While working with pandas, if you have encountered a large dataset, then you might have thought of an alternative, especially when your machine is not strong. Pandas is really good for small/average-sized datasets, but as data gets bigger, it does not perform as well as it performs on simple and smaller datasets.
Here you can see the comparison of Pandas with another library modin on reading the dataset from a CSV file.
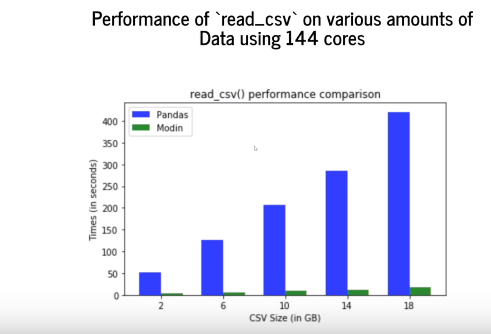
Similarly, a very common problem pandas users often go through is the dead jupyter kernel due to out of memory. The computations are expensive, and the CPU is not strong enough to handle those.
In this article, you are going to learn about Vaex, a Python library that is similar to Pandas, how to install it, and some of its important functions that can help you in performing different tasks.
Introduction to Vaex
Vaex is a python library that is an out-of-core dataframe, which can handle up to 1 billion rows per second. 1 billion rows. Yes, you read it right, that too, in a second. It uses memory mapping, a zero-copy policy which means that it will not touch or make a copy of the dataset unless explicitly asked to. This makes it possible to work with datasets that are equal to the size of your hard drive. Vaex also uses lazy computations for the best performance and no memory wastage.
#2021 may tutorials # overviews #big data #data preprocessing #pandas #scalability #vaex
