One of the most frequently used transformations in Apache Spark is Join operation. Joins in Apache Spark allow the developer to combine two or more data frames based on certain (sortable) keys. The syntax for writing a join operation is simple but some times what goes on behind the curtain is lost. Internally, for Joins Apache Spark proposes a couple of Algorithms and then chooses one of them. Not knowing what these internal algorithms are, and which one does spark choose might make a simple Join operation expensive.
While opting for a Join Algorithm, Spark looks at the size of the data frames involved. It considers the Join type and condition specified, and hint (if any) to finally decide upon the algorithm to use. In most of the cases, Sort Merge join and Shuffle Hash join are the two major power horses that drive the Spark SQL joins. But if spark finds the size of one of the data frames less than a certain threshold, Spark puts up Broadcast Join as it’s top contender.
Broadcast Hash Join
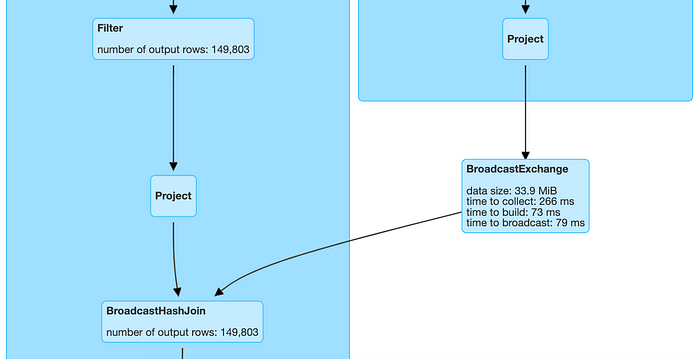
Looking at the Physical plan of a Join operation, a Broadcast Hash Join in Spark looks like this

The above plan shows that the data frame from one of the branches broadcasts to every node containing the other data frame. In each node, Spark then performs the final Join operation. This is Spark’s per-node communication strategy.
Spark uses the Broadcast Hash Join when one of the data frame’s size is less than the threshold set in spark.sql.autoBroadcastJoinThreshold. It’s default value is 10 Mb, but can be changed using the following code
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 100 * 1024 * 1024)
This algorithm has the advantage that the other side of the join doesn’t require any shuffle. If this other side is very large, not doing the shuffle will bring notable speed-up as compared to other algorithms that would have to do the shuffle.
Broadcasting large datasets can also lead to timeout errors. A configuration spark.sql.broadcastTimeout sets the maximum time that a broadcast operation should take, past which the operation fails. The default timeout value is 5 minutes, but it can be set as follows:
spark.conf.set("spark.sql.broadcastTimeout", time_in_sec)
Sort Merge Join
If neither of the data frames can be broadcasted, then Spark resorts to Sort Merge Join. This algorithm uses the node-node communication strategy, where Spark shuffles the data across the cluster.
Sort Merge Join requires both sides of the join to have correct partitioning and order. Generally, this is ensured by** shuffle and sort** in both branches of the join as depicted below
#apache spark #scala #tech blogs #broadcast join #join opertaions #join optimization #joins in spark #shuffled hash join #sort merge join