Learn Docker from Beginner to Advanced
The series:
- Learn Docker from Beginner to Advanced part I - Basics: This part covers what Docker is and why I think you should use it. It brings up concepts such as images and containers and takes you through building and running your first container
- Learn Docker from Beginner to Advanced part II - Lolumes: This is about Volumes and how we can use volumes to persist data but also how we can turn our development environment into a Volume and make our development experience considerably better
- Learn Docker from Beginner to Advanced part III - Databases, linking and networks: This is about how to deal with Databases, putting them into containers and how to make containers talk to other containers using legacy linking but also the new standard through networks
- Learn Docker from Beginner to Advanced part IV - Introducing Docker Compose: This is how we manage more than one service using Docker Compose ( this is 1/2 part on Docker Compose)
- Learn Docker from Beginner to Advanced part V- Going deeper with Docker Compose: This part is the second and concluding part on Docker Compose where we cover Volumes, Environment Variables and working with Databases and Networks
Now there are a ton of articles out there for Docker but I struggle with the fact that none of them are really thorough and explains what goes on, or rather that’s my impression, feel free to disagree :). I should say I’m writing a lot of these articles for me and my own understanding and to have fun in the process :). I also hope that it can be useful for you as well.
So I decided to dig relatively deep so that you all hopefully might benefit. TLDR, this is the first part in a series of articles on Docker, this part explains the basics and the reason I think you should use Docker.
This article really is Docker from the beginning, I assume no pre-knowledge, I assume nothing. Enjoy :)

Resources
Using Docker and containerization is about breaking apart a monolith into microservices. Throughout this series, we will learn to master Docker and all its commands. Sooner or later you will want to take your containers to a production environment. That environment is usually the Cloud. When you feel you’ve got enough Docker experience have a look at these links to see how Docker can be used in the Cloud as well:
- Sign up for a free Azure account To use containers in the Cloud like a private registry you will need a free Azure account
- Containers in the Cloud Great overview page that shows what else there is to know about containers in the Cloud
- Deploying your containers in the Cloud Tutorial that shows how easy it is to leverage your existing Docker skill and get your services running in the Cloud
- Creating a container registry Your Docker images can be in Docker Hub but also in a Container Registry in the Cloud. Wouldn’t it be great to store your images somewhere and actually be able to create a service from that Registry in a matter of minutes?
Learn Docker from Beginner to Advanced part I - Basics
In this article, we will attempt to cover the following topics
- Why Docker and what is it, this is probably the most important part of the article, why Docker, why not some other technology or status quo? I will attempt to explain what Docker is and what it consists of.
- Docker in action, we will dockerize an application to showcase we understand and can use the core concepts that make out Docker.
- Improving our set up, we should ensure our solution does not rely on static values. We can ensure this by creating and setting environment variables whose value we can read from inside of our application.
- Managing our container, now it’s fairly easy to get a container up and running but let’s look how to manage it, after all, we don’t want the container to be up and running forever. Even it’s a very lightweight thing, it adds up and it can block ports that you want to use for other things.
Remember that this is the first part of a series and that we will look into other things in this series on Docker such as Volumes, Linking, Micro Services, and Orchestration, but that will be covered in future parts.
Why Docker and what is it
Docker helps you create a reproducible environment. You are able to specify the exact version of different libraries, different environment variables and their values among other things. Most importantly you are able to run your application in isolation inside of that environment.
The big question is why we would want that?
- onboarding, every time you onboard a new developer in a project they need to set up a lot of things like installing SDKs, development tools, databases, add permissions and so on. This a process that can take from one day to up to 2 weeks
- environments look the same, using Docker you can create a DEV, STAGING as well as PRODUCTION environment that all look the same. That is really great as before Docker/containerization you could have environments that were similar but there might have been small differences and when you discovered a bug you could spend a lot of time chasing down the root cause of the bug. Sometimes the bug was in the source code itself but sometimes it was due to some difference in the environment and that usually took a long time to determine.
- works on my machine, this point is much like the above but because Docker creates these isolated containers, where you specify exactly what they should contain, you can also ship these containers to the customers and they will operate in the exact same way as they did on your development machine/s.
What is it
Ok, so we’ve mentioned some great reasons above why you should look into Docker but let’s dive more into what Docker actually is. We’ve established that it lets us specify an environment like the OS, how to find and run the apps and the variables you need, but what else is there to know about Docker?
Docker creates stand-alone packages called containers that contain everything that is needed for you to run your application. Each container gets its own CPU, memory and network resources and does not depend on a specific operating system or kernel. The first that comes to mind when I describe the above is a Virtual Machine, but Docker differs in how it shares or dedicates resources. Docker uses a so-called layered file system which enables the containers to share common parts and the end result is that containers are way less of resource-hog on the host system than a virtual machine.
In short, the Docker containers, contain everything you need to run an application, including the source code you wrote. Containers are also isolated and secure light-weight units on your system. This makes it easy to create multiple micro-services that are written in different programming languages and that are using different versions of the same lib and even the same OS.
If you are curious about how exactly Docker does this I urge to have a look at the following links on layered file system and the library runc and also this great wikipedia overview of Docker.
Docker in action
Ok, so we covered what Docker is and some benefits. We also understood that the thing that eventually runs my application is called a container. But how do we get there? Well, we start out with a description file, called a Dockerfile. In this Dockerfile, we specify everything we need in terms of OS, environment variables and how to get our application in there.
Now we will jump in at the deep end. We will build an app and Dockerize it, so we will have our app running inside of a container, isolated from the outside world but reachable on ports that we explicitly open up.
We will take the following steps:
- create an application, we will create a Node.js Express application, which will act as a REST API.
- create a Dockerfile, a text file that tells Docker how to build our application
- build an image, the pre-step to having our application up and running is to first create a so-called Docker image
- create a container, this is the final step in which we will see our app up and running, we will create a container from a Docker image
Creating our app
We will now create an Express Node.js project and it will consist of the following files:
- app.js, this is the file that spins up our REST
- package.json, this is the manifest file for the project, here we will see all the dependencies like express but we will also declare a script start so we can easily start our application
- Dockerfile, this is a file we will create to tell Docker how to Dockerize our application
To generate our package.json we just place ourselves in the projects directory and type:
npm init -y
This will produce the package.json file with a bunch of default values.
Then we should add the dependencies we are about to use, which is the library express , we install it by typing like this:
npm install express —-save
Let’s add some code
Now when we have done all the prework with generating a package.json file and installing dependencies, it’s time to add the code needed for our application to run, so we add the following code to app.js:
// app.js
const express = require('express')
const app = express()
const port = 3000
app.get('/', (req, res) => res.send('Hello World!'))
app.listen(port, () => console.log(`Example app listening on port ${port}!`))
We can try and run this application by typing:
node app.js
Going to a web browser on http://localhost:3000 we should now see:

Ok so that works, good :)
One little comment though, we should take note of the fact that we are assigning the port to 3000 when we later create our Dockerfile.
Creating a Dockerfile
So the next step is creating our Dockerfile. Now, this file acts as a manifest but also as a build instruction file, how to get our app up and running. Ok, so what is needed to get the app up and running? We need to:
- copy all app files into the docker container
- install dependencies like express
- open up a port, in the container that can be accessed from the outside
- instruct, the container how to start our app
In a more complex application, we might need to do things like setting environment variables or set credentials for a database or run a database seed to populate the database and so on. For now, we only need the things we specified in our bullet list above. So let’s try to express that in our Dockerfile:
// Dockerfile
FROM node:latest
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
ENTRYPOINT ["node", "app.js"]
Let’s break the above commands down:
- FROM, this is us selecting an OS image from Docker Hub. Docker Hub is a global repository that contains images that we can pull down locally. In our case we are choosing an image based on Ubuntu that has Node.js installed, it’s called node. We also specify that we want the latest version of it, by using the following tag
:latest - WORKDIR, this simply means we set a working directory. This is a way to set up for what is to happen later, in the next command below
- COPY, here we copy the files from the directory we are standing into the directory specified by our WORKDIR command
- RUN, this runs a command in the terminal, in our case we are installing all the libraries we need to build our Node.js express application
- EXPOSE, this means we are opening up a port, it is through this port that we communicate with our container
- ENTRYPOINT, this is where we should state how we start up our application, the commands need to be specified as an array so the array
[“node”, “app.js”]will be translated to the node app.js in the terminal
Quick overview
Ok, so now we have created all the files we need for our project and it should look like this:
app.js // our express app
Dockerfile // our instruction file that Docker will read from
/node_modules // directory created when we run npm install
package.json // npm init created this
package-lock.json // created when we installed libraries from NPM
Building an image
There are two steps that need to be taken to have our application up and running inside of a container, those are:
- creating an image, with the help of the Dockerfile and the command
docker buildwe will create an image - start the container, now that we have an image from the action we took above we need to create a container
First things first, let’s create our image with the following command:
docker build -t chrisnoring/node:latest .
The above instruction creates an image. The . at the end is important as this instructs Docker and tells it where your Dockerfile is located, in this case, it is the directory you are standing in. If you don’t have the OS image, that we ask for in the FROM command, it will lead to it being pulled down from Docker Hub and then your specific image is being built.
Your terminal should look something like this:

