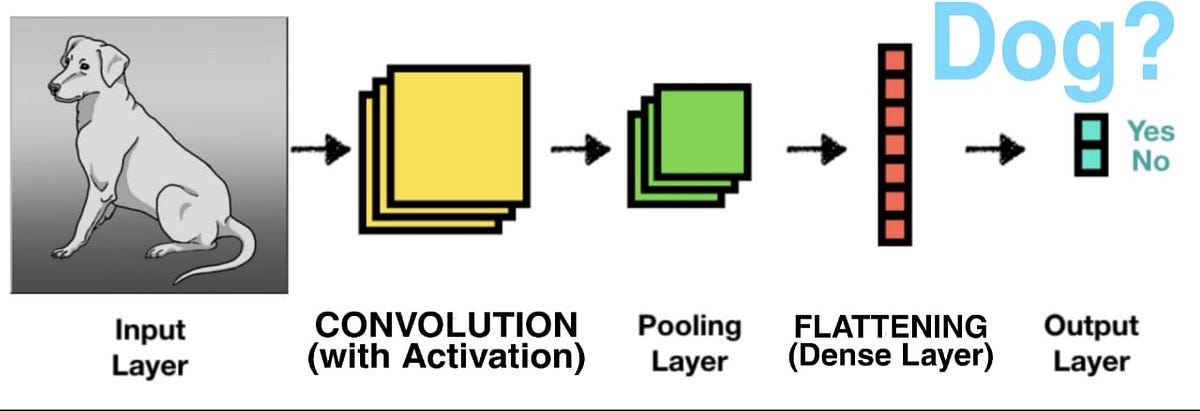
CNN is an easy way to deal with complex image data, it plays a significant role in our lives, from facial recognition and analyzing docs to object detection, and thus is mostly used in all the significant areas of images.
Hello Guys! In the previous story, we discussed the basis of Deep Learning, and it’s a necessity. Today, we will dig up the story of CNN.
Do you know how computers see images?
Whenever we see any object, the data of the object is collected by eyes and then passed to the cerebral Cortex through neurons. The cerebral Cortex has a part called the Visual Cortex, especially available for processing the image data. Visual Cortex is composed of multiple layers to process the image data and give the output. So, whenever we see a cat, it’s the Visual Cortex that gets activated and classifies the image. Inspired by the human brain, CNN similarly does the processing.

The computer breaks down the image into the combination of n*n pixels. Pixel is the smallest element of animage. Each pixel corresponds to anyone’s value. In an 8-bit grayscale image, the value of the pixel between 0 and 255. For a grayscale image, we import pixels in python via NumPY 2D array, where for a colored image, we use NumPY 3D array (due to 3 channels: Red, Green, Blue).
What is convolution?
In simple words, convolution is mixing the two buckets of information. In mathematics, we define convolution as a mathematical operation on two functions that produces a third function. Similarly, in CNN, convolution is an operation performed on image pixel and filter to produce the feature map. This operation is used to detect the edges, and the final information is stored in a feature map.
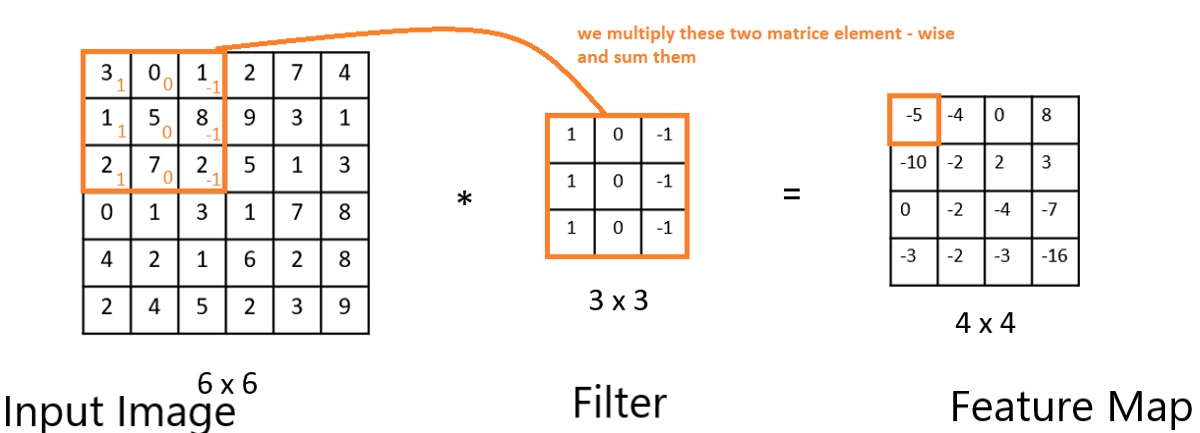
Here, we are using an image of 6 x 6 Input-pixel, a Filter of size 3 x 3, and multiplying them as shown forms Feature Map. The size of the filter is hand-coded, but the best values of the Filter matrix are automatically selected in Keras.For n x n pixel and f x f size filter, we get output of size **(n-f+1) x (n-f+1)**_ of the feature map._
Disadvantages of Convolution
- Every time we apply a convolutional operation, the size of the image shrinks.Pixels present in the corner of the image are used only a few numbers of times during convolution as compared to the central pixels. Hence, we do not focus too much on the corners since that can lead to information loss.
To overcome these disadvantages, we introduce you to a new concept of padding. The padding adds pixels at all edges of the input image, i.e., we pad the image with an additional border. So, for our above example, we input the 8 x 8 matrix, and we get an output matrix of 6 x 6. So, that’s the way we don’t lose our important information.
#machine-learning #convolutional-network #deep-learning #image-processing #artificial-intelligence #deep learning