Detailed Notes for Machine Learning Foundation Course by Microsoft Azure & Udacity, 2020 on Lesson 2 —_ Introduction to Machine Learning_
What is Machine Learning?
Machine learning_ is a data science technique used to extract patterns from data, allowing computers to identify related data, and forecast future outcomes, behaviors, and trends._
One important component of machine learning is that we are taking some data and using it to make predictions or identify important relationships. But looking for patterns


Applications
- Health
- Finance/Banking
- Manufacturing
- Retail
- Government
- Education
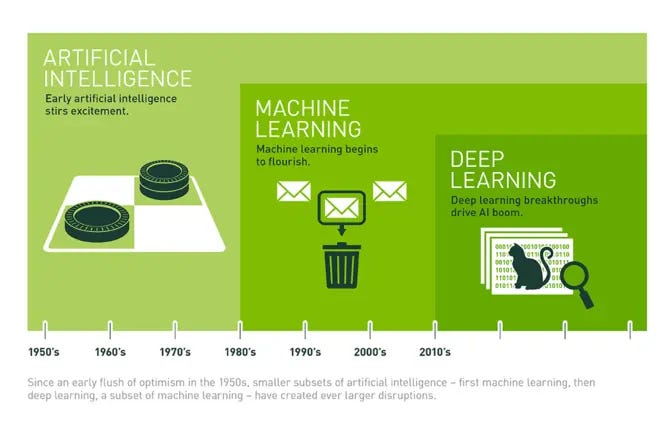
Brief History of Machine Learning
Artificial Intelligence:
A broad term that refers to computers thinking more like humans.
Machine Learning:
A subcategory of artificial intelligence that involves learning from data without being explicitly programmed.
Deep Learning:
A subcategory of machine learning that uses a layered neural-network architecture originally inspired by the human brain.
Data Science Process
Raw data, however, is often noisy and unreliable and may contain missing values and outliers. Using such data for modeling can produce misleading results. For the data scientist, the ability to combine large, disparate data sets into a format more appropriate for analysis is an increasingly crucial skill.
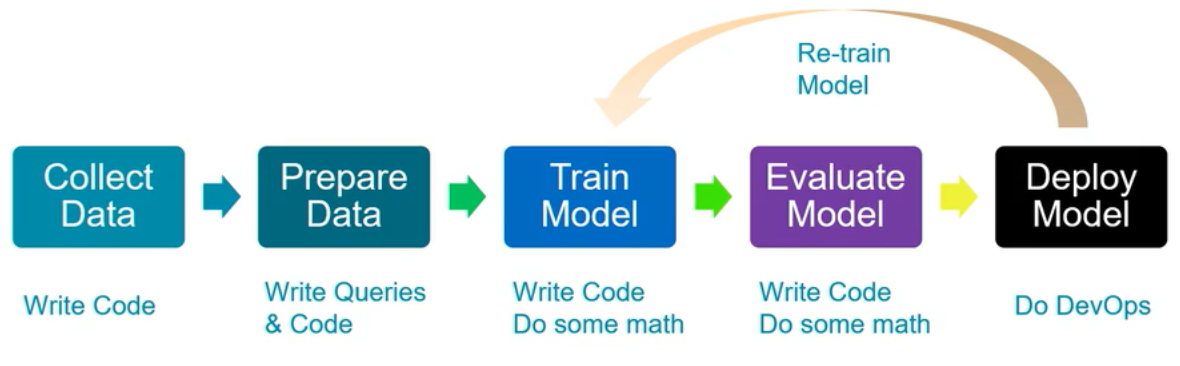
**Collect Data: **Query databases, call Web Services, APIs, scraping web pages.
**Prepare Data: **Clean data and create features needed for the model.
**Train Model: **Select the algorithm, and prepare training, testing, and validation data sets. Set-up training pipelines including feature vectorization, feature scaling, tuning parameters, model performance on validation data using evaluation metrics or graphs.
**Evaluate Model: **Test & compare the performance of models with evaluation metrics/graphs on the validation data set.
**Deploy Model: **Package the model and dependencies. Part of DevOps, integrate training, evaluation, and deployment scripts in respective build & release pipeline.
