The series so far:
- Heaps in SQL Server: Part 1 The Basics
- Heaps in SQL Server: Part 2 Optimizing Reads
- Heaps in SQL Server: Part 3 Nonclustered Indexes
The previous article Heaps in SQL Server: Part 2 Optimizing Reads described how performance could be optimized for selecting data from a heap. This article describes the possibility of achieving optimal query times for heaps with the help of nonclustered indexes.
Nonclustered Index
A nonclustered index is an index structure that is separate from the data in the table. In this way, data can be found faster than with a search of the underlying table. In general, nonclustered indexes are created to improve the performance of frequently used queries that are not covered by the clustered index or heap.
Demonstration
Since a heap does not sort data according to a key attribute, a nonclustered index can only form a reference by using the position of the data record in the heap. The position of a data record in a heap is determined by three pieces of information:
- File number
- Data page
- Slot
These three pieces of information are stored as a reference in each Nonclustered index for the actual key of the index.
To follow along with the demos, see the article Heaps in SQL Server: Part 2 Optimizing Reads. A table with approximately 4,000,000 data records is used.
This table is very often accessed by users to display orders for a specific period. Since there is no index on the [OrderDate] attribute, a table scan must always be carried out.
SELECT * FROM dbo . CustomerOrderList
WHERE OrderDate = ‘20081220’
OPTION ( QUERYTRACEON 9130 );
GO
A table scan is used, as shown in the execution plan in Figure 1.
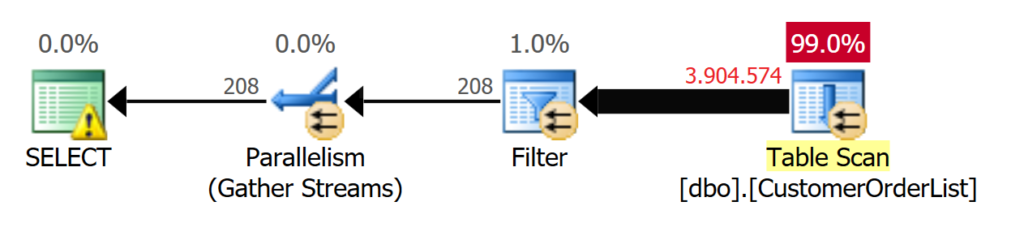
Figure 1: A TABLE SCAN is used for 208 records
The table scan may be sufficient on fast systems (0.716 seconds), and the programmer might be inclined to accept this time interval.
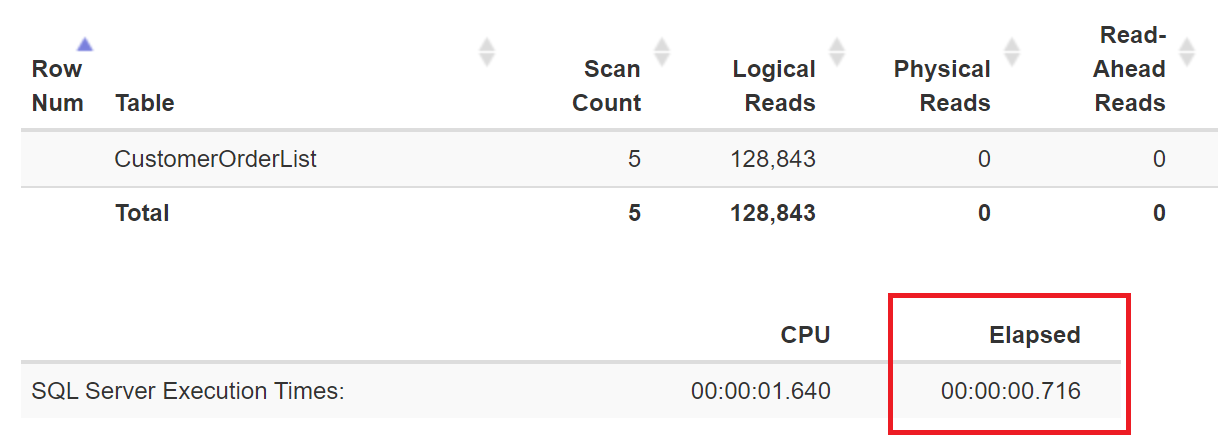
Figure 2: more than 1.6 seconds used on the CPU and 0.716 seconds elapsed
The high CPU time is due to the fact that the query uses parallel execution shown in Figure 3.
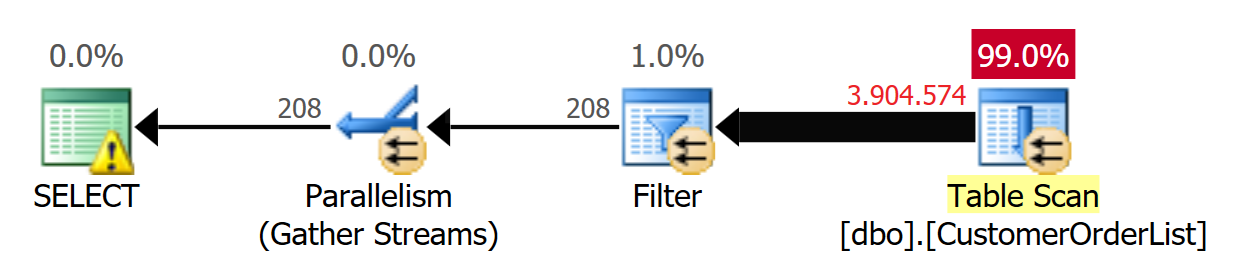
Figure 3: A parallel plan
Unfortunately, the following things are often disregarded, which are relevant regardless of the time:
- The query parallelizes and consumes the CPUs configured for MAXDOP!
- A [SCH-S] lock is kept on the table during the runtime! (See this article)
- What happens if not only one user runs the query, but there is also a web client running thousands of queries in parallel?
For the reasons mentioned above, it is advisable to optimize the query. To optimize the query, a Nonclustered index is created for the [OrderDate] attribute.
CREATE NONCLUSTERED INDEX nix_CustomerOrderList_OrderDate
ON dbo . CustomerOrderList ( OrderDate );
GO
If you rerun the same query as in the previous example, you will get the following improvements shown in Figure 4:
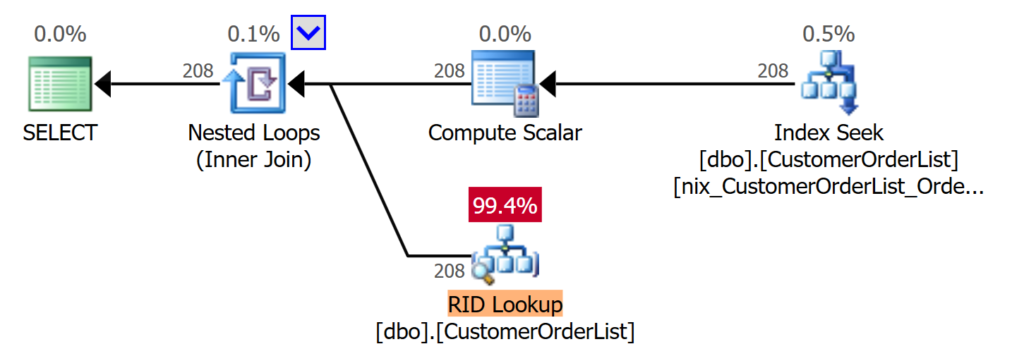
#development #homepage #sql prompt #sql