What we see above is how the OS image node:latest is being pulled down from the Docker Hub and then each of our commands is being executed like WORKDIR, RUN and so on. Worth noting is how it says removing intermediate container after each step. Now, this is Docker being smart and caching all the different file layers after each command so it goes faster. In the end, we see successfully built which is our cue that everything was constructed successfully. Let’s have a look at our image with:
docker images

We have an image, success :)
Creating a container
Next step is to take our image and construct a container from it. A container is this isolated piece that runs our app inside of it. We build a container using docker run . The full command looks like this:
docker run chrisnoring/node
That’s not really good enough though as we need to map the internal port of the app to an external one, on the host machine. Remember this is an app that we want to reach through our browser. We do the mapping by using the flag -p like so:
-p [external port]:[internal port]
Now the full command now looks like this:
docker run -p 8000:3000 chrisnoring/node
Ok, running this command means we should be able to visit our container by going to http://localhost:8000, 8000 is our external port remember that maps to the internal port 3000. Let’s see, let’s open up a browser:

There we have it folks, a working container :D

Improving our set up with Environment Variables
Ok, so we’ve learned how to build our Docker image, we’ve learned how to run a container and thereby our app inside of it. However, we could be handling the part with PORT a bit nicer. Right now we need to keep track of the port we start the express server with, inside of our app.js , to make sure this matches what we write in the Dockerfile. It shouldn’t have to be that way, it’s just static and error-prone.
To fix it we could introduce an environment variable. This means that we need to do two things:
- add an environment variable to the Dockerfile
- read from the environment variable in app.js
Add an environment variable
For this we need to use the command ENV, like so:
ENV PORT=3000
Let’s add that to our Dockerfile so it now looks like so:
FROM node:latest
WORKDIR /app
COPY . .
ENV PORT=3000
RUN npm install
EXPOSE 3000
ENTRYPOINT ["node", "app.js"]
Let’s do one more change namely to update EXPOSE to use our variable, so we git rid of static values and rely on variables instead, like so:
FROM node:latest
WORKDIR /app
COPY . .
ENV PORT=3000
RUN npm install
EXPOSE $PORT
ENTRYPOINT ["node", "app.js"]
Note above how we change our EXPOSE command to $PORT, any variables we use needs to be prefixed with a $ character:
EXPOSE $PORT
Read the environment variable value in App.js
We can read values from environment variables in Node.js like so:
process.env.PORT
So let’s update our app.js code to this:
// app.js
const express = require('express')
const app = express()
const port = process.env.PORT
app.get('/', (req, res) => res.send('Hello World!'))
app.listen(port, () => console.log(`Example app listening on port ${port}!`))
NOTE, when we do a change in our
app.jsor ourDockerfilewe need to rebuild our image. That means we need to run thedocker buildcommand again and prior to that we need to have torn down our container withdocker stopanddocker rm. More on that in the upcoming sections.
Managing our container
Ok, so you have just started your container with docker run and you notice that you can’t shut it off in the terminal. Panic sets in ;) At this point you can go to another terminal window and do the following:
docker ps
This will list all running containers, you will be able to see the containers name as well as its id. It should look something like this:

As you see above we have the column CONTAINER_ID or NAMES column, both these values will work to stop our container, cause that is what we need to do, like so:
docker stop f40
We opt for using CONTAINER_ID and the three first digits, we don’t need more. This will effectively stop our container.
Daemon mode
We can do like we did above and open a separate terminal tab but running it in Daemon mode is a better option. This means that we run the container in the background and all output from it will not be visible. To make this happen we simply add the flag -d . Let’s try that out:

What we get now is just the container id back, that’s all we’re ever going to see. Now it’s easier for us to just stop it if we want, by typing docker stop 268 , that’s the three first digits from the above id.
Interactive mode
Interactive mode is an interesting one, this allows us to step into a running container and list files, or add/remove files or just about anything we can do for example bash. For this, we need the command docker exec, like so:

Above we run the command:
docker exec -it 268 bash
NOTE, the container needs to be up and running. If you’ve stopped it previously you should start it with docker start 268. Replace 268 with whatever id you got when it was created when you typed docker run.
268 is the three first digits if our container and -it means interactive mode and our argument bash at the end means we will run a bash shell.
We also run the command ls, once we get the bash shell up and running so that means we can easily list what’s in the container so we can verify we built it correctly but it’s a good way to debug as well.
If we just want to run something on the container like a node command, for example, we can type:
docker exec 268 node app.js
that will run the command node app.js in the container
Docker kill vs Docker stop
So far we have been using docker stop as way to stop the container. There is another way of stopping the container namely docker kill , so what is the difference?
- docker stop, this sends the signal SIGTERM followed by SIGKILL after a grace period. In short, this is a way to bring down the container in a more graceful way meaning it gets to release resources and saving state.
- docker kill, this sends SIGKILL right away. This means resource release or state save might not work as intended. In development, it doesn’t really matter which one of the two commands are being used but in a production scenario it probably wiser to rely on
docker stop
Cleaning up
During the course of development you will end up creating tons of container so ensure you clean up by typing:
docker rm id-of-container
Summary Part I
Ok, so we have explained Docker from the beginning. We’ve covered motivations for using it and the basic concepts. Furthermore, we’ve looked into how to Dockerize an app and in doing so covered some useful Docker commands. There is so much more to know about Docker like how to work with Databases, Volumes, how to link containers and why and how to spin up and manage multiple containers, also known as orchestration.
Learn Docker from Beginner to Advanced Part II
Welcome to the second part of this series about Docker. Hopefully, you have read the first part to gain some basic understanding of Dockers core concepts and its basic commands or you have acquired that knowledge elsewhere.
In this article, we will attempt to cover the following topics
- recap and problem introduction , let’s recap on the lessons learned from part I and let’s try to describe how not using a volume can be quite painful
- persist data , we can use Volumes to persist files we create or Databases that we change ( e.g Sqllite).
- turning our workdir into a volume , Volumes also give us a great way to work with our application without having to set up and tear down the container for every change.
Recap and the problem of not using a volume
Ok, so we will keep working on the application we created in the first part of this series, that is a Node.js application with the library express installed.
We will do the following in this section:
- run a container, we will start a container and thereby repeat some basic Docker commands we learned in the first part of this series
- update our app, update our source code and start and stop a container and realize why this way of working is quite painful
Run a container
As our application grows we might want to do add routes to it or change what is rendered on a specific route. Let’s show the source code we have so far:
// app.js
const express = require('express')
const app = express()
const port = process.env.PORT
app.get('/', (req, res) => res.send('Hello World!'))
app.listen(port, () => console.log(`Example app listening on port ${port}!`))
Now let’s see if we remember our basic commands. Let’s type:
docker ps

Ok, that looks empty. So we cleaned up last time with docker stop or docker kill , regardless of what we used we don’t have a container that we can start, so we need to build one. Let’s have a look at what images we have:
docker images

Ok, so we have our image there, let’s create and run a container:
docker run -d -p 8000:3000 chrisnoring/node
That should lead to a container up and running at port 8000 and it should run in detached mode, thanks to us specifying the -d flag.

We get a container ID above, good. Let’s see if we can find our application at http://localhost:8000:

Ok, good there it is. Now we are ready for the next step which is to update our source code.
Update our app
Let’s start by changing the default route to render out hello Chris , that is add the following line:
app.get('/', (req, res) => res.send('Hello Chris!'))
Ok, so we save our change and we head back to the browser and we notice it is still saying Hello World. It seems the container is not reflecting our changes. For that to happen we need to bring down the container, remove it, rebuild the image and then run the container again. Because we need to carry out a whole host of commands, we will need to change how we build and run our container namely by actively giving it a name, so instead of running the container like so:
docker run -d -p 8000:3000 chrisnoring/node
We now type:
docker run -d -p 8000:3000 –name my-container chrisnoring/node
This means our container will get the name my-container and it also means that when we refer to our container we can now use its name instead of its container ID, which for our scenario is better as the container ID will change for every setup and tear down.
docker stop my-container // this will stop the container, it can still be started if we want to
docker rm my-container // this will remove the container completely
docker build -t chrisnoring/node . // creates an image
docker run -d -p 8000:3000 --name my-container chrisnoring/node
You can chain these commands to look like this:
docker stop my-container && docker rm my-container && docker build -t chrisnoring/node . && docker run -d -p 8000:3000 --name my-container chrisnoring/node
My first seeing thought seeing that is WOW, that’s a lot of commands. There has got to be a better way right, especially when I’m in the development phase?

