In previous posts (here and here), I told you about how our team uses the Amazon SageMaker and Amazon s3 services to train our deep neural networks on large quantities of data.
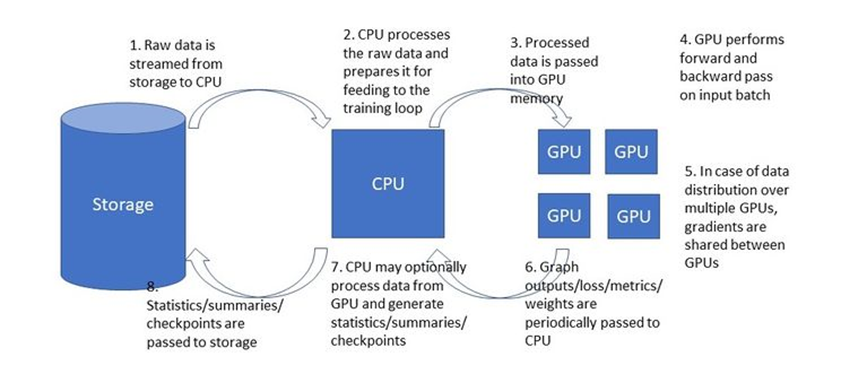
In this blog, I would like to discuss how to profile the performance of a DNN training session running in TensorFlow. When speaking of the “performance” of a DNN training session, one may be referring to a number of different things. In the context of this blog, “performance” profiling will refer to analysis of the speed at which the training is performed (as measured, for example, by the training throughput or iterations per second), and the manner in which the session utilizes the system resources to achieve this speed. We will not be referring to the performance of the model being trained, often measured by the loss or metric evaluation on a test set. An additional measure of performance is the number of batches required until the training converges. This is also out of the scope of this blog.
In short, if you are trying to figure out why your training is running slowly, you have come to the right place. If you are searching for ways to improve the accuracy of your mnist model, or are searching for what optimizer settings to use to accelerate convergence, you have not.
The examples we will review were written in TensorFlow and run in the cloud using the Amazon SageMaker service, but the discussion we will have is equally applicable to any other training environment.
Prelude
Any discussion on performance profiling your training requires that we be clear about what the goal is, or, what utility function we are trying to optimize. Your utility function will likely depend on a number of factors, including, the number of training instances at your disposal, the cost of those instances, the number of models you need to train, project scheduling constraints and more.
In order to have a meaningful discussion, we will make some simplifying assumptions. Our goal will be to maximize the throughput of a training session, given a fixed training environment, without harming the quality of the resultant model, or increasing the number of training samples required for convergence.
The goal, as stated, includes some ambiguities that we will promptly explain.
#tensorflow #sagemaker #analysis #performance #data analysis