One of the common problems in Machine Learning is handling the imbalanced data, in which there is a highly disproportionate in the target classes.
Hello world, this is my second blog for the Data Science community. In this blog, we are going to see how to deal with the multiclass imbalanced data problem.
What is Multiclass Imbalanced Data?
When the target classes (two or more) of classification problems are not equally distributed, then we call it Imbalanced data. If we failed to handle this problem then the model will become a disaster because modeling using class-imbalanced data is biased in favor of the majority class.
There are different methods of handling imbalanced data, the most common methods are Oversampling and creating synthetic samples.
What is SMOTE?
SMOTE is an oversampling technique that generates synthetic samples from the dataset which increases the predictive power for minority classes. Even though there is no loss of information but it has a few limitations.
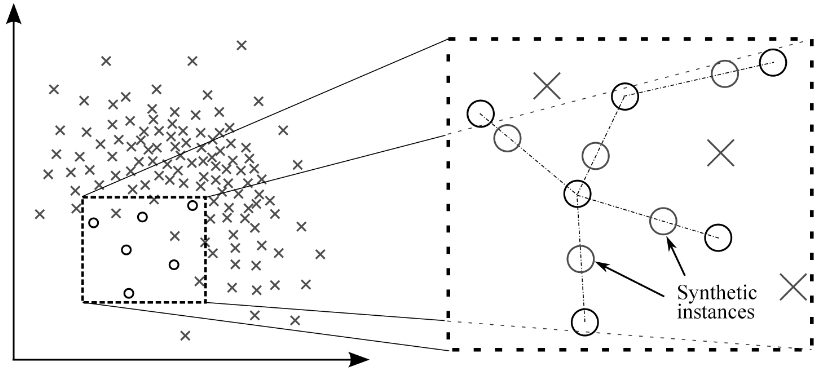
Synthetic Samples
Limitations:
- SMOTE is not very good for high dimensionality data
- Overlapping of classes may happen and can introduce more noise to the data.
So, to skip this problem, we can assign weights for the class manually with the ‘class_weight’ parameter.
#statistics #data-science #data-analysis #machine-learning #imbalanced-data #data analytic
