Regularization is a method used to reduce the variance of a Machine Learning model; in other words, it is used to reduce overfitting. Overfitting occurs when a machine learning model performs well on the training examples but fails to yield accurate predictions for data that it has not been trained on.
In theory, there are 2 major ways to build a machine learning model with the ability to generalize well on unseen data:
- Train the simplest model possible for our purpose(according to Occam’s Razor).
- Train a complex or more expressive model on the data and perform regularization.
It has been observed that method #2 yields the best performing models by contemporary standards. In other words, we want our model to have the ability to capture highly complex functions. However, to overcome overfitting, we regularize it.
Objective:
In the present article we will discuss:
- Effect of regularization on coefficients and model performance.
- Data pre-processing steps mandatory for regularization.
We will use the Boston Housing Prices Data available in scikit-learn.
Data
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing, linear_model, model_selection, metrics, datasets, base
# Load Data
bos = datasets.load_boston()
# Load LSTAT and RM Features from Boston Housing Data
X = pd.DataFrame(bos.data, columns = bos.feature_names)[['LSTAT', 'RM']]
y = bos.target
Effect of regularization on Model Coefficients
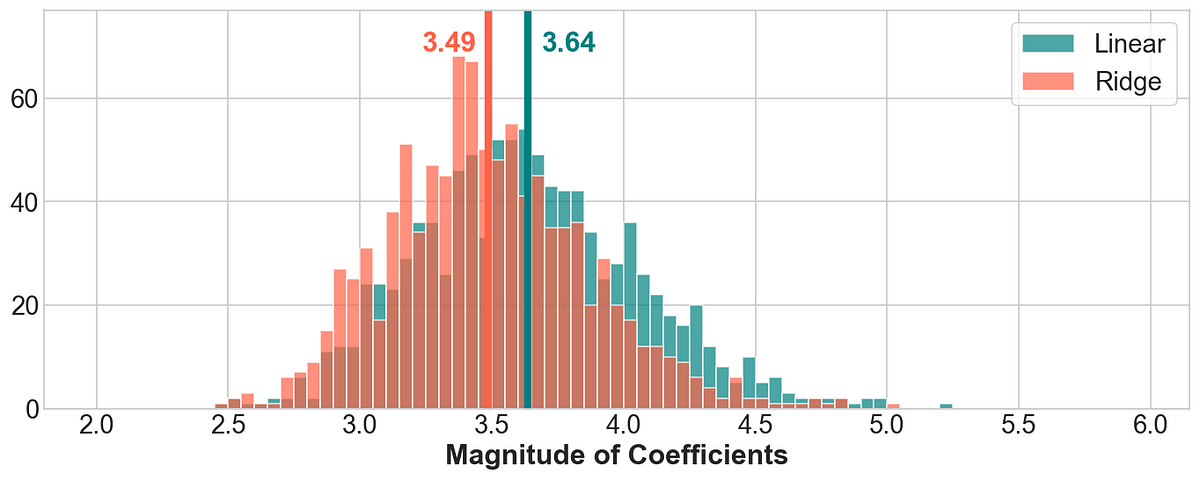
Regularization penalizes a model for being more complex; for linear models, it means regularization forces model coefficients to be smaller in magnitude.
First let us understand the problems of having large model coefficients. Let us assume a linear model trained on the above data. Let us assume the regression coefficient for the input LSTAT to be large. Now, this means, that assuming all the features are scaled, for a very small change in LSTAT, the prediction will change by a large amount. This simply follows from the Equation for Linear Regression.
In general, inputs having significantly large coefficients tend to drive the model predictions when all the features take values in similar ranges. This becomes a problem if the important feature is noisy or the model overfits to the data — because this causes the model predictions to be either driven by noise or by insignificant variations in LSTAT.
In other words, in general, we want the model to to have coefficients of smaller magnitudes.
