Writing Readable And Reproducible data processing code
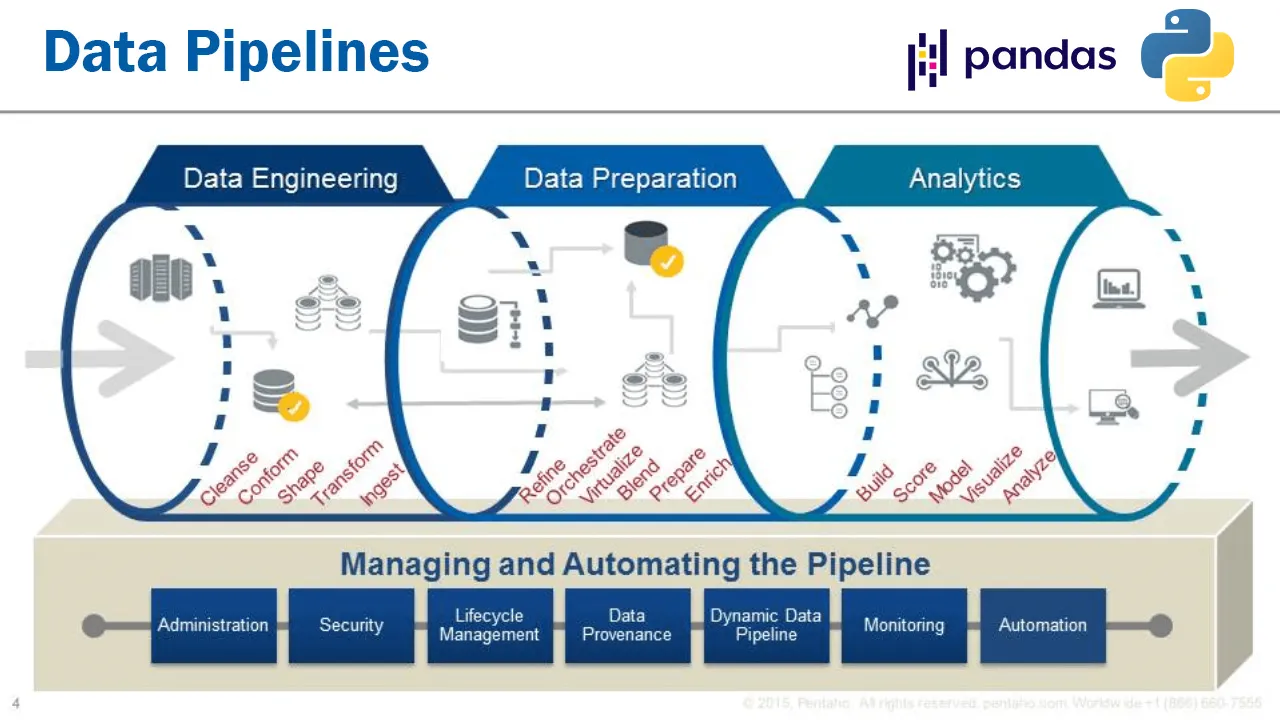
Data processing issues
If you are not dealing with big data you are probably using Pandas to write scripts to do some data processing. If so, then you are certainly using Jupyter because it allows seeing the results of the transformations applied. However, you may have already noticed that notebooks can quickly become messy.
When the start-up phase comes, the question of reproducibility and maintenance arises. Tools such as paper mill allow you to put a notebook directly into production. However, this does not guarantee reproducibility and readability for a future person who will be in charge of maintenance when you are gone.
If notebooks offer the possibility of writing markdown to document its data processing, it’s quite time consuming and there is a risk that the code no longer matches the documentation over the iterations.
What is needed is to have a framework to refactor the code quickly and at the same time that allows people to quickly know what the code is doing.
Introducing genpipes
genpipes is a small library to help write readable and reproducible pipelines based on decorators and generators. You can install it with pip install genpipes
It can easily be integrated with pandas in order to write data pipelines. Below a simple example of how to integrate the library with pandas code for data processing.
#technology #programming #data-science #software-engineering #productivity #data pipelines with python and pandas