MariaDB MaxScale is an advanced database proxy, firewall, and query router that provides automatic failover for high availability in MariaDB replication deployments with MariaDB Server. Automatic failover occurs when MaxScale automatically promotes a replica server to be the new primary server when a primary server fails. Cooperative monitoring is one of the many important new features in MaxScale 2.5. With cooperative monitoring, MaxScale nodes automatically designate a new primary MaxScale node in the event the designated primary MaxScale node in a cluster goes down.
Automatic Failover MaxScale 2.2 - 2.4
In MaxScale versions 2.2 - 2.4, high availability (HA) is provided by configuring the MaxScale nodes in a cluster to either passive = false for the primary or passive = true for the replicas. All MaxScale nodes can perform query routing, read write splitting and other operations, but only the “active” MaxScale node ( passive = false) can perform MariaDB backend automatic failovers. This avoids the creation of more than one primary, a situation referred to as a “split-brain”. But it means that in MaxScale versions 2.2 - 2.4, if the primary/active MaxScale node fails, one of the remaining nodes must be reconfigured as passive = false to re-enable automatic failover. This has generally been accomplished with third-party software.
How Cooperative Monitoring Works
In contrast to the non-standardized solutions needed for earlier versions, MaxScale 2.5 uses cooperative monitoring to assign a new primary node without requiring intervention. Cooperative monitoring prevents the creation of more than one primary server by using backend locks. When cooperative monitoring is enabled, MaxScale tries to acquire locks on the backend MariaDB Servers with the GET_LOCK() function. If a specific MaxScale instance can acquire the lock on a majority of servers, it is considered the primary MaxScale instance.
The locks are figured by this formula:
n_servers/2 + 1
where “n_servers” is the number of servers, but the number of servers can be calculated in two different ways. Cooperative monitoring is enabled with the cooperative_monitoring_locks parameter in maxscale.cnf. By default, cooperative_monitoring_locks is set to “none” and disabled. It can be enabled in either of two modes " majority_of_all" and " majority_of_running" and they calculate the number of servers, n_servers, differently.
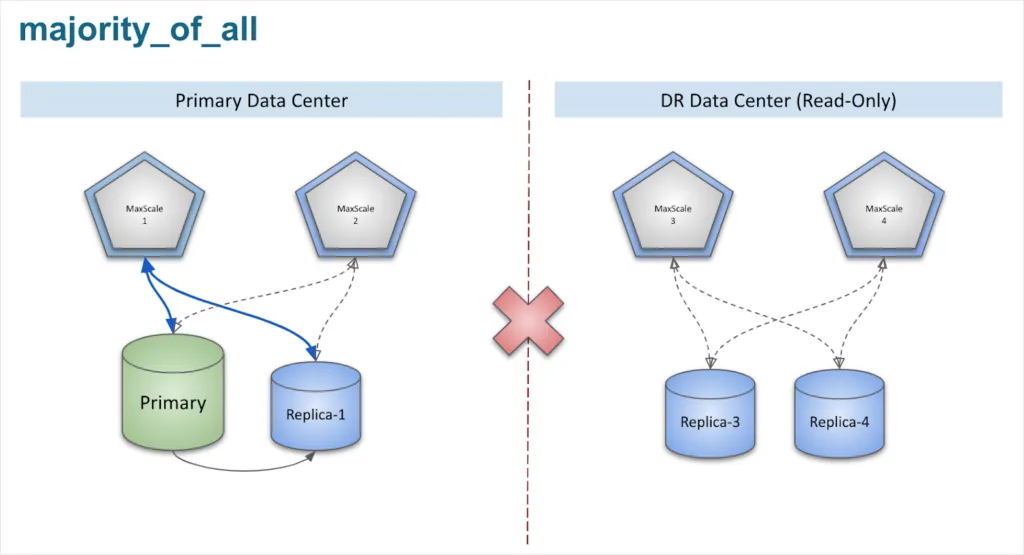
majority_of_all
In the mode majority_of_all, " n_servers" is the total number of servers in the cluster and the MaxScale node with the maximum locks will become the primary. For example, in the case of a:
- 4 nodes Primary/Replica setup, the minimum number of locks required is 4/2 + 1 = 3
- 8 nodes Primary/Replica setup, the minimum number of locks required is 8/2 + 1 = 5
This protects against multiple MaxScale nodes becoming primary in case of a split brain scenario such as a partition between two data centers. But, if too many MariaDB nodes go down at the same time, none of the MaxScale nodes will become primary since none can achieve the minimum required number of locks. The result in this type of case is that all nodes become “secondary.”
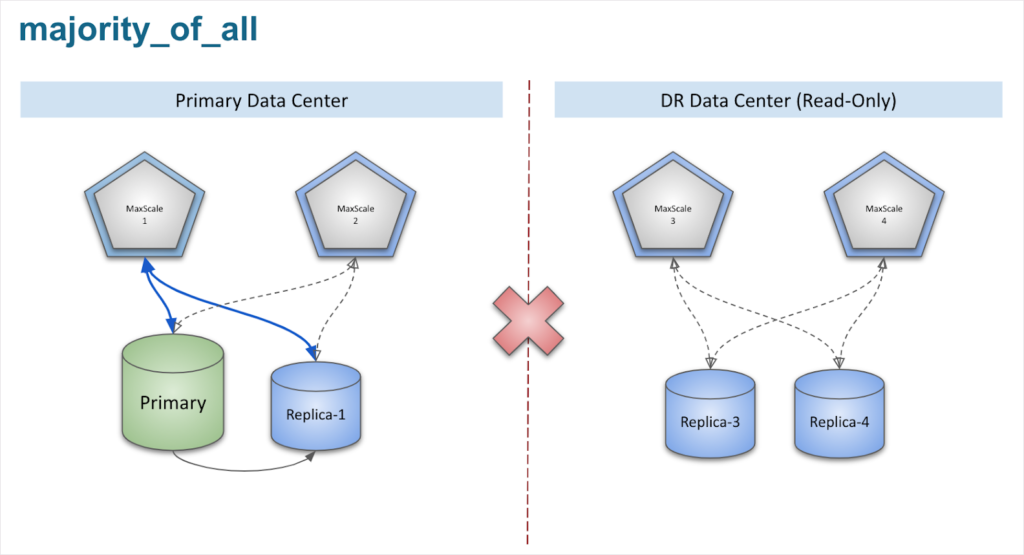
_In the diagram above, the network between the two data centers is broken, the MaxScale nodes can only acquire 2 locks each which is less than the minimum requirement of “3”. All MaxScale nodes become “secondary”, and automatic failover is disabled and split brain is prevented. The primary data center continues to work as normal because MaxScale can still route queries to the Primary database._majority_of_running
In the mode majority_of_running, locks are still calculated as n_servers/2 + 1, but the " n_servers" is calculated as the number of “running” nodes in the cluster instead of the total number of nodes in the cluster. As servers go down, the " n_servers" is reduced accordingly, and so is the minimum locks requirement. For example, in a 4 node cluster using majority_of_running, the calculation of minimum locks requirement will be as follows:
- All 4 nodes are alive: 4/2 + 1 = 3
- 1 Node goes down: 3/2 + 1 = 2
- 2 Nodes goes down: 2/2 + 1 = 2
- 3 Nodes goes down: 1/2 + 1 = 1
This supports more node failure while still being able to handle automatic MariaDB failover. But in cases of multiple data centers, majority_of_running could lead to a split brain scenario and the creation of more than one primary. majority_of_running** is only suitable where clusters reside in the same data center**.
#database #sql #mariadb #tests monitoring