What is Regularization Technique?
It’s a technique mainly used to overcome the over-fitting issue during the model fitting. This is done by adding a penalty as the model’s complexity gets increased. Regularization parameter λ penalizes all the regression parameters except the intercept so that the model generalizes the data and it will avoid the over-fitting (i.e. it helps to keep the parameters regular or normal). This will make the fit more generalized to unseen data.

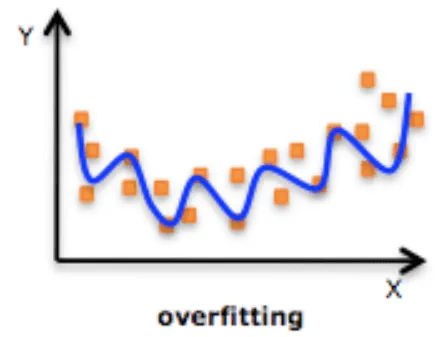
Over-fitting means while training the model using the training data, the model reads all the observation and learns from it and model becomes too complex. But while validating the same model using the testing data, the fit becomes worse.
hat does the Regularization Technique do?
The basic concept is we don’t want huge weight for the regression coefficients. The simple regression equation is y= β0+β1x , where y is the response variable or dependent variable or target variable, x is the feature variable or independent variable and β’s are the regression coefficient parameter or unknown parameter.
A small change in the weight to the parameters makes a larger difference in the target variable, thus it ensures that not too much weight is added. In this, not too much weight to any feature is given, and zero weight is given to the least significant feature.
Working of Regularization
Thus regularization will add the penalty for the higher terms and this will decrease the importance given to the higher terms and will bring the model towards less complex.
Regularization equation:
Min(Σ(yi-βi*xi)² + λ/2 * Σ (|βi|)^p )
where p=1,2,…. and i=1,…,n. Mostly the popular values of p chosen would be 1 or 2. Thus selecting the feature is done by regularization.
#overfitting #machine-learning #data-science #regularization #deep learning