Well yes, there is a better way, using a volume. So let’s look at volumes next.
Using a volume
Volumes or data volumes is a way for us to create a place in the host machine where we can write files so they are persisted. Why would we want that? Well, when we are under development we might need to put the application in a certain state so we don’t have to start from the beginning. Typically we would want to store things like log files, JSON files and perhaps even databases (SQLite ) on a volume.
It’s quite easy to create a volume and we can do so in many different ways, but mainly there are two ways:
- before you create a container
- lazily, e.g while creating the container
Creating and managing a volume
To create a volume you type the following:
docker volume create [name of volume]
we can verify that our volume was created by typing:
docker volume ls

This will list all the different volumes we have. Now, this will after a while lead to you having tons of volumes created so it’s good to know how to keep down the number of volumes. For that you can type:
docker volume prune
This will remove all the volumes you currently are not using. You will be given a question if you want to proceed.

If you want to remove a single volume you can do so by typing:
docker volume rm [name of volume]
Another command you most likely will want to know about is the inspect command that allows us to see more details on our created volume and probably most important where it will place the persisted files.
docker inspect [name of volume]
A comment on this though is that most of the time you might not care where Docker place these files but sometimes you would want to know due to debugging purposes. As we will see later in this section controlling where files are persisted can work to our advantage when we develop our application.
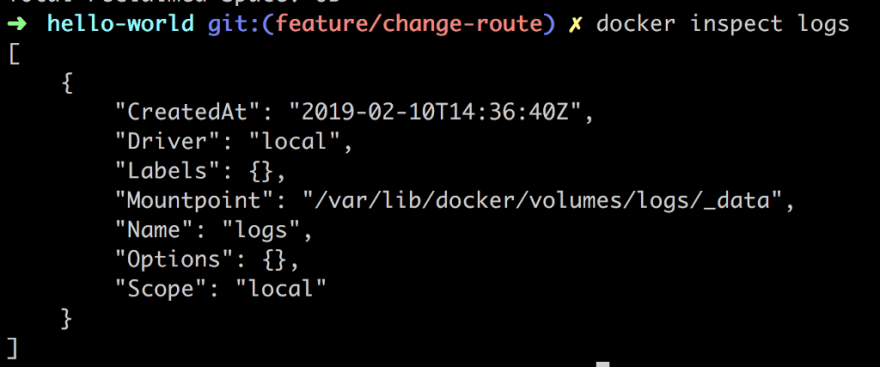
As you can see the Mountpoint field is telling us where Docker is planning to persist your files.
Mounting a volume in your application
Ok, so we have come to the point that we want to use our volume in an application. We want to be able to change or create files in our container so that when we pull it down and start it up again our changes will still be there.
For this we can use two different commands that achieve relatively the same thing with a different syntax, those are:
-v, —-volume, the syntax looks like the following -v [name of volume]:[directory in the container], for example -v my-volume:/app--mount, the syntax looks like the following–mount source=[name of volume],target=[directory in container] , for example —-mount source=my-volume,target=/app
Used in conjuncture with running a container it would look like this for example:
docker run -d -p 8000:3000 --name my-container --volume my-volume:/logs chrisnoring/node
Let’s try this out. First off let’s run our container:

Then let’s run our inspect command to ensure our volume has been correctly mounted inside of our container. When we run said command we get a giant JSON output but we are looking for the Mounts property:
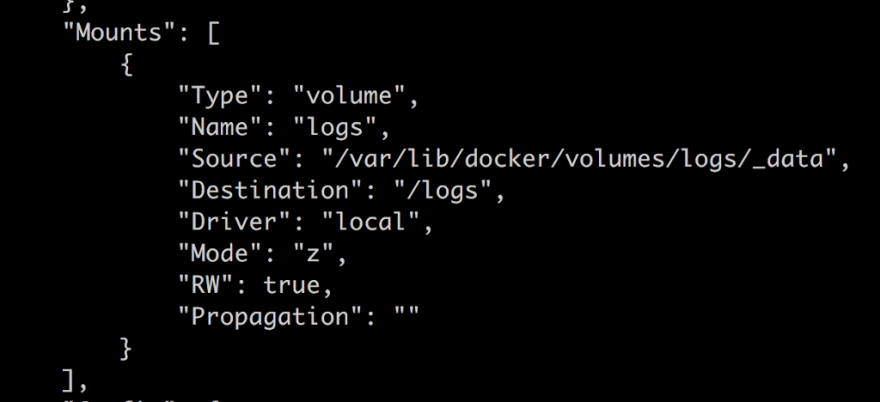
Ok, our volume is there, good. Next step is to locate our volume inside of our container. Let’s get into our container with:
docker exec -it my-container bash
and thereafter navigate to our /logs directory:
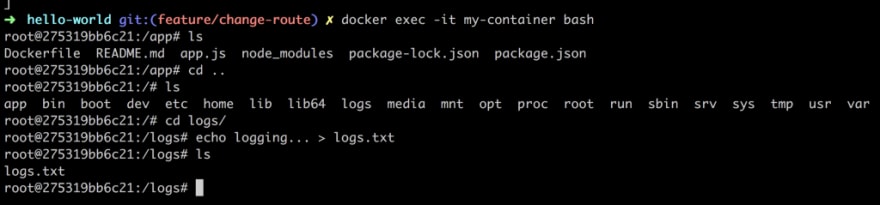
Ok, now if we bring down our container everything we created in our volume should be persisted and everything that is not placed in the volume should be gone right? Yep, that’s the idea. Good, we understand the principle of volumes.
Mounting a subdirectory as a volume
So far we have been creating a volume and have let Docker decide on where the files are being persisted. What happens if we decide where these files are persisted?
Well if we point to a directory on our hard drive it will not only look at that directory and place files there but it will pick the pre-existing files that are in there and bring them into our mount point in the container. Let’s do the following to demonstrate what I mean:
- create a directory, let’s create a directory /logs
- create a file, let’s create a file logs.txt and write some text in it
- run our container, let’s create a mount point to our local directory + /logs
The first two commands lead to us having a file structure like so:
app.js
Dockerfile
/logs
logs.txt // contains 'logging host...'
package.json
package-lock.json
Now for the run command to get our container up and running:

Above we observe that our --volume command looks a bit different. The first argument is $(pwd)/logs which means our current working directory and the subdirectory logs. The second argument is /logs which means we are saying mount our host computers logs directory to a directory with the same name in the container.
Let’s dive into the container and establish that the container has indeed pulled in the files from our host computers logs directory:

As you we can see from the above set of commands we go into the container with docker exec -it my-container bash and then we proceed to navigate ourselves to the logs directory and finally we read out the content of logs.txt with the command cat logs.txt. The result is logging host… e.g the exact file and content that we have on the host computer.
But this is a volume however which means there is a connection between the volume in the host computer and the container. Let’s edit the file next on the host computer and see what happens to the container:

Wow, it changed in the container as well without us having to tear it down or restarting it.
Treating our application as a volume
To make our whole application be treated as a volume we need to tear down the container like so:
docker kill my-container && docker rm my-container
Why do we need to do all that? Well, we are about to change the Dockerfile as well as the source code and our container won’t pick up these changes, unless we use a Volume, like I am about to show you below.
Thereafter we need to rerun our container this time with a different volume argument namely --volume $(PWD):/app.
NOTE, if your PWD consists of a directory with space in it you might need to specify the argument as
"$(PWD)":/appinstead, i.e we need to surround$(PWD)with double quotes. Thank you to Vitaly for pointing that out :)
The full command looks like this:

This will effectively make our entire app directory a volume and every time we change something in there our container should reflect the changes.
So let’s try adding a route in our Node.js Express application like so:
app.get("/docker", (req, res) => {
res.send("hello from docker");
});
Ok, so from what we know from dealing with the express library we should be able to reach http://localhost:8000/docker in our browser or?

