This blog post demonstrates how you can use Change Data Capture to stream database modifications from PostgreSQL to Azure Data Explorer (Kusto) using Apache Kafka.
Change Data Capture (CDC) can be used to track row-level changes in database tables in response to create, update and delete operations. It is a powerful technique, but useful only when there is a way to leverage these events and make them available to other services.
Introduction
Using Apache Kafka, it is possible to convert traditional batched ETL processes into real-time, streaming mode. You can do-it-yourself (DIY) and write good old Kafka producer/consumer using a client SDK of your choice. But why would you do that when you’ve Kafka Connect and it’s suite of ready-to-use connectors?
Once you opt for Kafka Connect, you have a couple of options. One is the JDBC connector which basically polls the target database table(s) to get the information. There is a better (albeit, a little more complex) way based on change data capture. Enter Debezium, which is a distributed platform that builds on top of Change Data Capture features available in different databases. It provides a set of Kafka Connect connectors which tap into row-level changes in database table(s) and convert them into event streams that are sent to Apache Kafka. Once the change log events are in Kafka, they will be available to all the downstream applications.
Here is a high-level overview of the use-case presented in this post. It has been kept simplified for demonstration purposes.
Overview
Data related to Orders is stored in the PostgreSQL database and contains information such as order ID, customer ID, city, transaction amount. time etc. This data is picked up the Debezium connector for PostgreSQL and sent to a Kafka topic. Once the data is in Kafka, another (sink) connector sends them to Azure Data Explorer allow or further querying and analysis.
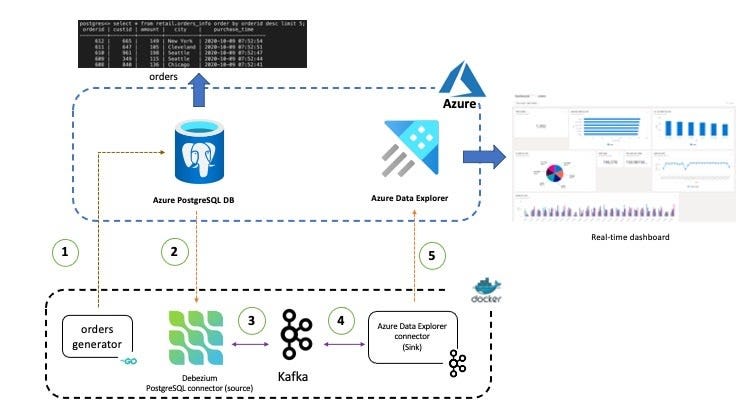
The individual components used in the end to end solution are as follows:
Source and Destination
Data pipelines can be pretty complex! This blog post provides a simplified example where a PostgreSQL database will be used as the source of data and a Big Data analytics engine acts as the final destination (sink). Both these components run in Azure: Azure Database for PostgreSQL (the Source) is a relational database service based on the open-source Postgres database engine and Azure Data Explorer (the Sink) is a fast and scalable data exploration service that lets you collect, store, and analyze large volumes of data from any diverse sources, such as websites, applications, IoT devices, and more.
Although Azure PostgreSQL DB has been used in this blog, the instructions should work for any Postgres database. So feel free to use alternate options if you’d like!
The code and configuration associated with this blog post is available in this GitHub repository
Kafka and Kafka Connect
Apache Kafka along with Kafka Connect acts as a scalable platform for streaming data pipeline — the key components here are the source and sink connectors.
The Debezium connector for PostgreSQL captures row-level changes that insert, update, and delete database content and that were committed to a PostgreSQL database, generates data change event records and streams them to Kafka topics. Behind the scenes, it uses a combination of a Postgres output plugin (e.g. wal2json, pgoutput etc.) and the (Java) connector itself reads the changes produced by the output plug-in using the PostgreSQL’s streaming replication protocol and the JDBC driver.
The Azure Data Explorer sink connector picks up data from the configured Kafka topic, batches and sends them to Azure Data Explorer where they are queued up ingestion and eventually written to a table in Azure Data Explorer. The connector leverages the Java SDK for Azure Data Explorer.
Most of the components (except Azure Data Explorer and Azure PostgreSQL DB) run as Docker containers (using Docker Compose) — Kafka (and Zookeeper), Kafka Connect workers and the data generator application. Having said that, the instructions would work with any Kafka cluster and Kafka Connect workers, provided all the components are configured to access and communicate with each other as required. For example, you could have a Kafka cluster on Azure HD Insight or Confluent Cloud on Azure Marketplace.
Check out these hands-on labs if you’re interested in these scenarios
Here is a breakdown of the components and their service definitions — you can refer to the complete docker-compose file in the GitHub repo
Docker Compose services
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
The Kafka and Zookeeper run using the debezium images — they just work and are great for iterative development with quick feedback loop, demos etc.
dataexplorer-connector:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8080:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=adx_connect_configs
- OFFSET_STORAGE_TOPIC=adx_connect_offsets
- STATUS_STORAGE_TOPIC=adx_connect_statuses
postgres-connector:
image: debezium/connect:1.2
ports:
- 9090:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=pg
- CONFIG_STORAGE_TOPIC=pg_connect_configs
- OFFSET_STORAGE_TOPIC=pg_connect_offsets
- STATUS_STORAGE_TOPIC=pg_connect_statuses
The Kafka Connect source and sink connectors run as separate containers, just to make it easier for you to understand and reason about them — it is possible to run both the connectors in a single container as well.
Notice that, while the PostgreSQL connector is built into debezium/connect image, the Azure Data Explorer connector is setup using custom image. The Dockerfile is quite compact:
FROM debezium/connect:1.2
WORKDIR $KAFKA_HOME/connect
ARG KUSTO_KAFKA_SINK_VERSION
RUN curl -L -O https://github.com/Azure/kafka-sink-azure-kusto/releases/download/v$KUSTO_KAFKA_SINK_VERSION/kafka-sink-azure-kusto-$KUSTO_KAFKA_SINK_VERSION-jar-with-dependencies.jar
Finally, the orders-gen service just Go application to seed random orders data into PostgreSQL. You can refer to the Dockerfile in the GitHub repo
orders-gen:
build:
context: ./orders-generator
environment:
- PG_HOST=<postgres host>
- PG_USER=<postgres username>
- PG_PASSWORD=<postgres password>
- PG_DB=<postgres db name>
Hopefully, by now you have a reasonable understanding of architecture and the components involved. Before diving into the practical aspects, you need take care of a few things.
Pre-requisites
- You will need a Microsoft Azure account. Don’t worry, you can get it for free if you don’t have one already!
- Install Azure CLI
- Install Docker and Docker Compose
Finally, clone this GitHub repo:
git clone https://github.com/abhirockzz/kafka-adx-postgres-cdc-demo
cd kafka-adx-postgres-cdc-demo
To begin with, let’s make sure you have setup and configured Azure Data Explorer and PostgreSQL database.
#big-data #azure #cloud #kafka #postgresql