Let us See if regularizing indeed reduces the magnitude of coefficients. To visualize this, we will generate polynomial features from our data of all orders from 1 to 10 and make a box-plot of the magnitude of coefficients of the features for:
- Un-regularized Linear Regression
- L2 Regularized Linear Regression(Ridge)
Note: Before fitting the model, we are standardizing the inputs.
model = linear_model.LinearRegression()
scaler = preprocessing.StandardScaler().fit(X_train)
X_scaled = scaler.transform(X_train)
model.fit(X_scaled , y_train)
coefs = pd.DataFrame()
coefs['Features'] = X.columns
coefs['1'] = np.abs(model.coef_)
for order in range(2, 11):
poly = preprocessing.PolynomialFeatures(order).fit(X_train)
X_poly = poly.transform(X_train)
scaler = preprocessing.StandardScaler().fit(X_poly)
model = linear_model.LinearRegression().fit(scaler.transform(X_poly), y_train)
coefs = pd.concat([coefs, pd.Series(np.abs(model.coef_), name = str(order))], axis = 1)
sns.boxplot(data = pd.melt(coefs.drop('Features', axis = 1)), x = 'variable', y = 'value',
order = [str(i) for i in range(1, 11)], palette = 'Blues')
ax = plt.gca()
ax.yaxis.grid(True, alpha = .3, color = 'grey')
ax.xaxis.grid(False)
plt.yscale('log')
plt.xlabel('Order of Polynomial', weight = 'bold')
plt.ylabel('Magnitude of Coefficients', weight = 'bold')
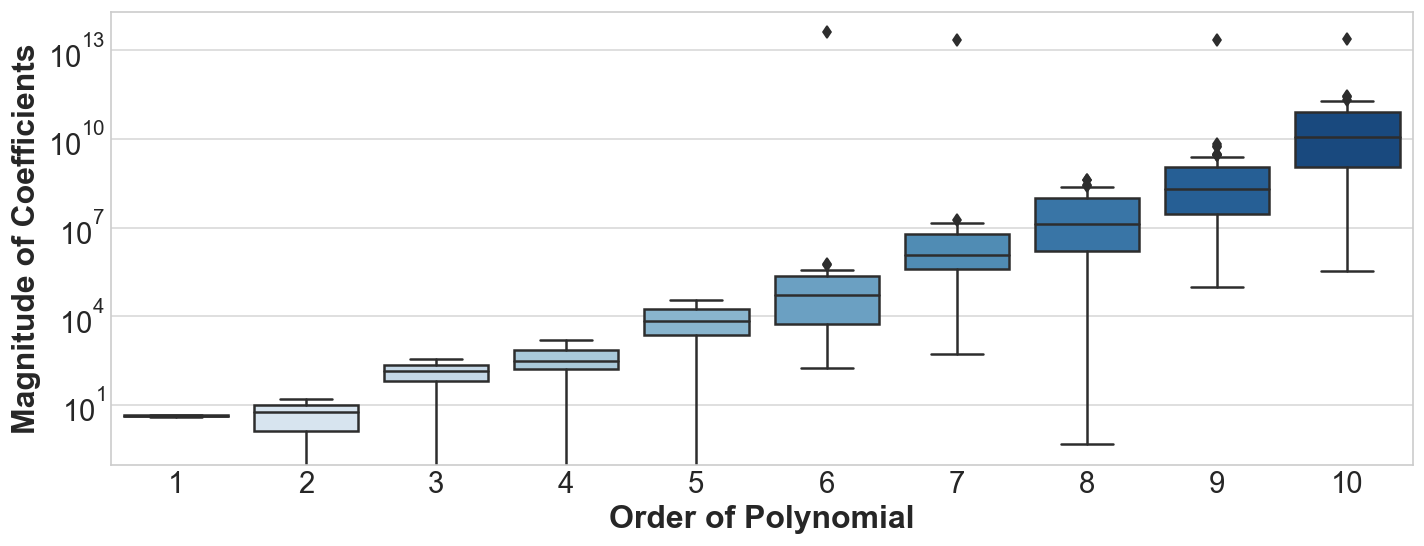
Distribution of Linear Model(Not Regularized) Coefficients for polynomials of various degrees
We observe the following:
- As the order of polynomial increases, the linear model coefficients become more likely to take on large values.
- The largest coefficient of the 10th order polynomial is over 10¹² times the magnitude of the largest coefficient of the first order features.
- Most of the higher order polynomials have coefficients in the order of 10⁴ to 10¹⁰
Let us now, perform the same exercise with Ridge(L2 Regularized) Regression.
#regression #linear-regression #scikit-learn #regularization #ridge-regression #deep learning