Hello everyone, I am back with another topic which is Data Preprocessing. This is a part of the data analytics and machine learning process that data scientists spend most of their time on. In this article, I’ll dive into the topic, why we use it, and the necessary steps.
What is Data Preprocessing ?
Data preprocessing is a data mining technique that involves transforming raw data into an understandable format. Real-world data is often incomplete, inconsistent, and/or lacking in certain behaviors or trends, and is likely to contain many errors. Data preprocessing is a proven method of resolving such issues.
Why use Data Preprocessing?
In the real world data are generally incomplete: lacking attribute values, lacking certain attributes of interest, or containing only aggregate data. Noisy: containing errors or outliers. Inconsistent: containing discrepancies in codes or names.

Taken from Google Images
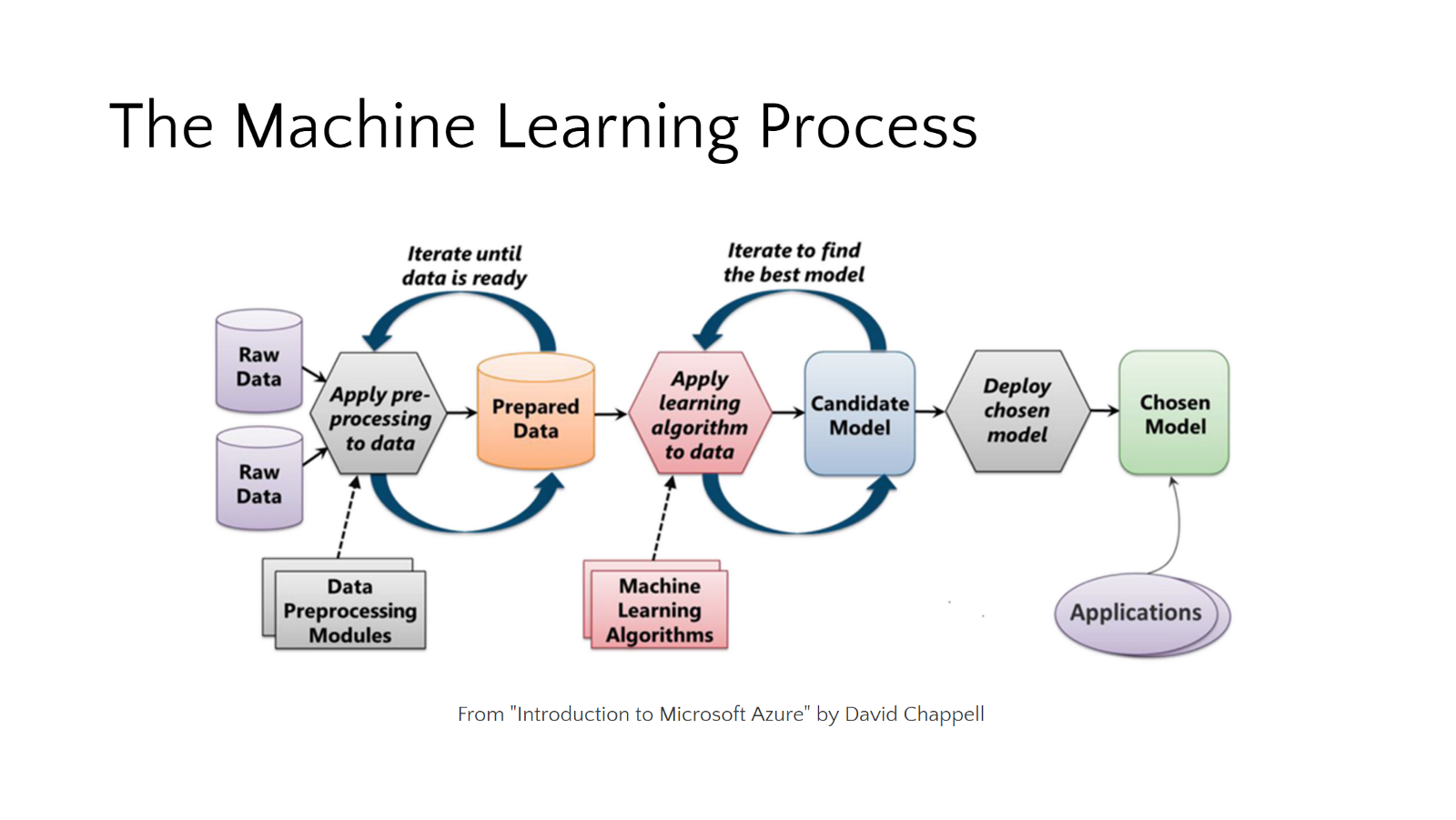
Machine Learning ProcessSteps in Data Preprocessing
- Step 1 : Import the libraries
- Step 2 : Import the data-set
- Step 3 : Check out the missing values
- Step 4 : See the Categorical Values
- Step 5 : Splitting the data-set into Training and Test Set
- Step 6 : Feature Scaling
So, without wasting further time let’s get started!!!
#data-science #machine-learning #data-processing #data #ml #deep-learning
