Some believe that the Extreme Learning Machine is one of the smartest neural network inventions ever created — so much so that there’s even a conference dedicated exclusively to the study of ELM neural network architectures. Proponents of ELMs argue that it can perform standard tasks at exponentially faster training times, with few training examples. On the other hand, besides from the fact that it’s not big in the machine learning community, it’s got plenty of criticism from experts in deep learning, including Yann LeCun, who argue that it’s gotten far more publicity and credibility than it deserves.
Mostly, people seem to think it’s an interesting concept.
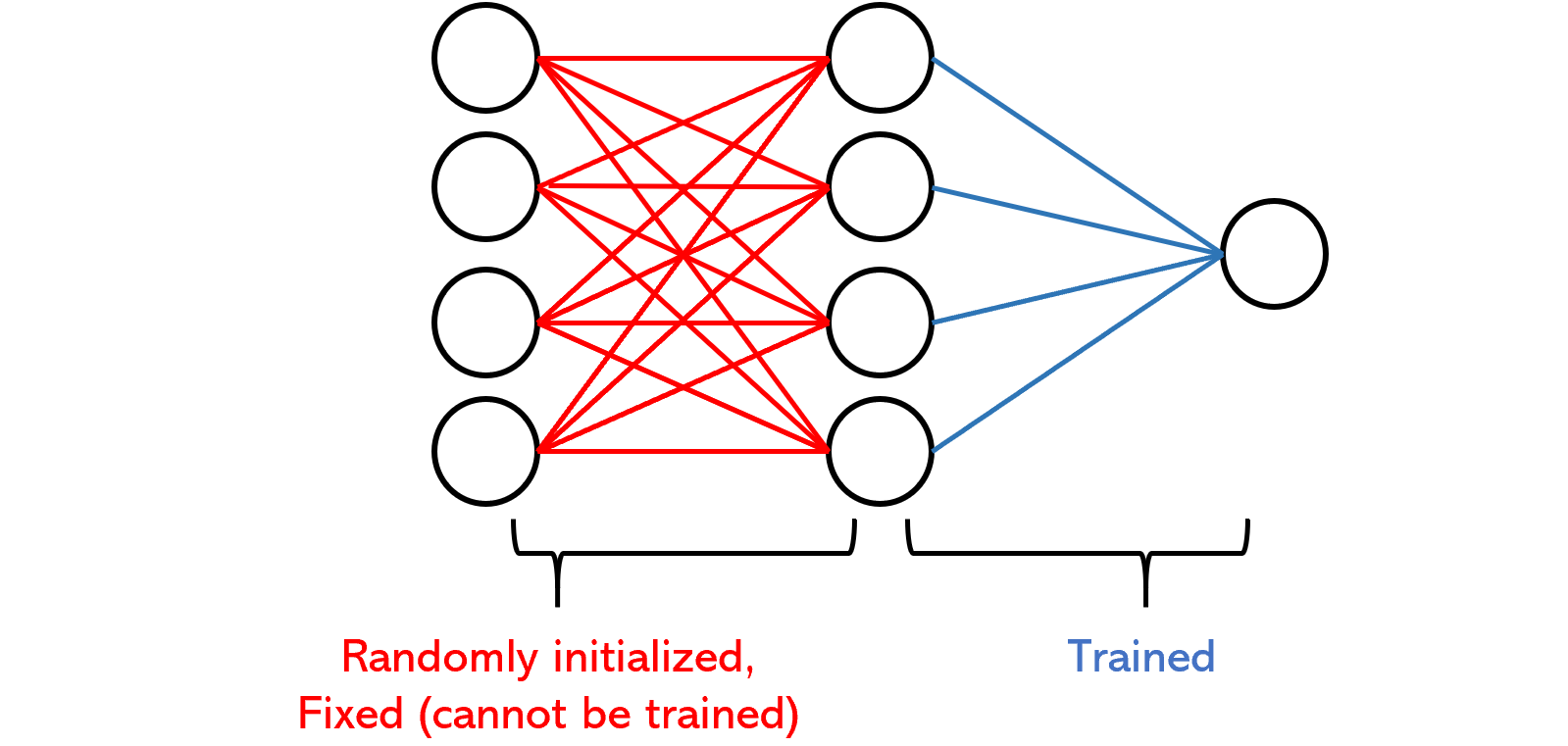
An ELM architecture is composed of two layers; the first is randomly initialized and fixed, whereas the second is trainable. Essentially, the network randomly projects the data into a new space and performs a multiple regression (then passing it through an output activation function, of course). The random projection entails a dimensionality reduction (or enlargement) method, which multiplies random matrices by the input — although the idea may sound odd, pulling randomly from strategic distributions can actually work very well (as we’ll see with an intuitive analogy later). It applies a random distortion of sorts that applies noise — in a good way, if done correctly — and lets the remainder of the network to adapt, opening up new doors in terms of learning opportunities.
In fact, it is because of this randomness that Extreme Learning Machines have been shown to possess Universal Approximation Theorem powers with relatively small nodes in the hidden layer.
In fact, the idea of random projections have been explored early in the field of neural network development, in the 1980s and 1990s, under that name — which is the reasoning behind one critique that ELMs are nothing new; just old research packaged under a new name. Many other architectures like echo state machines and liquid state machines also utilize random skip connections and other sources of randomness.
Perhaps the largest difference, however, between ELMs and other neural network architectures is that it doesn’t use backpropagation. Instead, since the trainable half of the network is simply a multiple regression, the parameters are trained in roughly the same way coefficients are fitted in regression. This represents a fundamental shift in the way neural networks are thought to be trained.
Almost every neural network developed since the vanilla artificial neural network has been optimized using iterative updating (or call it tuning, if you’d like) by bouncing information signals forward and backward throughout the network. Because this method has been around for so long, one must assume that it’s been tried and tested as the best one, but researchers acknowledge that standard backpropagation has many issues, like being very slow to train or falling into very luring local minima.
On the other hand, ELM uses a much more mathematically involved formula to set weights, and without going too deeply into the math, one can think of using the random layer as compensating for more computationally expensive details that it would otherwise be replaced with. If it helps, technically, the wildly successful Dropout layer is a sort of random projection.
Because ELMs employ both randomness and a no-backpropagation algorithm, they are exponentially faster to train than standard neural networks.
Whether they perform better or not, on the other hand, is another question.
#artificial-intelligence #ai #machine-learning #data-science #deep-learning
