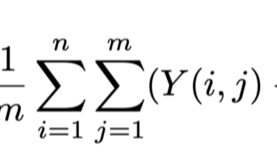In SISR, Autoencoder and U-Net are heavily used; however, they are well-known for difficulties in training to convergence. The choice of loss function plays an important role in guiding models to optimum. Today, I introduce 2 loss functions for Single-Image-Super-Resolution.
Zhengyang Lu and Ying Chen published a U-Net model with innovative loss functions for Single-Image-Super-Resolution. Their work introduces 2 loss functions: Mean-Squared-Error (MSE) for pixel-wise comparison and Mean-Gradient-Error (MGrE) for edge-wise comparison. In this article, I will walk you through and provide code snipsets for MSE and MGrE.
Mean Squared Error (MSE)
MSE is a traditional loss function used in many Machine Learning algorithms (remember Linear Regression, your very first ML algorithm). Still, let’s me explain it again.
Let’s have 2 images (Y and Y^) of the same size (m, n, 3) that each pixel value ranges from 0 to 255. The pixel value represent the pixel color. Then MSE is computed as following:

Picture 1: Mean Squared Error
that _i and j _denotes the pixel location in the image based on x-y coordinates. The MSE formula is to compute the sum of the squared differences of pixel-wis ecolor values divided by m and n. In other words, the MSE formula is to compare pixel-color differences of 2 images. However, this function may not capture differences in edges of objects in 2 images that Lu and Chen proposed Mean Gradient Error to solve the issue.
The code snipset for MSE is not provided because MSE can be easily found in most packages.
#machine-learning #super-resolution #image-processing #artificial-intelligence #loss #function