Even though the concept of batch normalization itself is rather simple, it solves so many common yet persistent problems in deep neural networks that it is regarded by many as one of the greatest breakthroughs in deep learning.
Training a convolutional neural network to process images is incredibly difficult for several issues — there are a large number of parameters that require heavy computation, the learning objective has many poor local minima, needs large amounts of training data, but most importantly, is especially prone to vanishing and exploding gradients.
The vanishing gradients problem is an example of unstable behavior that is often encountered when training a deep neural network, and occurs when a neural network is so long and complex that the neural network is unable to backpropagate useful gradient information to weights in the beginning of the network. This usually happens because activation functions gradually diminish the signal as it backpropagates throughout the network. As a result, the layers near the input of the model remain relatively unchanged and provide little value, restricting the model from accessing its true predictive power. Hence, the optimizer can only optimize the model so far with the weights it can access, and will, therefore, remain stagnant with no improvement even as the front structures are not being utilized.
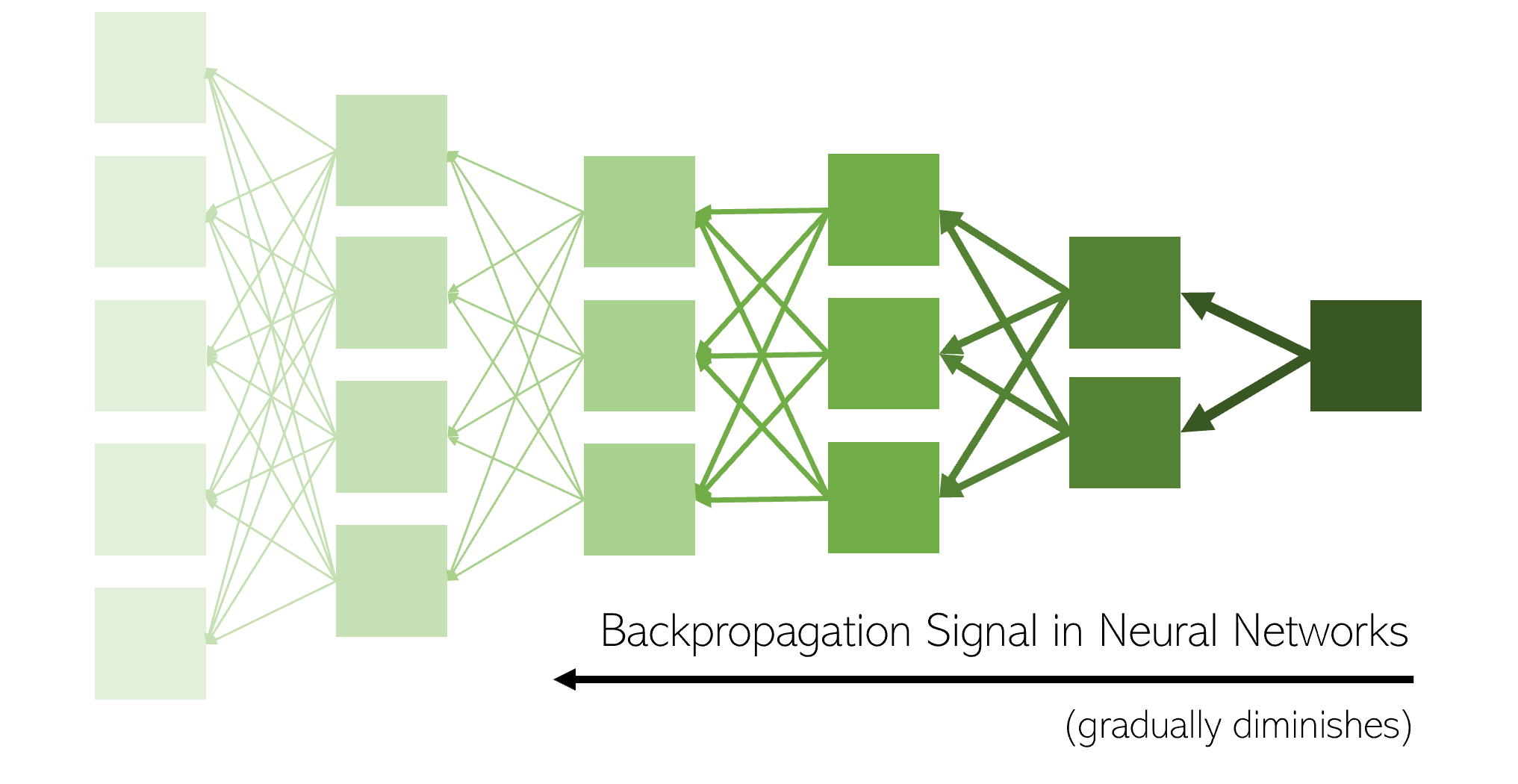
Created by Author
The explosive gradients problem, on the other hand, occurs when large error gradients sequentially accumulate and result in large, unstable, pendulum-like updates on the neural network weights during training. Both the vanishing gradients and explosive gradients provide two huge problems that often plague neural networks. To address these gradient issues, primary methods used to address them include carefully setting the learning rate (slowly decaying the learning rate as the model approaches an optima), designing a better CNN architecture with different activation functions, more careful initialization of weights, and tuning the data distribution. The most effective solution is batch normalization.