Sad face :(. It didn’t work, what did we do wrong? Well here is the thing. If you change the source in a Node.js Express application you need to restart it. This means that we need to take a step back and think how can we restart our Node.js Express web server as soon as there is a file change. There are several ways to accomplish this like for example:
- install a library like nodemon or forever that restarts the web server
- run a PKILL command and kill the running node.js process and the run node app.js
It feels a little less cumbersome to just install a library like nodemon so let’s do that:

This means we now have another library dependency in package.json but it means we will need to change how we start our app. We need to start our app using the command nodemon app.js. This means nodemon will take care of the whole restart as soon as there is a change. While we are at it let’s add a start script to package.json, after all, that is the more Node.js -ish way of doing things:

Let’s describe what we did above, in case you are new to Node.js. Adding a start script to a package.json file means we go into a section called “scripts” and we add an entry start, like so:
// excerpt package.json
"scripts": {
"start": "nodemon app.js"
}
By default a command defined in "scripts" is run by you typing npm run [name of command]. There are however known commands, like start and test and with known commands we can omit the keyword run, so instead of typing npm run start, we can type npm start. Let’s add another command "log" like so:
// excerpt package.json
"scripts": {
"start": "nodemon app.js",
"log": "echo \"Logging something to screen\""
}
To run this new command "log" we would type npm run log.
Ok, one thing remains though and that is changing the Dockerfile to change how it starts our app. We only need to change the last line from:
ENTRYPOINT ["node", "app.js"]
to
ENTRYPOINT ["npm", "start"]
Because we changed the Dockerfile this leads to us having to rebuild the image. So let’s do that:
docker build -t chrisnoring/node .
Ok, the next step is to bring up our container:
docker run -d -p 8000:3000 --name my-container --volume $(PWD):/app chrisnoring/node
Worth noting is how we expose the entire directory we are currently standing in and mapping that to /app inside the container.
Because we’ve already added the /docker route we need to add a new one, like so:
app.get('/nodemon', (req, res) => res.send('hello from nodemon'))
Now we hope that nodemon has done it’s part when we save our change in app.js :

Aaaand, we have a winner. It works to route to /nodemon . I don’t know about you but the first time I got this to work this was me:

Summary Part II
This has brought us to the end of our article. We have learned about Volumes which is quite a cool and useful feature and more importantly I’ve shown how you can turn your whole development environment into a volume and keep working on your source code without having to restart the container.
Learn Docker from Beginner to Advanced Part III
This the third part of our series. In this part, we will focus on learning how we work with Databases and Docker together. We will also introduce the concept of linking as this goes tightly together with working with Databases in a containerized environment.
In this article we will cover the following:
- Cover some basics about working with MySql , it’s always good to cover some basics on managing a database generally and MySql, particularly as this, is the chosen database type for this article
- Understand why we need to use a MySql Docker image , we will also cover how to create a container from said image and what environment variables we need to set, for it to work
- Learn how to connect to our MySql container , from our application container using linking, this is about realizing how to do basic linking between two containers and how this can be used to our advantage when defining the database startup configuration
- Expand our knowledge on linking , by covering the new way to link containers, there are two ways of doing linking, one way is more preferred than the other, which is deprecated, so we will cover how the new way of doing things is done
- Describe some good ways of managing our database , such as giving it an initial structure and seed it
Working with databases in general and MySql in particular
With databases in general we want to be able to do the following:
- read , we want to be able to read the data by using different kinds of queries
- alter/create/delete , we need to be able to change the data
- add structure , we need a way to create a structure like tables or collections so our data is saved in a specific format
- add seed/initial data , in a simple database this might not be needed at all but in more complex scenario you would need some tables to be prepopulated with some basic data. Having a seed is also great to have under the development phase as it makes it easy to render certain view or test different scenarios if there is already pre existing data or that the data is put in a certain state, e.g a shopping cart has items and you want to test the checkout page.
There are many more things we want to do to a database like adding indexes, adding users with different access rights and much much more but let’s focus on these four points above as a references for what we, with the help of Docker should be able to support.
Installing and connecting to MySql
There are tons of ways to install MySql not all of them are fast :/. One of the easier ways on a Linux system is typing the following:
sudo apt-get install mysql-server
On a Mac you would be using brew and then instead type:
brew install mysql
In some other scenarios you are able to download an installer package and follow a wizard.
Once you are done installing MySql you will get some information similar to this, this will of course differ per installation package:

The above tells us we don’t have a root password yet, YIKES. We can fix that though by running mysql-secure-installation . Let’s for now just connect to the database running the suggested mysql -uroot .

NOOO, what happened? We actually got this information in the larger image above, we needed to start MySql either by running brew services start mysql , which would run it as a background service or using mysql-server start which is more of a one off. Ok, let’s enter brew services start :

The very last thing is it says Successfully started mysql :

Let’s see if Matthew is correct, can we connect ?

And we get a prompt above mysql>, we are in :D
Ok so we managed to connect using NO password, we should fix that and we dont have any database created, we should fix that too :)
Well it’s not entirely true, we do have some databases, not just any databases with content created by yourself, but rather supportive ones that we shouldn’t touch:

So next up would be to create and select the newly created database, so we can query from it:

Ok, great, but wait, we don’t have any tables? True true, we need to create those somehow. We could be creating them in the terminal but that would just be painful, lots and lots of multiline statements, so let’s see if we can feed MySql a file with the database and all the tables we want in it. Let’s first define a file that we can keep adding tables to:
// database.sql
// creates a table `tasks`
CREATE TABLE IF NOT EXISTS tasks (
task_id INT AUTO_INCREMENT,
title VARCHAR(255) NOT NULL,
start_date DATE,
due_date DATE,
status TINYINT NOT NULL,
priority TINYINT NOT NULL,
description TEXT,
PRIMARY KEY (task_id)
);
// add more tables below and indeces etc as our solution grows
Ok then, we have a file with database structure, now for getting the content in there we can use the source command like so ( masking over the user name):

If you want the full path to where your file is located just type PWD where your file is at and type source [path to sql file]/database.sql. As you can see above, we need to select a database before we run our SQL file so it targets a specific database and then we verify that the table has been created with SHOW TABLES; We can also use the same command to seed our database with data, we just give it a different file to process, one containing INSERT statements rather than CREATE TABLE…
Ok then. I think that’s enough MySql for now, let’s talk MySql in the context of Docker next.
Why we need a MySql Docker image and how to get it up and running as a container
Ok so let’s now say we want a container for our application. Let’s furthermore say that our solution needs a database. It wouldn’t make much sense to install MySql on the host the computer is running on. I mean one of the mantras of containers is that we shouldn’t have to care about the the host system the containers are running on. Ok so we need MySql in a container, but which container, the apps own container or a separate container? That’s a good question depending on your situation, you could either install MySql with your app or run it in a separate container. Some argument for that is:
- rolling updates, your database can be kept online while your application nodes do individual restarts, you won’t experience downtime.
- scalability, you can add nodes to scale in a loosely coupled fashion
There are a lot of arguments for and against and only you know exactly what works best for you — so you do you :)
MySql as stand alone image
Let’s talk about the scenario in which we pull down a MySql image. Ok, we will take this step by step so first thing we do is try to run it and as we learned from previous articles the image will be pulled down for us if we don’t have it, so here is the command:
docker run --name=mysql-db mysql
Ok, so what’s the output of that?
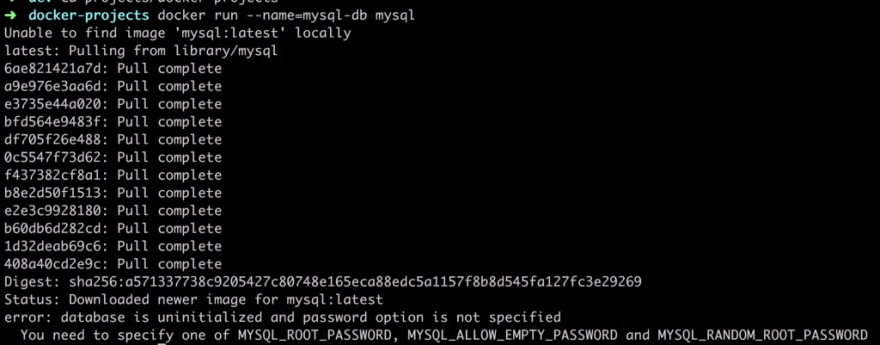
Pulling down the image, good, aaaand error.
We are doing all kinds of wrong :(.
Database is uninitialized, password option is not specified and so on. Let’s see if we can fix that:
docker run --name mysql-db -e MYSQL_ROOT_PASSWORD=complexpassword -d -p 8000:3306 mysql
and the winner is:

Argh, our container we started before is up and running despite the error message it threw. Ok, let’s bring down the container:
docker rm mysql-db
and let’s try to run it again with the database set like above:

Ok, we don’t get a whole bunch of logging to the terminal, because we are running in Daemon mode so let’s run docker ps to check:

At this point we want to connect to it from the outside. Our port forwarding means we need to connect to it on 0.0.0.0:8001 :
mysql -uroot -pcomplexpassword -h 0.0.0.0 -P 8001
Ok, just a comment above we can either specify the password or just write -p and we will be prompted for the password on the next row. Let’s have a look at the result:

Ok, we managed to connect to our database, it is reachable, great :).
But wait, can we reach a database, inside of container, from another container? Well here is where it gets tricky. This is where we need to link the two containers.
Connecting to database from Node.js
Ok let’s first add some code in our app that tries to connect to our database. First off we need to install the NPM package for mysql :
npm install mysql
Then we add the following code to the top of our app.js file:
// app.js
const mysql = require('mysql');
const con = mysql.createConnection({
host: "localhost",
port: 8001,
user: "root",
password: "complexpassword",
database: 'Customers'
});
con.connect(function (err) {
if (err) throw err;
console.log("Connected!");
});
So let’s try this in the terminal:

