Contents:
- Which purpose for Variable Importance?
- 1.1Set your goal…
- 1.2 …By choosing a quadrant
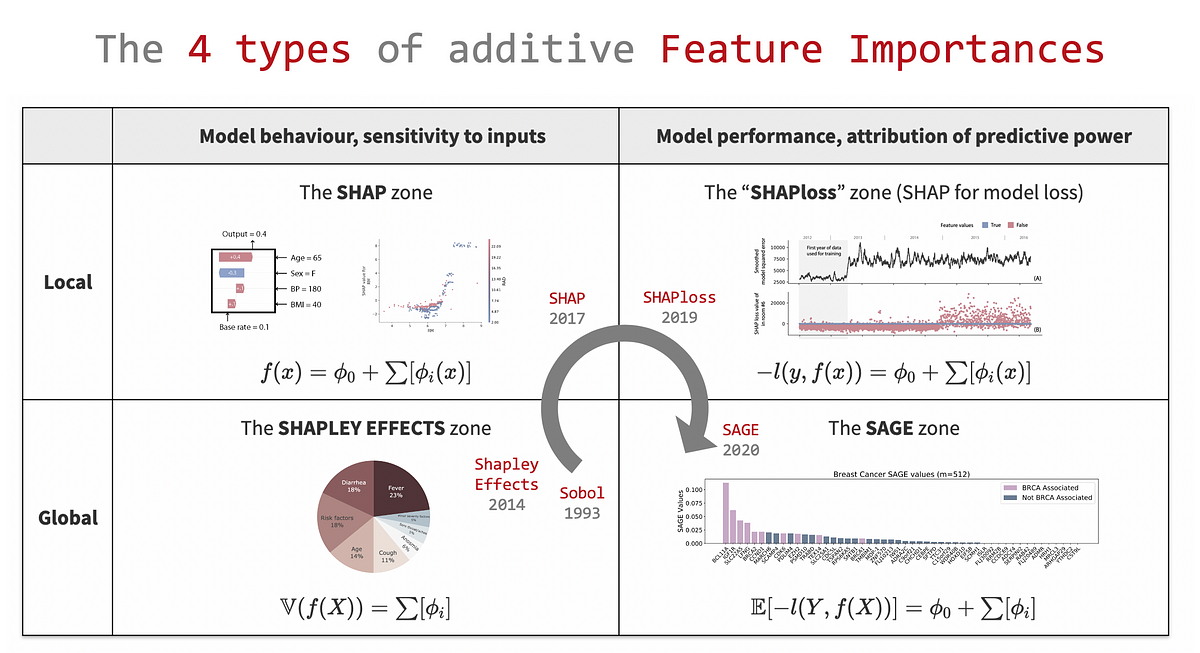
- The 4 purpose-oriented quadrants
- 2.1 The SHAPLEY EFFECTS zone
- 2.2 The SHAP zone
- 2.3 The SHAPloss zone
- 2.4 The SAGE zone
- A Shapley solution for each quadrant
- 3.1 Shapley values
- 3.2 Application to Feature Attribution
- Future perspectives and take-away messages
- References
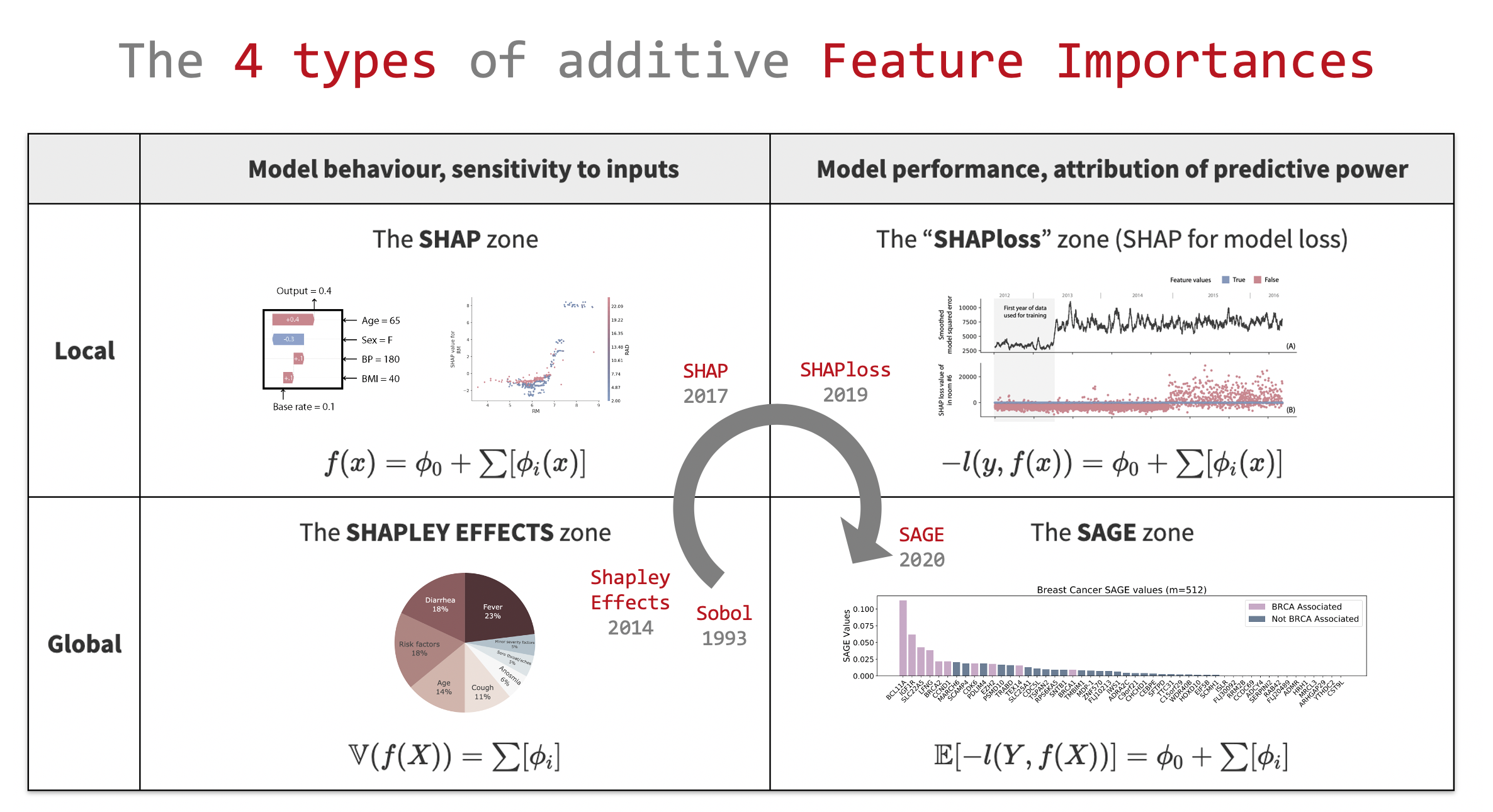
Overview of the 4 goal-oriented quadrants of additive Feature Importances, from datajms.com, courtesy of the author.
You have probably heard of Feature Importance methods: there are many of them around and they can be very useful for variable selection and model explanation. But there is more: the additive Variable Importance landscape has recently become structured and made systematically optimal.
This article is not just an other SHAP article, it presents similar notions which shares an important component: Shapley values. A structured 2 by 2 matrix is presented to better think about Variable Importances in terms of their goals and scopes. Focused on additive Feature attribution methods, the 4 identified quadrants are presented along with their “optimal” method: SHAP, SHAPLEY EFFECTS, SHAPloss and the very recent SAGE. Then, we will look into Shapley values and their properties, which make the 4 methods theoretically optimal. Finally, I will share my thoughts on the perspectives concerning Variable Importance methods.
1. Which purpose for Variable Importance?
So, what are Variable Importances and which properties should they have? We will focus on Variable Importances with the 2 following requirements:
- Feature attribution: Indicating how much a quantity of interest of our model f rely on each feature.
- Additive importance: Summing the importances should lead to a quantity that makes sense (typically the quantity of interest of model f).
While Feature attribution property is the essence of Variable Importance, the Additive importance requirement is more challenging. More well known Variable Importance methods break it: the Breiman Random Forest variable importance, Feature ablation, Permutation importance, etc. Let’s focus on Variable Importances with these 2 properties.
#data-science #shap #data analysis #data analysis