A batch normalization layer takes in the data flowing through the network and outputs a rescaled and normalized filter over it. This has the effect of shifting the distribution of inputs flowing throughout the network.
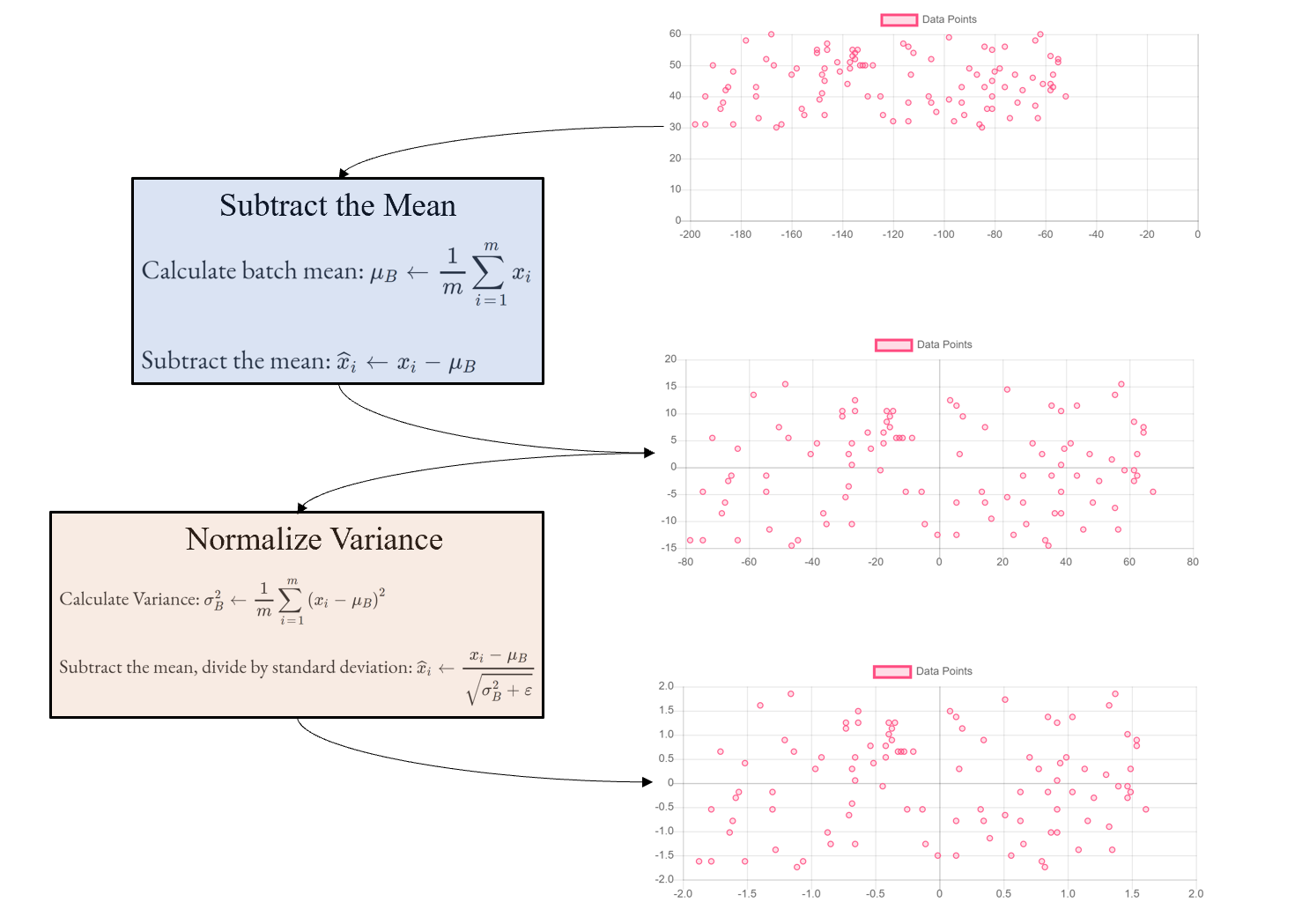
Image created by author.
