Learn step by step deployment of a TensorFlow model to Production using TensorFlow Serving.
You created a deep learning model using Tensorflow, fine-tuned the model for better accuracy and precision, and now want to deploy your model to production for users to use it to make predictions.
TensorFlow Serving allows you to
- Easily manage multiple versions of your model, like an experimental or stable version.
- Keep your server architecture and APIs the same
- Dynamically discovers a new version of the TensorFlow flow model and serves it using (remote procedure protocol) using a consistent API structure
- Consistent experience for all clients making inferences by centralizing the location of the model
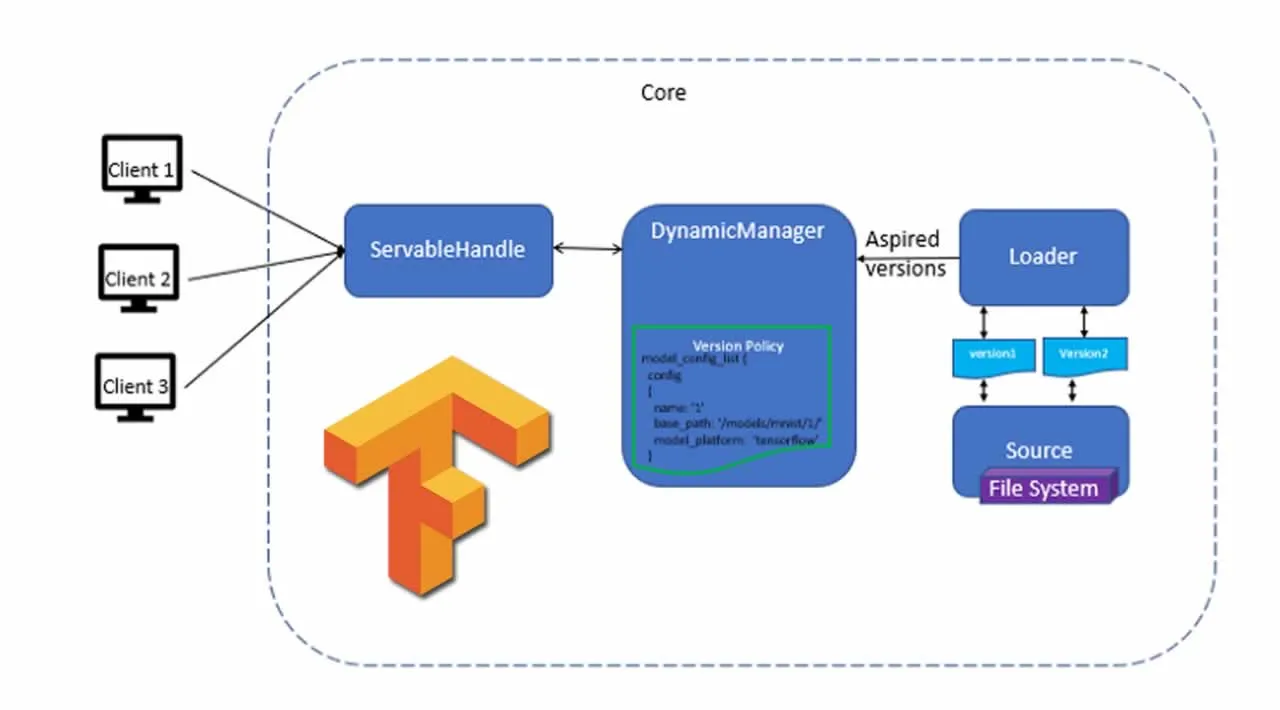
The key components of TF Serving are
- Servables: A Servable is an underlying object used by clients to perform computation or inference**. TensorFlow serving represents the deep learning models as one ore more Servables.
- Loaders: Manage the lifecycle of the Servables as Servables cannot manage their own lifecycle. Loaders standardize the APIs for loading and unloading the Servables, independent of the specific learning algorithm.
- Source: Finds and provides Servables and then supplies one Loader instance for each version of the servable.
- Managers: Manage the full lifecycle of the servable: Loading the servable, Serving the servable, and Unloading the servable
- TensorFlow Core: Manages lifecycle and metrics of the Servable by making the Loader and servable as opaque objects
#tensorflow-serving #deep-learning #mnist #tensorflow #windows-10
5.40 GEEK