量索引的时间取决于表中的数据。
MSTG向量索引由MyScale内部创建,在速度、准确性和成本效率方面大幅超越竞争对手。
要检查向量索引是否已成功创建,我们将尝试以下命令:
get_index_status="SELECT status FROM system.vector_indices WHERE table='First_Table'"
print(f"The status of the index is {client.command(get_index_status)}")代码的输出必须是“索引的状态已构建”。 “建造”一词是指“建造”。表示索引已启动并创建成功。
注意:目前,MyScale 只允许为每个表创建一个索引。但将来,您将能够在一个表中创建多个索引。
使用 Myscale 编写不同类型的 SQL 查询
MyScale 允许您编写不同类型的查询,从基础到复杂。让我们从一个非常基本的查询开始。
result=client.query("SELECT * FROM getStart.First_Table ORDER BY date DESC LIMIT 1")
for row in result.named_results():
print(row["id"], row["date"], row["label"],row["data"])您还可以使用向量的相似度分数找到实体的最近邻居。让我们获取提取的结果并获取其最近的邻居:
results = client.query(f"""
SELECT id, date, label,
distance(data, {result.first_item["data"]}) as dist FROM getStart.First_Table ORDER BY dist LIMIT 10
""")
for row in results.named_results():
print(row["id"], row["date"], row["label"])注意:first_item 方法为我们提供结果数组中的第一个元素。
这应该打印给定条目的前 10 个最近邻居。
使用 MyScale 编写自然语言查询
您还可以使用自然语言查询来查询 MyScale,但为此,我们将使用具有神经网络功能的新数据创建另一个表。
在创建表之前,我们先加载数据。原始文件可在此处下载(打开新窗口)。
with open('/`../../modules/state_of_the_union.txt`', 'r', encoding='utf-8') as f:
texts = [line.strip() for line in f if line.strip()] 此命令将加载文本文件并将其拆分为单独的文档。为了将这些文本文档转换为向量嵌入,我们将使用 OpenAI API。要安装它,请打开终端并输入以下命令:
pip install openai安装完成后,您可以设置嵌入模型并获取嵌入:
import os
# Import OPENAI
import openai
# Import pandas
import pandas as pd
# Set the environment variable for OPENAI API Key
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
# Get the embedding vectors of the documents
response = openai.embeddings.create(
input = texts,
model = 'text-embedding-ada-002')
# The code below creates a dataframe. We will insert this dataframe directly to the table
embeddings_data = []
for i in range(len(response.data)):
embeddings_data.append({'id': i, 'data': response.data[i].embedding, 'content': texts[i]})
# Convert to Pandas DataFrame
df_embeddings = pd.DataFrame(embeddings_data)上面的代码将文本文档转换为嵌入,然后创建一个将插入到表中的数据框。现在,让我们继续创建表。
client.command("""
CREATE TABLE getStart.natural_language (
id UInt32,
content String,
data Array(Float32),
CONSTRAINT check_data_length CHECK length(data) = 1536
) ENGINE = MergeTree()
ORDER BY id;
"""下一步是将数据插入表中。
# Set the batch size to 20
batch_size = 20
# Find the number of batches
num_batches = len(df_embeddings) // batch_size
# Insert the data in the form of batches
for i in range(num_batches + 1):
# Define the starting point for each batch
start_idx = i * batch_size
# Define the last index for each batch
end_idx = min(start_idx + batch_size, len(df_embeddings))
# Get the batch from the main DataFrame
batch_data = df_embeddings[start_idx:end_idx]
# Insert the data
if not batch_data.empty:
client.insert("getStart.natural_language",
batch_data.to_records(index=False).tolist(),
column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches + 1} inserted.")数据插入过程可能需要一些时间,具体取决于数据的大小,但您可以这样监控进度。现在,让我们继续为表创建索引。
client.command("""
ALTER TABLE getStart.natural_language
ADD VECTOR INDEX vector_index_new data
TYPE MSTG
""")创建索引后,您就可以开始进行查询了。
# Convert the query to vector embeddigs
response = openai.embeddings.create(
# Write your query in the input parameter
input = 'What did the president say about Ketanji Brown Jackson?',
model = 'text-embedding-ada-002'
)
# Get the results
results = client.query(f"""
SELECT id,content,
distance(data, {list(response.data[0].embedding)}) as dist FROM getStart.natural_language ORDER BY dist LIMIT 5
""")
for row in results.named_results():
print(row["id"] ,row["content"], row["dist"])它应该打印以下结果:
| ID | Text | Score |
| --- | ---------------------------------------------------------------------------------------------------------------- | ------------------- |
| 269 | And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson... | 0.33893799781799316 |
| 331 | The Cancer Moonshot that President Obama asked me to lead six years ago. | 0.4131550192832947 |
| 80 | Vice President Harris and I ran for office with a new economic vision for America. | 0.4235861897468567 |
| 328 | This is personal to me and Jill, to Kamala, and to so many of you. | 0.42732131481170654 |
| 0 | Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet... | 0.427462637424469 |这些只是查询的几个示例;您可以根据自己的需求和项目编写任意数量的复杂查询。
MyScale 在 SQL 矢量数据库领域处于领先地位
MyScale 以无与伦比的准确性、性能在 SQL 矢量数据库市场中脱颖而出,。它优于其他集成矢量数据库(如 pgvector)和专用矢量数据库(如 Pinecone),以更低的成本实现更好的搜索精度和更快的查询处理。除了性能之外,SQL 界面对于开发人员来说也是高度用户友好的,以最少的必要学习提供最大的价值。成本效率和
MyScale 确实提升了游戏的性能。这不仅仅是为了更好地通过向量进行搜索;它在涉及复杂元数据过滤器的场景中提供高精度和每秒查询次数 (QPS)。另外,最重要的是:如果您注册,您就可以免费使用 S1 pod,它最多可以处理 500 万个向量。对于需要功能强大且经济高效的矢量数据库解决方案的任何人来说,它都是首选。
MyScale 通过 AI 集成为应用程序提供支持
MyScale 增强了其功能,并允许您通过与 AI 技术集成来创建更强大的应用程序。让我们看看其中一些可以改进 MyScale 应用程序的集成。
与浪链集成
在当今世界,人工智能应用程序的用例日益增加,您无法仅通过将法学硕士与数据库相结合来创建强大的人工智能应用程序。您将必须使用不同的框架和工具来开发更好的应用程序。在这方面,MyScale 提供了与 LangChain 的完整集成(opens a new window),让您能够通过先进的检索策略创建更有效、更可靠的 AI 应用。 MyScale 自查询检索器(打开新窗口) 实现了一种灵活而强大的方法,可将文本转换为经过元数据过滤的矢量查询,从而实现高精度许多现实世界的场景。
与 OpenAI 集成
通过将 MyScale 与 OpenAI 集成,您可以显着提高 AI 应用程序的准确性和稳健性。 OpenAI 允许您获得最佳的嵌入向量,同时保留上下文和语义。当您使用自然语言查询应用矢量搜索或从数据中提取嵌入时,这一点非常重要。这就是提高应用程序精度和准确度的方法。如需更详细的了解,您可以阅读我们的与 OpenAI 集成(打开新窗口)文档。
最近,OpenAI 发布了 GPT,让开发者可以轻松定制 GPT 和聊天机器人。 MyScale 适应了这种转变,通过将服务器端上下文无缝注入 GPT 模型来改变 RAG 系统开发。 MyScale 通过 SQL WHERE 子句通过结构化数据过滤和语义搜索简化上下文注入,经济高效地优化知识库存储并实现跨 GPT 共享。欢迎您在 GPT 商店中尝试MyScaleGPT(打开新窗口)或将您的知识库挂接到 GPT 中使用 MyScale(打开新窗口。