The original batch normalization paper claimed that batch normalization was so effective in increasing the deep neural network performance because of a phenomenon named “Internal Covariate Shift”. According to this theory, the distribution of the inputs to hidden layers in a deep neural network changes erratically as the parameters of the model are updated. Batch normalization, instinctively, restores a distribution of inputs that may have shifted and stretched while undergoing travel through hidden layers, thus preventing blockages to training.
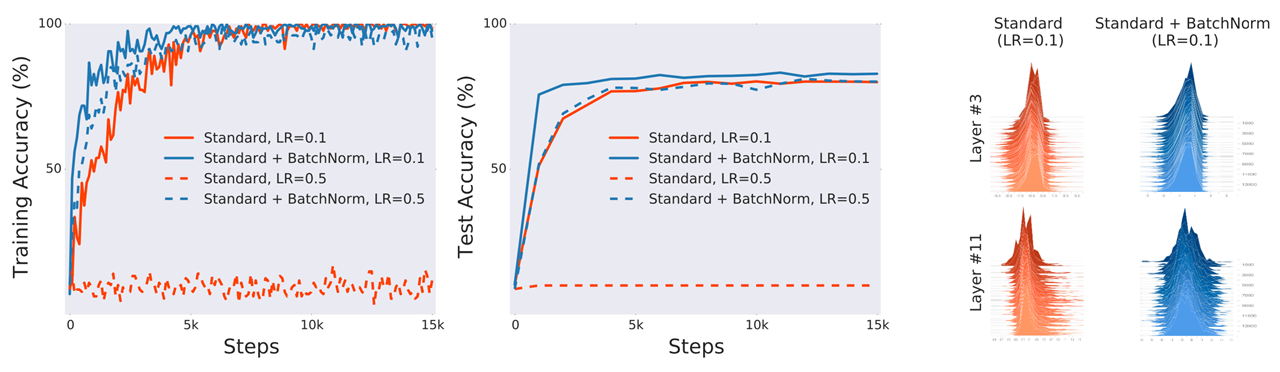
Comparison of (a) training (optimization) and (b) test (generalization) performance of a standard VGG network trained on CIFAR-10 with and without Batch Normalization. © comparison of weights in third and eleventh layers with and without Batch Normalization. Note the vastly more centered and normal distribution, opposed to the standard’s skewed and uneven one. Source — arXiv:1805.11604v5. Image free to share.
Unfortunately, the instinctive explanation of internal covariate shift has been proven not to be true. In fact, the distribution of inputs as it passed through the hidden layers changing does not seem to affect the model’s training much. The authors of the groundbreaking paper that revealed this truth, “How Does Batch Normalization Help Optimization?” from MIT, performed an experiment to measure the validity of the internal covariate shift theory.
In the experiment, one standard and two standard + batch normalization standard VGG16 network architectures were trained on the CIFAR-10 dataset. One of the standard + batch normalization networks had completely random noise injected after batch normalization layers, causing tremendous amounts of internal covariate shift, which could not be ‘corrected’ by the BatchNorm layers. The results are fascinating — although it is clear that the distributions of weights after the ‘noisy’ batch normalization network are not as even as in the regular batch normalization model, it performs just as well, both batch normalization neural networks outperforming a standard one.

Source — arXiv:1805.11604v5. Image free to share.
Instead, the authors find that batch normalization smooths the optimization landscape. As the gradient descent optimizer attempts to find the global optima, it needs to make trade-off decisions on whether the current optima is a local optima or a global one, and sacrificing a temporary increase in error to a larger drop. Often, optimizers in rugged terrains with many sharp peaks, flat plains, and jagged valleys find this task difficult and become over reliant on an often carelessly set learning rate, resulting in poor accuracies.
#data-science #deep-learning #ai #data-analysis #machine-learning #deep learning