A batch job is a scheduled block of code that processes messages without user interaction. Typically a batch job will split a message into individual records, performs some actions on each record, and pushes the processed the output to other downstream systems.
Batch processing is useful when working with scenarios such as
- Synchronizing data between different systems with a “near real-time” data integration.
- For ETL into a target system, such as uploading data from a flat-file (CSV) to a BigData system.
- For regular file backup and processing
In this article, we are going to build a batch file processing following a serverless architecture using Kumologica.
Kumologica is a free low-code development tool to build serverless integrations. You can learn more about Kumologica in this medium article or subscribe to our YouTube channel for the latest videos.
Use Case
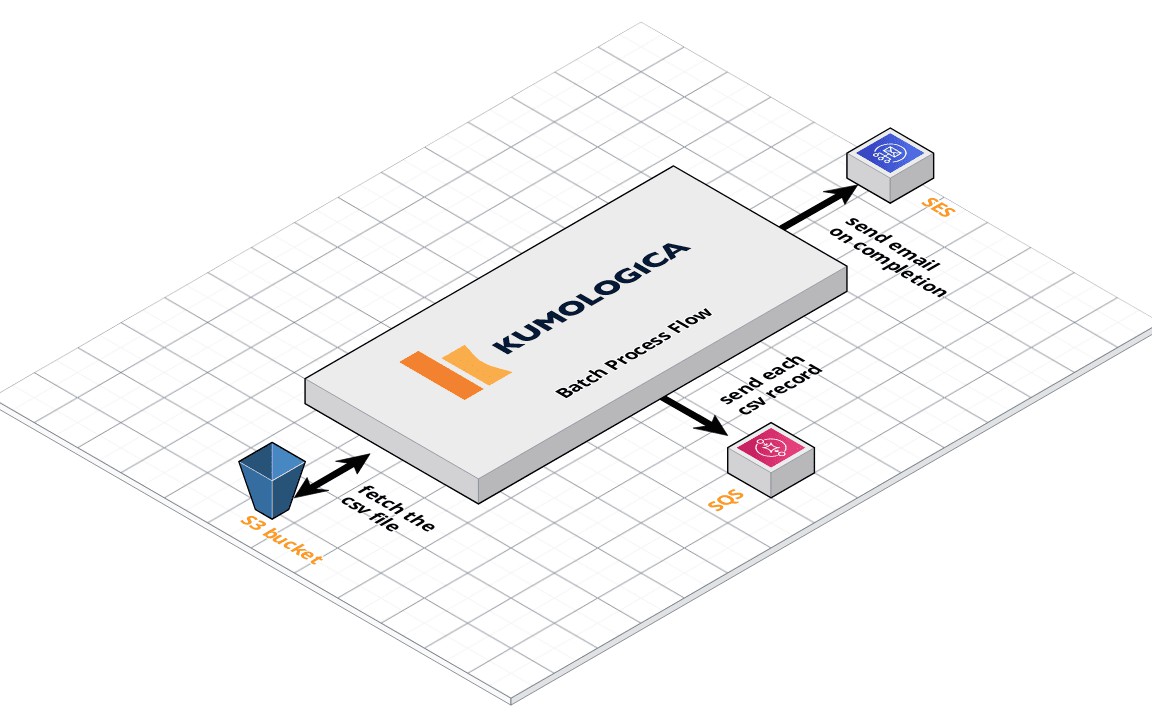
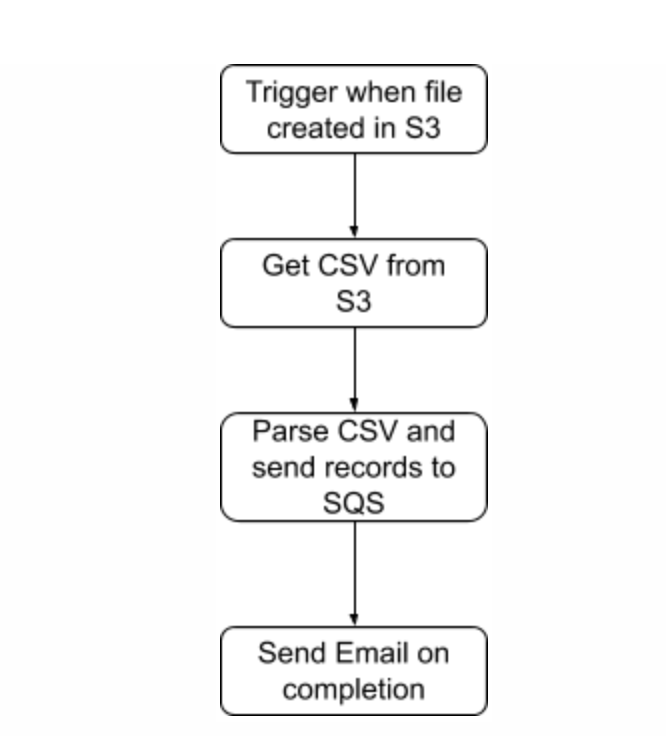
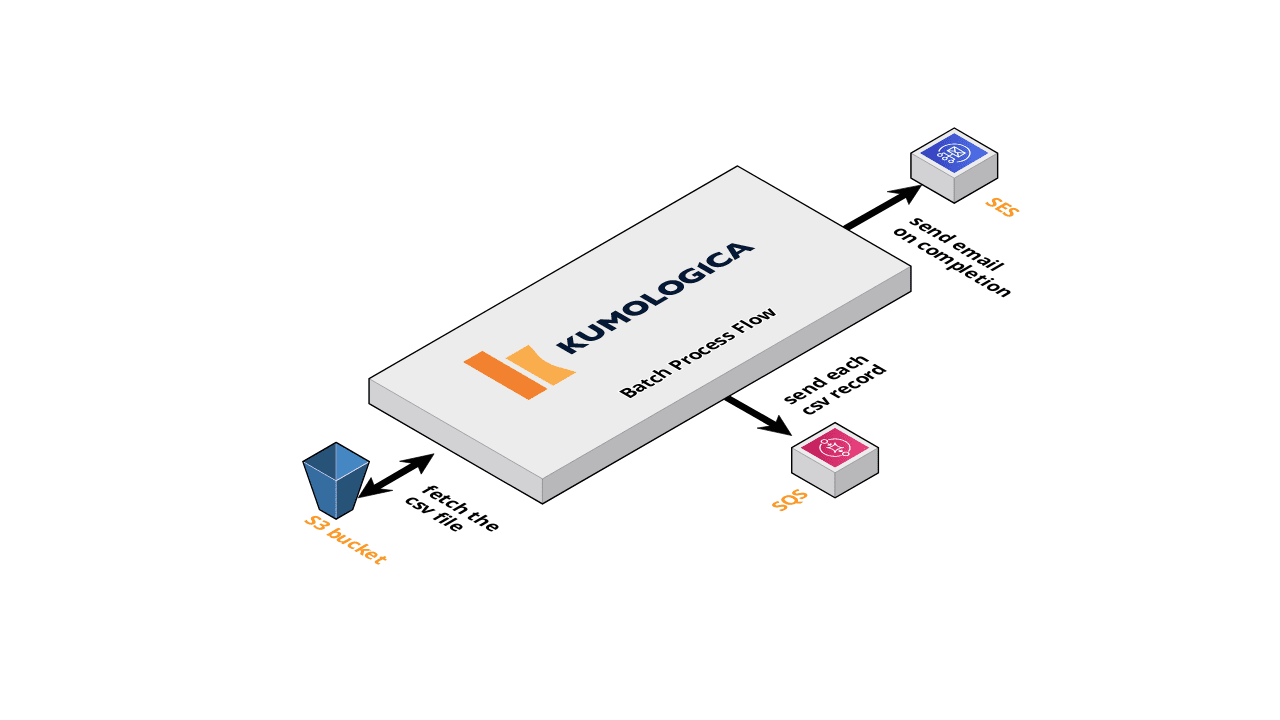
We are going to implement a batch process flow that will pick up a CSV file as when the file is created in the S3 folder. The file will be parsed and converted to a specific JSON structure before being copied to an SQS queue. The flow will finish by sending an email reporting on the completion of the job.
Prerequisite
- Kumologica designer installed in your machine. https://kumologica.com/download.html
- Create an AWS S3 bucket with the name — kumocsvstore. Also, download the following sample CSV file used in this use case to store in your AWS S3 bucket.
- Create an Amazon SQS queue with the name — kumocsvqueue.
- Create an AWS SES entry with a verified email id
Implementation
