Data Augmentation is a very important topic of deep learning, it is the backbone of multiple deep learning which are generalized in nature. It enables deep learning models to broaden their ability to learn about the images in detail.
Data Augmentation major use is the field of images, the models which are mostly related to Image classification are supposed to Data Augmentation so that better results are achieved in terms of accuracy, etc. Some of the examples of Deep Learning Models which are mostly used for image classification are CNN (Convolutional Neural Network), Le-Net, ResNet, etc.
What is Data Augmentation?
It is a technique of generating data with random features as specified by the user from the original data. For example, Look at the thumbnail image of this course, it is having one dog at left, consider that to be the original image, that image is of a dog & that is confirmed. But, what about the image at the right part, that is also of a dog. To identify this, it is a very easy task for humans because their brain understands images in a perfect manner, but computers are best at numbers, that is why the image is converted into pixels. That is why it is very difficult for the computer to identify variations.
Here, Data Augmentation comes into the picture, the actual work of Data Augmentation is to generate variety from the dataset like the one shown in the thumbnail image. New Data can be generated from multiple methods/variations which are provided the inbuilt functions(discussed later in this blog).
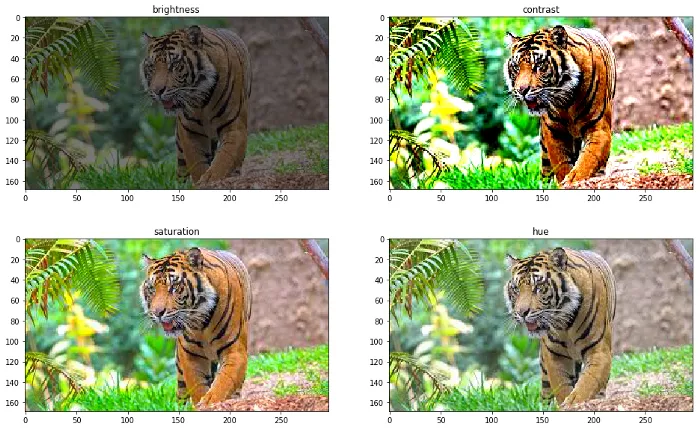
Some example generation of new data can be by rotating the image by some angle, flipping the image, increasing/decreasing the brightness of the image, etc. One more augmented data example image is shown below.
#machine-learning #data-science #data-augmentation #keras #deep-learning