Walk Through Recommender System of Advanced Matrix Factorization for implicit dataset

Photo by freepik.com
The implicit dataset provides users’ behavior data such as purchase history, watching habits, and browsing activity. Unlike explicit feedback from users rating data, the implicit dataset is lack of direct indication of their preferences. Therefore, it’s hard to know which products customers dislike. The model we work below generates unique properties of implicit feedback datasets. The confidence level is varied from positive and negative preferences.
In this article, you will learn the algorithm of advanced matrix factorization of the recommender system:
(1) Introduction to Neighborhood models
(2) Introduction to Latent factor models
(3) Introduction to Model for Implicit Feedback
(4) Hands-on experience of python code on matrix factorization
Introduction to Neighborhood models
The neighborhood model is a common approach among the Collaborative Filtering algorithm. Such an approach is to recommend users with the same interest based on the history dataset. Better scalability and improved accuracy make the item-oriented approach more favorable in many cases. In those methods, a rating is estimated using known ratings made by the same user on similar items. Better scalability and improved accuracy make the item-oriented approach more favorable in many cases. The item-oriented approach is more favorable to users since they are familiar with items previously preferred by them, and the recommended items are based on same-interest users.
A similarity measure is applied for the neighborhood model where s_ij denotes the similarity of i and j, and is calculated by the Pearson correlation coefficient. The goal is to predict r_ui — the unobserved value by user u for item i. S^k(i;u) is denoted by a set of k neighbors and the predicted value of r_ui is taken as a weighted average of the ratings for neighboring items.
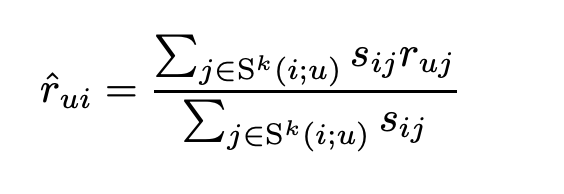
A similarity measure
Introduction to Latent factor models
The latent factor model is an alternative Collaborative Filtering approach to uncover latent features that explain observed ratings. Singular Value Decomposition (SVD) is the main algorithm introduced for the latent factor model. The SVD model becomes a popular user-item observation method.
An SVD model is comprised of a user-factors vector X_u and item-factors vector Y_i. The prediction is generated by the inner product r^ui = X^T_u*Y_i. λ is the parameter for regularization.
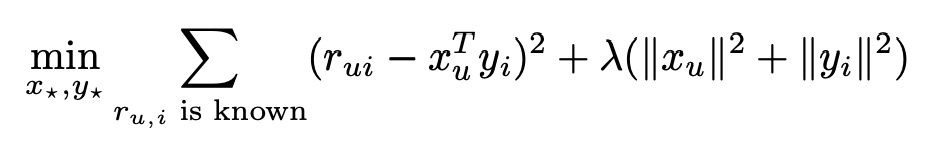
#tensorflow #matrix-factorization #machine #recommendation-system #python
