Introduction
I will focus on AWS Elastic Map Reduce since we are running our Spark workloads on AWS. We are using Apache Airflow for the workflow orchestration.
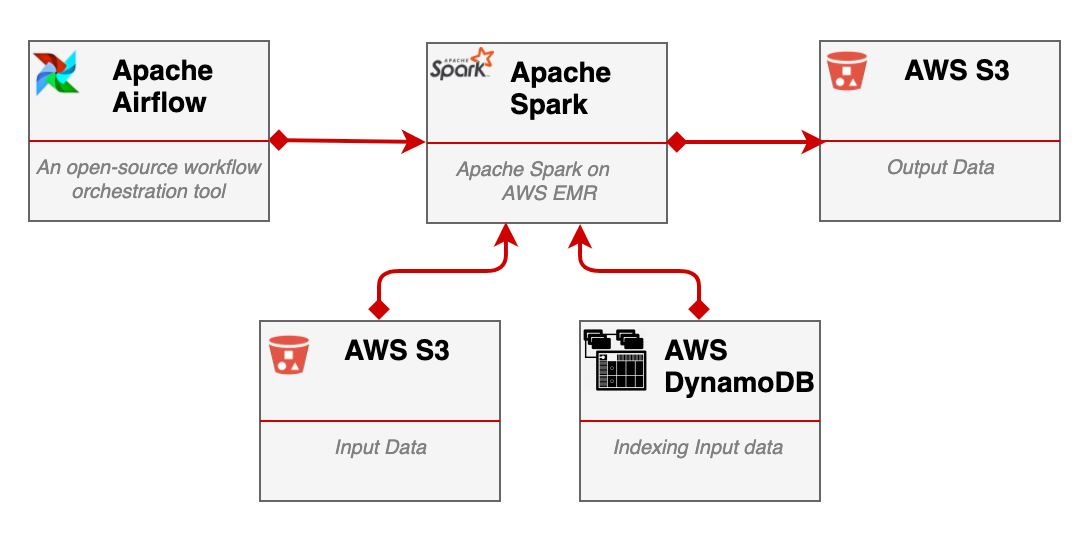
Data Flow
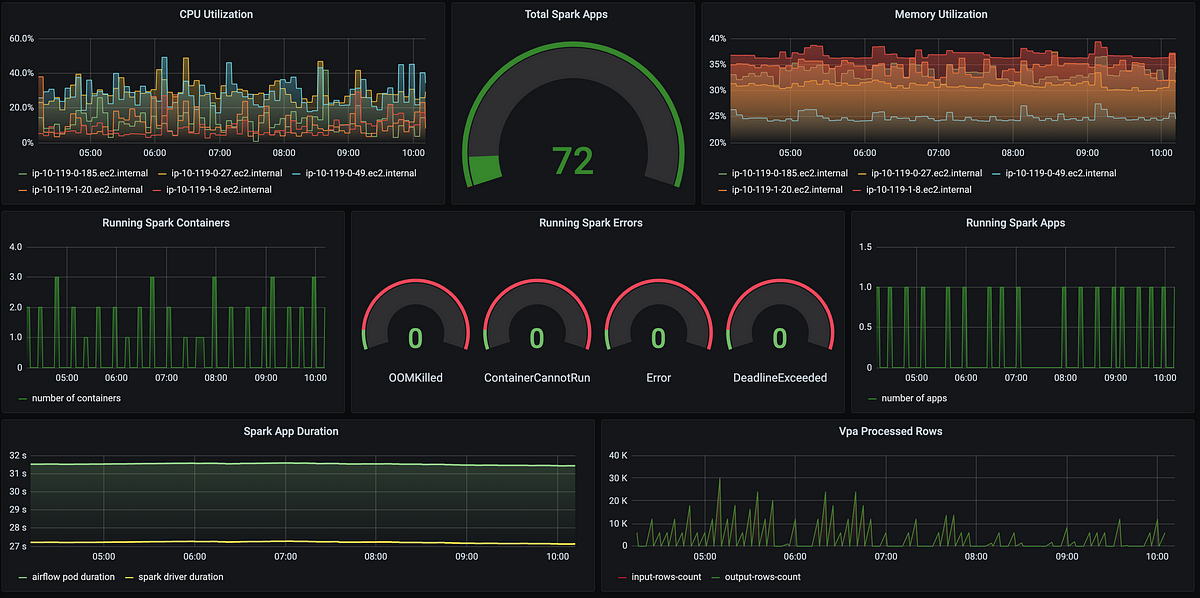
The data comes from different sources that are spread across different geo regions and not necessarily running on the AWS cloud. For example, some of the data sources are web apps running in browsers, others are mobile applications, some are external data pipelines, etc. Here and here you can see how we implemented our data ingestion steps. All input data collected in S3 buckets and indexed by the creation date in AWS DynamoDB. Doing so allows us to process data batches by any given time interval. We are processing ±2TB data per day while having ‘special events’ days when the amount of data can be much bigger.
Problem Statement
Overall, AWS EMR does a great job. It is a reliable, scalable, and flexible tool to manage Apache Spark clusters. AWS EMR comes with out-of-the-box monitoring in a form of AWS Cloudwatch, it provides a rich toolbox that includes Zeppelin, Livy, Hue, etc, and has very good security features. But AWS EMR has its own downgrades as well.
Portability: if you are building a multi-cloud or hybrid (cloud/on-prem) solution, be aware that migrating Spark Applications from AWS EMR can be a big deal. After running for a while on AWS EMR, you can find yourself tightly coupled to AWS specific features. It can be something simple, like logging and monitoring and it can be more complicated like an auto-scaling mechanism, custom master/worker AMIs, AWS security features, etc.
Cost overhead: the Amazon EMR price is in addition to the Amazon EC2 price. Take a look at the pricing example here
#kubernetes #aws #apache-spark #aws-eks #aws-emr