Pain and misery :(
So why won’t it work.
This is because caching_sha2_password is introduced in MySQL 8.0, but the Node.js version is not implemented yet.
Ok so what, we try Postgres or some other database? Well we can actually fix this by connecting to our container like so:
mysql -uroot -pcomplexpassword -h 0.0.0.0 -P 8001
and once we are at the mysql prompt we can type the following:
mysql> ALTER USER 'root' IDENTIFIED WITH mysql_native_password BY 'complexpassword';
mysql> FLUSH PRIVILEGES;
Let’s try to run our node app.js command again and this time we get this:

Finally!
Ok, so some call to this mysql_native_password seems to fix to whole thing. Let’s go deeper into the rabbit hole, what is that?
MySQL includes a mysql_native_password plugin that implements native authentication; that is, authentication based on the password hashing method in use from before the introduction of pluggable authentication
Ok, so that means MySql 8 have switched to some new pluggable authentication that our Node.js mysql library hasn’t been able to catch up on. That means we can either pull down an earlier version of MySql or revert to native authentication, your call :)
Linking
The idea of linking is that a container shouldn’t have to know any details on what IP or PORT the database, in this case, is running on. It should just assume that for example the app container and the database container can reach each other. A typical syntax looks like this:
docker run -d -p 5000:5000 --name product-service –link mypostgres:postgres chrisnoring/node
Let’s break the above down a bit:
- app container, we are creating an app container called product-service
- –link we are calling this command to link our product-service container with the existing mypostgres container
- link alias, the statement --link mypostgres:postgres means that we specify what container to link with mypostgres and gives it an alias
postgres. We will use this alias internally inproduct-servicecontainer when we try to connect to our database
Ok, so we think we kind of get the basics of linking, let’s see how that applies to our existing my-container and how we can link it to our database container mysql-db. Well because we started my-container without linking it we need to tear it down and restart it with our --link command specified as an additional argument like so:
docker kill my-container && docker rm my-container
That brings down the container. Before we bring it up though, we actually need to change some code, namely the part that has to do with connecting to our database. We are about to link it with our database container using the --link mysql-db:mysql argument which means we no longer need the IP or the PORT reference so our connection code can now look like this:
// part of app.js, the rest omitted for brevity
const con = mysql.createConnection({
**host: "mysql",**
user: "root",
password: "complexpassword",
database: 'Customers'
});
// and the rest of the code below
The difference is now our host is no longer stating localhost and the port is not explicitly stating 8001 cause the linking figures that out, all we need to focus on is knowing what alias we gave the database container when we linked e.g mysql. Because we both changed the code and we added another library myql we will need to rebuild the image, like so:
docker build - t chrisnoring/node .
now let’s get it started again, this time with a link:
docker run -d -p 8000:3000 --name my-container --link mysql-db:mysql chrisnoring/node
and let’s have a look at the output:

We use the docker logs my-container to see the logs from our app container and the very last line says Connected! which comes from the callback function that tells us we successfully connected to MySql.
You know what time it is ? BOOOM!

Expand our knowledge on linking — there is another way
Ok, so this is all well and good. We managed to place the application in one container and the database in another container. But… This linking we just looked at is considered legacy which means we need to learn another way of doing linking. Wait… It’s not as bad as you think, it actually looks better syntactically.
This new way of doing this is called creating networks or custom bridge networks. Actually, that’s just one type of network we can create. The point is that they are dedicated groups that you can say that your container should belong to. A container can exist in multiple networks if it has cross cutting concerrns for more than one group. That all sounds great so show me some syntax right?
The first thing we need to do is to create the network we want the app container and database container to belong to. We create said network with the following command:
docker network create --driver bridge isolated_network
Now that we have our network we just need to create each container with the newly created network as an additional argument. Let’s start with the app container:
docker run -d -p 8000:3000 –net isolated_network --name my-container chrisnoring-node
Above we are now using the --net syntax to create a network that we call isolated_network and the rest is just the usual syntax we use to create and run our container. That was easy :)
What about the database container?
docker run -p 8000:3306 –net isolated_network --name mysql-db -e MYSQL_ROOT_PASSWORD=complexpassword -d mysql
As you can see above we just create and run our database container but with the added --net isolated_network .
Looking back at this way of doing it, we no longer need to explicitly say that one container needs to be actively linked to another, we only place a container in a specific network and the containers in that network knows how to talk to each other.
There is a lot more to learn about networks, there are different types and a whole host of commands. I do think we got the gist of it, e.g how it differs from legacy linking. Have a look at this link to learn more docs on networking
General database management in a container setting
Ok, so we talked at the beginning of this section how we can create the database structure as a file and how we even can create our seed data as a file and how we can run those once we are at the MySql prompt after we connected to it. Here is the thing. How we get that structure and seed data in there is a little bit up to you but I will try to convey some general guidelines and ideas:
- structure, you want to run this file at some point. To get in into the database you can either connect using the
mysqlclient and refer to the file being outside in the host computer. Or you can place this file as part of your app repo and just let the Dockerfile copy the file into the container and then run it. Another way is looking at libraries such as Knex or Sequelize that supports migrations and specify the database structure in migrations that are being run. This is a bit different topic all together but I just wanted to show that there are different ways for you to handle this - seed, you can treat the seed the same way as you do the structure. This is something that needs to happen after we get our structure in and it is a one-off. It’s not something you want to happen at every start of the app or the database and depending on whether the seed is just some basic structural data or some data you need for testing purposes you most likely want to do this manually, e.g you connect to
mysqlusing the client and actively runs the source command
Summary Part III
Ok, this article managed to cover some general information on MySql and discussed how we could get some structural things in there like tables and we also talked about an initial/test seed and how to get it into the database using standalone files.
Then we discussed why we should run databases in Docker container rather than installed on the host and went on to show how we could get two containers to talk to each other using a legacy linking technique. We did also spend some time cursing at MySql 8 and the fact the mysql Node.js module is not in sync which forced us to fix it.
Once we covered the legacy linking bit we couldn’t really stop there but we needed to talk about the new way we link containers, namely using networks.
Learn Docker from Beginner to Advanced Part IV
This part is about dealing with more than two Docker containers. You will come to a point eventually when you have so many containers to manage it feels unmanageable. You can only keep typing docker run to a certain point, as soon as you start spinning up multiple containers it just hurts your head and your fingers. To solve this we have Docker Compose.
TLDR; Docker Compose is a huge topic, for that reason this article is split into two parts. In this part, we will describe why Docker Compose and show when it shines. In the second part on Docker Compose we will cover more advanced topics like Environment Variables, Volumes and Databases.
In this part we will cover:
- Why docker compose, it’s important to understand, at least on a high level that there are two major architectures Monolith and Microservices and that Docker Compose really helps with managing the latter
- Features, we will explain what feature Docker Compose supports so we will come to understand why it’s such a good fit for our chosen Microservice architecture
- When Docker isn’t enough, we will explain at which point using Docker commands becomes tedious and painful and when using Docker Compose is starting to look more and more enticing
- In action, lastly we will build a docker-compose.yaml file from scratch and learn how to manage our containers using Docker Compose and some core commands
Why Docker Compose
Docker Compose is meant to be used when we need to manage many services independently. What we are describing is something called a microservice architecture.
Microservice architecture
Let’s define some properties on such an architecture:
- Loosely coupled, this means they are not dependent on another service to function, all the data they need is just there. They can interact with other services though but that’s by calling their external API with for example an HTTP call
- Independently deployable, this means we can start, stop and rebuild them without affecting other services directly.
- Highly maintainable and testable, services are small and thus there is less to understand and because there are no dependencies testing becomes simpler
- Organized around business capabilities, this means we should try to find different themes like booking, products management, billing and so on
We should maybe have started with the question of why we want this architecture? It’s clear from the properties listed above that it offers a lot of flexibility, it has less to no dependencies and so on. That sounds like all good things, so is that the new architecture that all apps should have?
As always it depends. There are some criteria where Microservices will shine as opposed to a Monolithic architecture such as:
- Different tech stacks/emerging techs, we have many development teams and they all want to use their own tech stack or want to try out a new tech without having to change the entire app. Let each team build their own service in their chosen tech as part of a Microservice architecture.
- Reuse, you really want to build a certain capability once, like for example billing, if that’s being broken out in a separate service it makes it easier to reuse for other applications. Oh and in a microservices architecture you could easily combine different services and create many apps from it
- Minimal failure impact, when there is a failure in a monolithic architecture it might bring down the entire app, with microservices you might be able to shield yourself better from failure
There are a ton more arguments on why Micro services over Monolithic architecture. The interested reader is urged to have a look at the following link .
The case for Docker Compose
The description of a Microservice architecture tells us that we need a bunch of services organized around business capabilities. Furthermore, they need to be independently deployable and we need to be able to use different tech stacks and many more things. In my opinion, this sounds like Docker would be a great fit generally. The reason we are making a case for Docker Compose over Docker is simply the sheer size of it. If we have more than two containers the amount of commands we need to type suddenly grows in a linear way. Let’s explain in the next section what features Docker Compose have that makes it scale so well when the number of services increase.
Docker Compose features overview
Now Docker Compose enables us to scale really well in the sense that we can easily build several images at once, start several containers and many more things. A complete listing of features is as follows:
- Manages the whole application life cycle.
- Start, stop and rebuild services
- View the status of running services
- Stream the log output of running services
- Run a one-off command on a service
As we can see it takes care of everything we could possibly need when we need to manage a microservice architecture consisting of many services.
When plain Docker isn’t enough anymore
Let’s recap on how Docker operates and what commands we need and let’s see where that takes us when we add a service or two.
To dockerize something, we know that we need to:
- define a Dockerfile that contains what OS image we need, what libraries we need to install, env variables we need to set, ports that need opening and lastly how to - start up our service
- build an image or pull down an existing image from Docker Hub
- create and run a container
Now, using Docker Compose we still need to do the part with the Dockerfile but Docker Compose will take care of building the images and managing the containers. Let’s illustrate what the commands might look like with plain Docker:
docker build -t some-image-name .
Followed by
docker run -d -p 8000:3000 --name some-container-name some-image-name
Now that’s not a terrible amount to write, but imagine you have three different services you need to do this for, then it suddenly becomes six commands and then you have the tear down which is two more commands and, that doesn’t really scale.

