Deep learning is not always the answer to a big data problem
Often times in the workplace, business stakeholders and managers associate machine learning and big data with deep learning. They will often think that the best solution to all data problems is deep learning, AI or neural networks or some combination of the prior (insert your favourite buzzword). As someone with a statistics background, I find this view quite frustrating as the type of machine learning algorithm chosen should be based upon five key considerations:
5 Key Considerations when selecting a machine learning algorithm
- Type of data problem — i.e. supervised vs unsupervised
- The variable types within the dataset — i.e. categorical or numerical
- The validation of underlying assumptions of the statistical model
- The resulting model accuracy
- The balance between precision vs. recall and sensitivity vs. specificity (for classification)
In the next few sections and over a couple of blog posts, I am going to go through the different types of models for supervised learning and apply the above considerations to each one.
Supervised learning
Most of the time, data problems require the application of supervised learning. This is when you know exactly what you want to predict — the target or dependent variable, and have a set of _independent _or _predictor _variables that you want to better understand in terms of their influence on the target variable. Then, the selection of a model is based on mapping the underlying pattern in the data to a function which is dependent upon the data’s distribution and variable types.
The name “supervised learning” is used to describe these types of models because the model learns the underlying pattern on a training set. The number of iterations/rounds determines the number of times the model has a chance to learn from its past. In each subsequent round, the model tries to improve on model accuracy (accuracy metric selected by user) based on what it has learnt in previous runs. The model stops running either after its maximum number of runs has been achieved or when it can no longer improve the model accuracy (specified by early stopping in some models).
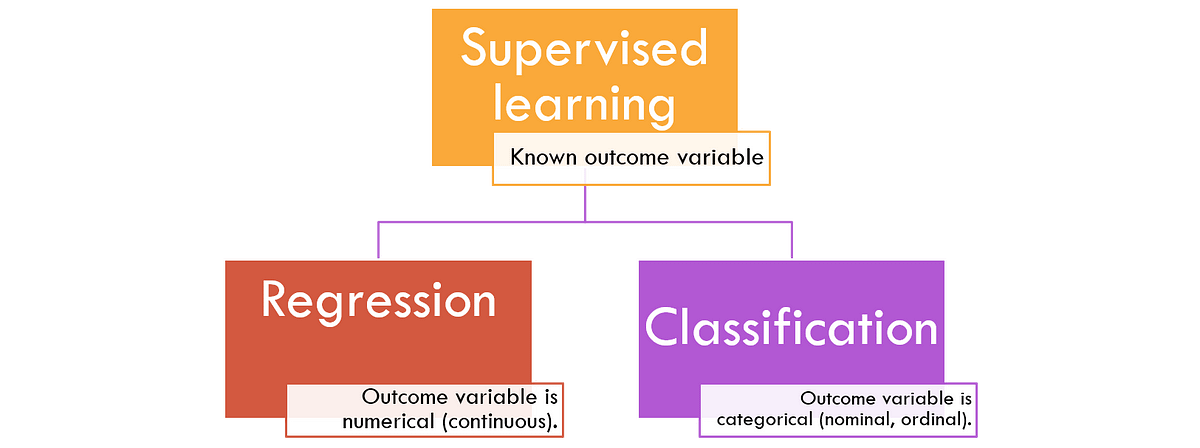
There are two types of supervised learning algorithms as shown in the figure below where the type of outcome variable determines whether you select regression or classification.
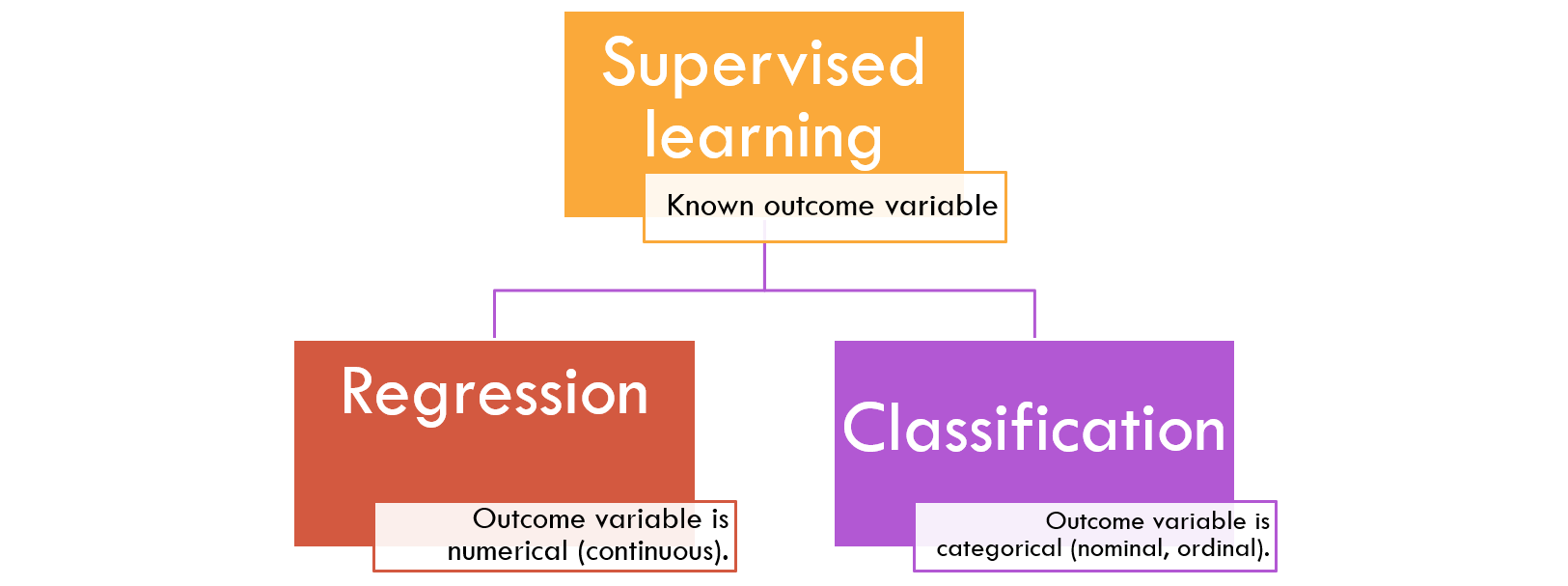
Figure 1: Types of supervised learning models
#supervised-learning #regression-analysis #r-programming #machine-learning #regression