I’m sure you have heard about auto-encoders before. They are neural networks trained to learn efficient data representations in an unsupervised way. They have been proof useful in a variety of tasks like data denoising or dimensionality reduction. However, with a vanilla configuration they seldom work. Hence, in this post we are going to explore how we can construct an efficient anomaly detection model using an autoencoder and contrastive learning (on some literature you will find it referred as negative learning). Full implementation code is available on GitHub.
What’s an autoencoder?
Autoencoders can be seen as an encoder-decoder data compression algorithm where an encoder compress the input data (from the initial space to an encoded space — or latent space) and then the decoder decompress it(from the latent space to the original space). The idea here is that if the autoencoder has leant efficient data representation in the latent space, then it should be able to reconstruct the instances correctly on the other end. Easy peasy.
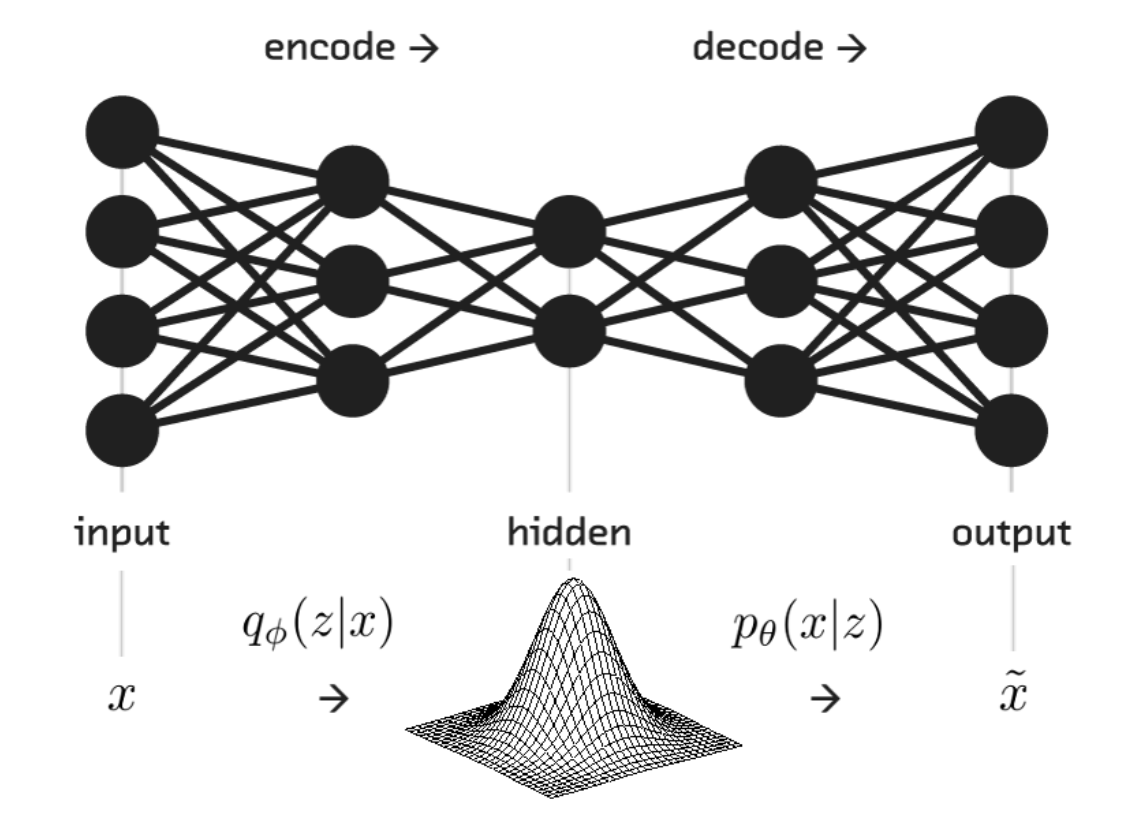
Of course, this compression can be lossy meaning that part of the information might be lost during the encoding process and hence cannot be recovered when decoding. Life is hard. However, the objective here is to find the best autoencoder that keeps the maximum of the information at encoding while attaining the minimum reconstruction error at decoding.
Why is this idea appealing for anomaly detection?
In anomaly detections, you typically have a sequence of observations coming from a given distribution, the normal distribution. If an anomaly is presented then it should be rare and it would not belong to the original data distribution. With this in mind, autoencoders are typically trained to ignore noise and encouraged to learn how to reproduce the most frequent characteristics of the data distribution hoping that when anomalies appear, those characteristics will be missing from the observations. When those characteristics are missing, then the autoencoder will not be able to reconstruct the observation correctly and will produce a high reconstruction error. Finally you will spot anomalous samples when this reconstruction error is higher than a given value.
#data-science #autoencoder #anomaly-detection #machine-learning #deep learning