Artificial Intelligence Jobs
Common Types of Data
- Numeric
- Time-series
- Categorical
- Text
- Images
Tabular Data
Data that is arranged in a data _table _and is the most common type of data in Machine Learning. is arranged in rows and columns. In tabular data, typically each row describes a single item, while each column describes different properties of the item. Each row describes a single product (e.g., a shirt), while each column describes a property the products can have (e.g., the color of the product)
Row: An item or entity.
Column: A property that the items or entities in the table can have.
Cell: A single value.
Vectors:
It is important to know that in machine learning we ultimately always work with numbers or specifically vectors.
A vector is simply an array of numbers, such as (1, 2, 3)—or a nested array that contains other arrays of numbers, such as (1, 2, (1, 2, 3)).
For now, the main points you need to be aware of are that:
- All non-numerical data types (such as images, text, and categories) must eventually be represented as numbers
- In machine learning, the numerical representation will be in the form of an array of numbers — that is, a vector
Scaling Data
Scaling data means transforming it so that the values fit within some range or scale, such as 0–100 or 0–1. This scaling process will not affect the algorithm output since every value is scaled in the same way. But it can speed up the training process.
Two common approaches to scaling data:
Standardization rescales data so that it has a mean of 0 and a standard deviation of 1. The formula for this is:
(𝑥 − 𝜇)/𝜎
Normalization rescales the data into the range [0, 1].
The formula for this is:
(𝑥 −𝑥𝑚𝑖𝑛)/(𝑥𝑚𝑎𝑥 −𝑥𝑚𝑖𝑛)
Encoding Data
when we have categorical data, we need to encode it in some way so that it is represented numerically.
There are two common approaches for encoding categorical data:
- **Ordinal encoding: **convert the categorical data into integer codes ranging from
0to(number of categories – 1).One of the potential drawbacks of this approach is that it implicitly assumes an order across the categories. - **One-hot encoding: **transform each categorical value into a column. One drawback of one-hot encoding is that it can potentially generate a very large number of columns.
Image Data
An image consists of small tiles called _pixels. _The color of each pixel is represented with a set of values:
- In grayscale images, each pixel can be represented by a single number, which typically ranges from 0 to 255. This value determines how dark the pixel appears (e.g.,
0is black while255is bright white). - In colored images, each pixel can be represented by a vector of three numbers (each ranging from 0 to 255) for the three primary color channels: red, green, and blue. These three red, green, and blue (RGB) values are used together to decide the color of that pixel. For example, purple might be represented as
128, 0, 128(a mix of moderately intense red and blue, with no green).
Color Depth or Depth:
The number of channels required to represent a color in an image.
- RGB depth = 3 (i.e each pixel has 3 channels)
- Grayscale depth= 1
Encoding an Image:
We need to know the following three things about an image to in order to encode it:
- Horizontal position of each pixel
- Vertical position of each pixel
- Color of each pixel
We can fully encode an image numerically by using a vector with three dimensions. The size of the vector required for any given image would be:
Size of Vector = height * weight * depth
Image Data is normalized to subtract per channel mean pixel values
Trending AI Articles:
The Commercial State of the Art in 20202. This Entire Article Was Written by Open AI’s GPT23. Learning To Classify Images Without Labels4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
Other Preprocessing Steps:
In addition to encoding an image numerically, we may also need to do some other preprocessing steps. Generally, we would want to ensure the input images have:
- Uniform aspect ratio
- Normalized
- Rotation
- Cropping
- Resizing
- Denoising
- Centering
Text Data
Normalization:
Text normalization is the process of transforming a piece of text into its canonical (official) form.
- Lemmatization: example of Normalization; the process of reducing multiple inflections to a single dictionary form
- Lemma: dictionary form of a word e.g. is -> be
- Stop-words: high-frequency unwanted words during the analysis
- **Tokenize: **split each string of text into a list of smaller parts or tokens
Vectorization:
The next step after Normalization is to actually encode the text in a numerical form called vectorization. There are many different ways that we can vectorize a word or a sentence, depending on how we want to use it. Common approaches include:
- Term Frequency-Inverse Document Frequency (TF-IDF) Vectorization: gives less importance to words that contain less information and are common in documents, e.g. _the, _and to give higher importance to words that contain relevant information and appear less frequently. It assigns weights to words that signify their relevance in the documents.
- Word Embedding: Word2Vec, GloVe
#deep-learning #ai #azure #deep learning #deep learning