The diagram below shows the different systems that our flow will be responsible to orchestrate. Given that most of our dependencies are in AWS, we are going to target AWS Lambda as our deployment target to run our flow.
Steps:
- Open Kumologica Designer, click the Home button and choose to Create New Kumologica Project.
- Enter the name (for example BatchProcessFlow), select directory for the project, and switch _Source_into From Existing Flow …
- Copy and Paste the following flow
- Press Create Button.
You should be seeing flow as given below on the designer canvas.

Understanding the Flow
- **S3 trigger **is the EventListener node is configured to have the EventSource as “Amazon S3”. This is to have the Kumologica flow to accept Amazon S3 trigger events when a file is created in the S3 folder.
- **Log Entry **is the logger node to print the entry of this flow.
- GetCSVFromS3 is the AWS S3 node to get the CSV file content from the S3 bucket.
- ConvertBufferToString is the function node to convert Buffer object to String in UTF-8. As the AWS S3 node returns a buffer object we need to make it as UTF-8 string before giving to the CSV node to parse.
- **ParseCSV **is the CSV node to parser CSV string to javascript object.
- **The split **will split the parsed CSV object to individual record objects which are passed to a Datamapper node.
- The Datamapper node maps the object to a JSON structure expected to be published on to the Amazon SQS queue.
- SendToSQS node published the JSON message to the SQS queue.
- Join node ensure to close the iteration done by the split node.
- SendEmail node is the Amazon SES node for sending the completion email.
- Event listener End node to stop the flow.
#tutorial #integration #aws #serverless #microservice #aws lambda #low code #batch processing