How Nutrino designed a serverless MLOps stack in production
Bringing ML models to production today is complicated — different companies have different requirements from the ML stack and there are many tools out there, each tool tries to solve a different aspect of the ML lifecycle. These tools are still a work in progress and there’s no one “clear cut” solution for MLOps. In this article, I’d like to share the process we went through in creating our own MLOps stack, including the way our team worked before the process started, the research we did on different MLOps tools, and how we decided on the solution that fit our non-standard models.
For the detailed solution, including more technical explanations, check out part II of this article.
TL;DR - We managed to run different types of models (our own Python models) with multiple production versions for each of them — all in a serverless environment!
Our ML stack pre-refactoring
This was our ML stack before we began the process of refactoring:
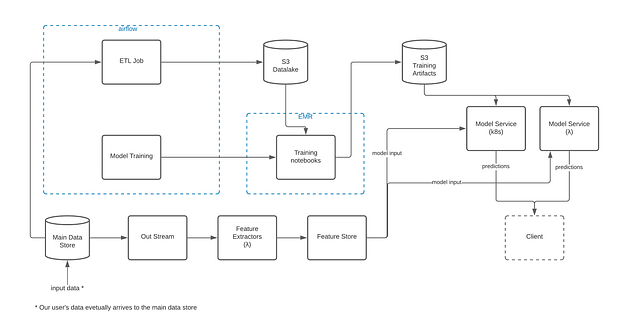
Image by Author
Research Environment
We were using a datalake environment which had an ETL process that transferred production data to parquet files to S3 in that environment. The data scientists were doing their research using Zeppelin notebooks running on EMR clusters in that environment (thus utilizing the distributed abilities of Spark).
Feature Extraction
Feature extraction was done using AWS lambdas that were triggered by a Kinesis stream every time new data arrived to our centralized data store, and was deployed using the Serverless Framework.
Training
- Once a research for a certain model was completed, the data scientist created a training notebook for that model (in the same datalake environment).
- We ran the training’s notebook periodically using Apache Airflow (and leveraging its strength in running scheduled jobs). To do so, we created a DAG (Directed Acyclic Graph) for each of the models’ training notebooks.
- Airflow’s DAGs were deployed instantly every push to the master branch.
- The DAGs created an EMR cluster which ran the training notebooks. The notebooks were connected to a GitHub repository, so that every commit in a notebook was basically an automated “deployment” of the training code.
#mlops #serverless #data-science