Enter docker-compose.yaml
This is where Docker Compose really shines. Instead of typing two commands for every service you want to build you can define all services in your project in one file, a file we call docker-compose.yaml. You can configure the following topics inside of a docker-compose.yaml file:
- Build, we can specify the building context and the name of the Dockerfile, should it not be called the standard name
- Environment, we can define and give value to as many environment variables as we need
- Image, instead of building images from scratch we can define ready-made images that we want to pull down from Docker Hub and use in our solution
- Networks, we can create networks and we can also for each service specify which network it should belong to, if any
- Ports, we can also define the port forwarding, that is which external port should match what internal port in the container
- Volumes, of course, we can also define volumes
Docker compose in action
Ok so at this point we understand that Docker Compose can take care of pretty much anything we can do on the command line and that it also relies on a file docker-compose.yaml to know what actions to carry out.
Authoring a docker-compose.yml file
Let’s actually try to create such a file and let’s give it some instructions. First, though let’s do a quick review of a typical projects file structure. Below we have a project consisting of two services, each having their own directory. Each directory has a Dockerfile that contains instructions on how to build a service.
It can look something like this:
docker-compose.yaml
/product-service
app.js
package.json
Dockerfile
/inventory-service
app.js
package.json
Dockerfile
Worth noting above is how we create the docker-compose.yaml file at the root of our project. The reason for doing so is that all the services we aim to build and how to build and start them should be defined in one file, our docker-compose.yml.
Ok, let’s open docker-compose.yaml and enter our first line:
// docker-compose.yaml
version: '3'
Now, it actually matters what you specify here. Currently, Docker supports three different major versions. 3 is the latest major version, read more here how the different versions differ, cause they do support different functionality and the syntax might even differ between them Docker versions offical docs
Next up let’s define our services:
// docker-compose.yaml
version: '3'
services:
product-service:
build:
context: ./product-service
ports:
- "8000:3000"
Ok, that was a lot at once, let’s break it down:
- services:, there should only be one of this in the whole docker-compose.yaml file. Also, note how we end with
:, we need that or it won’t be valid syntax, that is generally true for any command - product-service, this is a name we choose ourselves for our service
- build:, this is instructing Docker Compose how to build the image. If we have a ready-made image already we don’t need to specify this one
- context:, this is needed to tell Docker Compose where our
Dockerfileis, in this case, we say that it needs to go down a level to theproduct-servicedirectory - ports:, this is the port forwarding in which we first specify the external port followed by the internal port
All this corresponds to the following two commands:
docker build -t [default name]/product-service .
docker run -p 8000:3000 --name [default name]/product-service
Well, it’s almost true, we haven’t exactly told Docker Compose yet to carry out the building of the image or to create and run a container. Let’s learn how to do that starting with how to build an image:
docker-compose build
The above will build every single service you have specified in docker-compose.yaml. Let’s look at the output of our command:

Above we can see that our image is being built and we also see it is given the full name compose-experiments_product-service:latest, as indicated by the last row. The name is derived from the directory we are in, that is compose-experiments and the other part is the name we give the service in the docker-compose.yaml file.
Ok as for spinning it up we type:
docker-compose up
This will again read our docker-compose.yaml file but this time it will create and run a container. Let’s also make sure we run our container in the background so we add the flag -d, so full command is now:
docker-compose up -d
Ok, above we can see that our service is being created. Let’s run docker ps to verify the status of our newly created container:
It seems to be up and running on port 8000. Let’s verify:
Ok, so went to the terminal and we can see we got a container. We know we can bring it down with either docker stop or docker kill but let’s do it the docker-compose way:
docker-compose down
As we can see above the logs is saying that it is stopping and removing the container, it seems to be doing both docker stop [id] and docker rm [id] for us, sweet :)
It should be said if all we want to do is stop the containers we can do so with:
docker-compose stop
I don’t know about you but at this point, I’m ready to stop using docker build, docker run, docker stop and docker rm. Docker compose seems to take care of the full life cycle :)
Docker compose showing off
Let’s do a small recap so far. Docker compose takes care of the full life cycle of managing services for us. Let’s try to list the most used Docker commands and what the corresponding command in Docker Compose would look like:
docker buildbecomesdocker-compose build, the Docker Compose version is able to build all the services specified indocker-compose.yamlbut we can also specify it to build a single service, so we can have more granular control if we want todocker build + docker runbecomesdocker-compose up, this does a lot of things at once, if your images aren’t built previously it will build them and it will also create containers from the imagesdocker stopbecomesdocker-compose stop, this is again a command that in Docker Compose can be used to stop all the containers or a specific one if we give it a single container as an argumentdocker stop && docker rmbecomesdocker-compose down, this will bring down the containers by first stopping them and then removing them so we can start fresh
The above in itself is pretty great but what’s even greater is how easy it is to keep on expanding our solution and add more and more services to it.
Building out our solution
Let’s add another service, just to see how easy it is and how well it scales. We need to do the following:
- add a new service entry in our
docker-compose.yaml - build our image/s
docker-compose build - run
docker-compose up
Let’s have a look at our docker-compose.yaml file and let’s add the necessary info for our next service:
// docker-compose.yaml
version: '3'
services:
product-service:
build:
context: ./product-service
ports:
- "8000:3000"
inventory-service:
build:
context: ./inventory-service
ports:
- "8001:3000"
Ok then, let’s get these containers up and running, including our new service:
docker-compose up
Wait, aren’t you supposed to run docker-compose build ? Well, actually we don’t need to docker-compose up does it all for us, building images, creating and running containers.

CAVEAT, it’s not so simple, that works fine for a first-time build + run, where no images exist previously. If you are doing a change to a service, however, that needs to be rebuilt, that would mean you need to run docker-compose build first and then you need to run docker-compose up.
Summary Part IV
Here is where we need to put a stop to the first half of covering Docker Compose, otherwise it would just be too much. We have been able to cover the motivation behind Docker Compose and we got a lightweight explanation to Microservice architecture. Furthermore, we talked about Docker versus Docker Compose and finally, we were able to contrast and compare the Docker Compose command to plain Docker commands.
Thereby we hopefully were able to show how much easier it is to use Docker Compose and specify all your services in a docker-compose.yaml file.
Learn Docker from Beginner to Advanced Part V
We will keep working on our project introduced in Part IV and in doing so we will showcase more Docker Compose features and essentially build out our project to cover everything you might possibly need.
In this part, we will cover:
- Environment variables , now we have covered those in previous parts so this is mostly about how we set them in Docker Compose
- Volumes , same thing with volumes, this has been covered in previous articles even though we will mention their use and how to work with them with Docker Compose
- Networks and Databases , finally we will cover Databases and Networks, this part is a bit tricky but hopefully, we managed to explain it thoroughly
If you at any point should feel confused here is the repo this article is based on:
Environment variables
One of the things I’ve shown you in previous articles is how we can specify environment variables. Now variables can be set in the Dockerfile but we can definitely set them on the command line and thereby also in Docker Compose and specifically in docker-compose.yaml:
// docker-compose.yaml
version: '3'
services:
product-service:
build:
context: ./product-service
ports:
- "8000:3000"
environment:
- test=testvalue
inventory-service:
build:
context: ./inventory-service
ports:
- "8001:3000"
Above we are creating an environment variable by defining environment followed by -test=testvalue, which means we create the variable test with value, testvalue.
We can easily test that this works by reading from process.env.test in our app.js file for the product-service directory.
Another way to test this is to run Docker compose and query for what environment variables are available, like so:
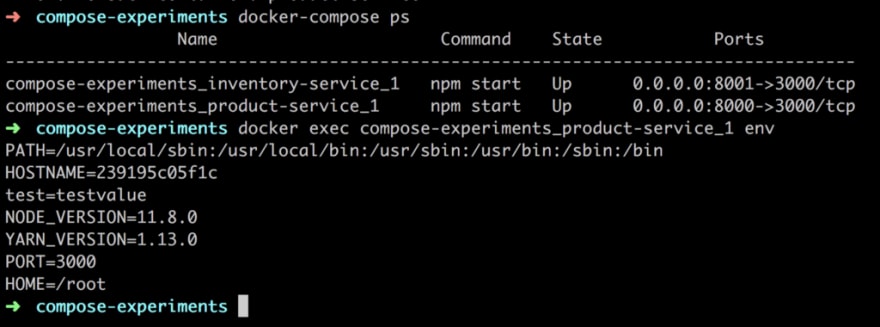
As you can see above we first run docker-compose ps and get the containers that are part of this Docker Compose session and then we run docker exec [container name] env to list the environment variables. A third option is to run docker exec -it [container name] bash and enter the container and use bash to echo out the variable value. There are quite a few ways to manage environment variables with Docker compose so have a read in the official docs, what else you can do.
Volumes
We’ve covered volumes in an earlier part of this series and we found them to be a great way to:
- create a persistent space , this is ideal to create log files or output from a Database that we want to remain, once we tear down and run our containers
- turn our development environment into a Volume , the benefits of doing so meant that we could start up a container and then change our code and see those changes reflected without having to rebuild or tear down our container, a real time saver.
Create a persistent space
Let’s see how we can deal with Volumes in Docker compose:
// docker-compose.yml
version: '3'
services:
product-service:
build:
context: ./product-service
ports:
- "8000:3000"
environment:
- test=testvalue
inventory-service:
build:
context: ./inventory-service
ports:
- "8001:3000"
volumes:
- my-volume:/var/lib/data
volumes:
my-volume:
Above we are creating a volume by the command volumes at the end of the file and on the second row we give it the name my-volume. Furthermore, in the inventory-service portion of our file, we refer to the just created volume and create a mapping to /var/lib/data which is a directory in the volume that will be persisted, through teardowns. Let’s look that it is correctly mapped:
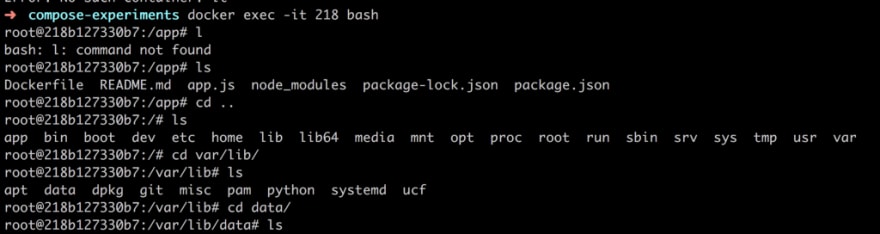
As can be seen, by the above command, we first enter the container with docker exec followed by us navigating to our mapping directory, it is there, great :).
Let’s create a file in the data directory so we can prove that our volume mapping really works:
echo persist > persist.log
The above command creates a file persist.log with the content persist . Nothing fancy but it does create a file that we can look for after tearing down and restarting our container.
Now we can exit the container. Next, let’s recap on some useful Volume commands:
docker volume ls

The above lists all the currently mounted volumes. We can see that our created Volume is there compose-experiments_my-volume .
We can dive into more details with:
docker volume inspect compose-experiments_my-volume
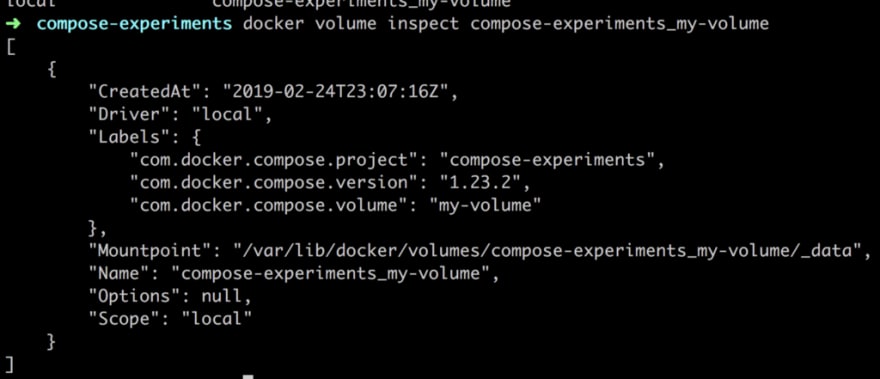
Ok, so it’s giving us some details about our volume such as Mountpoint, which is where files will be persisted when we write to our volume mapping directory in the container.
Let’s now bring down our containers with:
docker-compose down
This means that the Volume should still be there so let’s bring them all up with:
docker-compose up -d
Let’s enter the container next and see if our persist.log file is there:
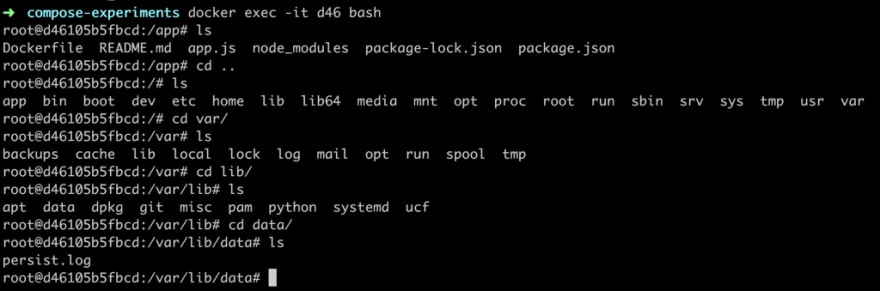
Oh yeah, it works.
Turn your current directory into a Volume
Ok, for this we need to add a new volume and we need to point out a directory on our computer and a place in the container that should be in sync. Your docker-compose.yaml file should look like the following:
// docker-compose.yaml
version: '3'
services:
product-service:
build:
context: ./product-service
ports:
- "8000:3000"
environment:
- test=testvalue
volumes:
- type: bind
source: ./product-service
target: /app
inventory-service:
build:
context: ./inventory-service
ports:
- "8001:3000"
volumes:
- my-volume:/var/lib/data
volumes:
my-volume:
The new addition is added to the product-service. We can see that we are specifying a volumes command with one entry. Let’s break down that entry:
- type: bind , this creates a so-called bind mount, a type of volume more fit for purpose of syncing files between your local directory and your container
- source , this is simply where your files are, as you can see we are pointing out
./product-service. This means that as soon as we change a file under that directory Docker will pick up on it. - target , this is the directory in the container, source and target will now be in sync we do a change in source, the same change will happen to target
Networks and databases
Ok then, this is the last part we aim to cover in this article. Let’s start with databases. All major vendors have a Docker image like Sql Server, Postgres, MySQL and so on. This means we don’t need to do the build-step to get them up and running but we do need to set things like environment variables and of course open up ports so we can interact with them. Let’s have a look at how we can add a MySQL database to our solution, that is our docker-compose.yml file.
Adding a database
Adding a database to docker-compose.yaml is about adding an already premade image. Lucky for us MySQL already provides a ready-made one. To add it we just need to add another entry under services: like so:
// docker-compose.yaml
product-db:
image: mysql
environment:
- MYSQL_ROOT_PASSWORD=complexpassword
ports:
- 8002:3306
Let’s break it down:
product-dbis the name of our new service entry, we choose this nameimageis a new command that we are using instead of build , we use this when the image is already built, which is true for most databasesenvironment, most databases will need to have a certain number of variables set to be able to connect to them like username, password and potentially the name of the database, this varies per type of database. In this case, we set MYSQL_ROOT_PASSWORD so we instruct the MySQL instance what the password is for the root user. We should consider creating a number of users with varying access levels- ports, this is exposing the ports that will be open and thereby this is our entrance in for talking to the database. By typing
8002:3306we say that the container’s port3306should be mapped to the external port8002
Let’s see if we can get the database and the rest of our services up and running:
docker-compose up -d

Let’s verify with:
docker-compose ps OR docker ps

Looks, good, our database service experiments_product-db_1 seems to be up and running on port 8002. Let’s see if we can connect to the database next. The below command will connect us to the database, fingers crossed ;)
mysql -uroot -pcomplexpassword -h 0.0.0.0 -P 8002

and the winner is…

Great, we did it. Next up let’s see if we can update one of our services to connect to the database.
Connecting to the database
There are three major ways we could be connecting to the database:
- using docker client, we’ve tried this one already with
mysql -uroot -pcomplexpassword -h 0.0.0.0 -P 8002 - enter our container, we do this using
docker exec -it [name of container] bashand then we typemysqlinside of the container - connecting through our app, this is what we will look at next using the NPM library mysql
We will focus on the third choice, connecting to a database through our app. The database and the app will exist in different containers. So how do we get them to connect? The answer is:
- needs to be in the same network , for two containers to talk to each other they need to be in the same network
- database needs to be ready , it takes a while to start up a database and for your app to be able to talk to the database you need to ensure the database have started up correctly, this was a fun/interesting/painful til I figured it out, so don’t worry I got you, we will succeed :)
- create a connection object , ensure we set up the connection object correctly in
app.jsforproduct-service
Let’s start with the first item here. How do we get the database and the container into the same network? Easy, we create a network and we place each container in that network. Let’s show this in docker-compose.yaml:
// excerpt from docker-compose.yaml
networks:
products:
We need to assign this network to each service, like so:
// excerpt from docker-compose.yaml
services:
some-service:
networks:
- products
Now, for the second bullet point, how do we know that the database is finished initializing? Well, we do have a property called depends_on, with that property, we are able to specify that one container should wait for another container to start up first. That means we can specify it like so:
// excerpt from docker-compose.yaml
services:
some-service:
depends_on: db
db:
image: mysql
Great so that solves it or? Nope nope nope, hold your horses:

So in Docker compose version 2 there used to be an alternative where we could check for a service’s health, if health was good we could process to spin up our container. It looked like so:
depends_on:
db:
condition: service_healthy
This meant that we could wait for a database to initialize fully. This was not to last though, in version 3 this option is gone. Here is doc page that explains why, control startup and shutdown order. The gist of it is that now it’s up to us to find out when our database is done and ready to connect to. Docker suggests several scripts for this:
All these scripts have one thing in common, the idea is to listen to a specific host and port and when that replies back, then we run our app. So what do we need to do to make that work? Well let’s pick one of these scripts, namely wait-for-it and let’s list what we need to do:
- copy this script into your service container
- give the script execution rights
- instruct the docker file to run the script with database host and port as args and then to run the service once the script OKs it
Let’s start with copying the script from GitHub into our product-service directory so it now looks like this:
/product-service
wait-for-it.sh
Dockerfile
app.js
package.json
Now let’s open up the Dockerfile and add the following:
// Dockerfile
FROM node:latest
WORKDIR /app
ENV PORT=3000
COPY . .
RUN npm install
EXPOSE $PORT
COPY wait-for-it.sh /wait-for-it.sh
RUN chmod +x /wait-for-it.sh
Above we are copying the wait-for-it.sh file to our container and on the line below we are giving it execution rights. Worth noting is how we also remove the ENTRYPOINT from our Dockerfile, we will instead instruct the container to start from the docker-compose.yaml file. Let’s have a look at said file next:
// excerpt from docker-compose.yaml
services:
product-service:
command: ["/wait-for-it.sh", "db:8002", "--", "npm", "start"]
db:
// definition of db service below
Above we are telling it to run the wait-for-it.sh file and as an argument use db:8002 and after it gets a satisfactory response then we can go on to run npm start which will then start up our service. That sounds nice, will it work?
For full disclosure let’s show our full docker-compose.yaml file:
version: '3.3'
services:
product-service:
depends_on:
- "db"
build:
context: ./product-service
command: ["/wait-for-it.sh", "db:8002", "--", "npm", "start"]
ports:
- "8000:3000"
environment:
- test=testvalue
- DATABASE_PASSWORD=complexpassword
- DATABASE_HOST=db
volumes:
- type: bind
source: ./product-service
target: /app
networks:
- products
db:
build: ./product-db
restart: always
environment:
- "MYSQL_ROOT_PASSWORD=complexpassword"
- "MYSQL_DATABASE=Products"
ports:
- "8002:3306"
networks:
- products
inventory-service:
build:
context: ./inventory-service
ports:
- "8001:3000"
volumes:
- my-volume:/var/lib/data
volumes:
my-volume:
networks:
products:
Ok, so to recap we placed product-service and db in the network products and we downloaded the script wait-for-it.sh and we told it to run before we spun up the app and in the process listen for the host and port of the database that would respond as soon as the database was ready for action. That means we have one step left to do, we need to adjust the app.js file of the product-service, so let’s open that file up:
// app.js
const express = require('express')
const mysql = require('mysql');
const app = express()
const port = process.env.PORT || 3000;
const test = process.env.test;
let attempts = 0;
const seconds = 1000;
function connect() {
attempts++;
console.log('password', process.env.DATABASE_PASSWORD);
console.log('host', process.env.DATABASE_HOST);
console.log(`attempting to connect to DB time: ${attempts}`);
const con = mysql.createConnection({
host: process.env.DATABASE_HOST,
user: "root",
password: process.env.DATABASE_PASSWORD,
database: 'Products'
});
con.connect(function (err) {
if (err) {
console.log("Error", err);
setTimeout(connect, 30 * seconds);
} else {
console.log('CONNECTED!');
}
});
conn.on('error', function(err) {
if(err) {
console.log('shit happened :)');
connect()
}
});
}
connect();
app.get('/', (req, res) => res.send(`Hello product service, changed ${test}`))
app.listen(port, () => console.log(`Example app listening on port ${port}!`))
Above we can see that we have defined a connect() method that creates a connection by invoking createConnection() with an object as an argument. That input argument needs to know host, user, password and database. That seems perfectly reasonable. We also add a bit of logic to the connect() method call namely we invoke setTimeout(), this means that it will attempt to do another connection after 30 seconds. Now, because we use wait-for-it.sh that functionality isn’t really needed but we could rely on application code alone to ensure we get a connection. However, we also call conn.on('error') and the reason for doing so is that we can loose a connection and we should be good citizens and ensure we can get that connection back.
Anyway, we’ve done everything in our power, but because we’ve introduced changes to Dockerfile let’s rebuild everything with docker-compose build and then let’s bring everything up with:
docker-compose up
and….
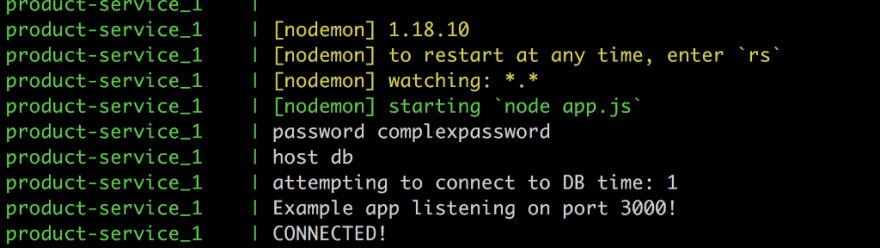
There it is, Houston WE HAVE A CONNECTION, or as my friend Barney likes to put it:

Setting up the database — fill it with structure and data
Ok, maybe you were wondering about the way we built the service db ? That part of docker-compose.yaml looked like this:
// docker-compose.yaml
db:
build: ./product-db
restart: always
environment:
- "MYSQL_ROOT_PASSWORD=complexpassword"
- "MYSQL_DATABASE=Products"
ports:
- "8002:3306"
networks:
- products
I would you to look at build especially. We mentioned at the beginning of this article that we can pull down ready-made images of databases. That statement is still true but by creating our own Dockerfile for this, we can not only specify the database we want but we can also run commands like creating our database structure and insert seed data. Let’s have a close look at the directory product-db:
/product-db
Dockerfile
init.sql
Ok, we have a Dockerfile, let’s look at that first:
// Dockerfile
FROM mysql:5.6
ADD init.sql /docker-entrypoint-initdb.d
We specify that init.sql should be copied and renamed to docker-entrypoint-initdb.d which means it will run the first thing that happens. Great, what about the content of init.sql?
// init.sql
CREATE DATABASE IF NOT EXISTS Products;
# create tables here
# add seed data inserts here
As you can see it doesn’t contain much for the moment but we can definitely expand it, which is important.
Summary Part V
We have now come full circle in this series, we have explained everything from the beginning. The basic concepts, the core commands, how to deal with volumes and databases and also how to be even more effective with Docker Compose. This series will continue of course and go deeper and deeper into Docker but this should hopefully take you a bit on the way. Thanks for reading this far.
#docker #devops #Kubernetes
