Linear Regression is a popular linear Machine Learning algorithm for regression-based problems. It is usually one of the first algorithms that is learnt when first learning Machine Learning, due to its simplicity and how it builds into other algorithms like Logistic Regression and Neural Networks. In this story we are going to implement it from scratch so that we can build our intuition about what is going on within a Linear Regression model.Link to Github Repo…
kurtispykes/ml-from-scratch
Note: There are many frameworks with highly optimized code such as Scikit-Learn, Tensorflow and PyTorch, therefore it is usually unnecessary to build your own algorithm from scratch. However, it serves a good purpose to our intuition of what is happening within the model when we build it from scratch and this helps when we attempt to improve our models performance.
A linear model is an algorithm that makes a prediction by simply computing a weighted sum of the input features plus a bias term (also referred to as the intercept term). Taking that into perspective, what we are doing when we use a linear regression model is we hope to explain the relationship between a dependent variable (i.e house price) and one or more independent variables (i.e. location, bedrooms, area, etc).
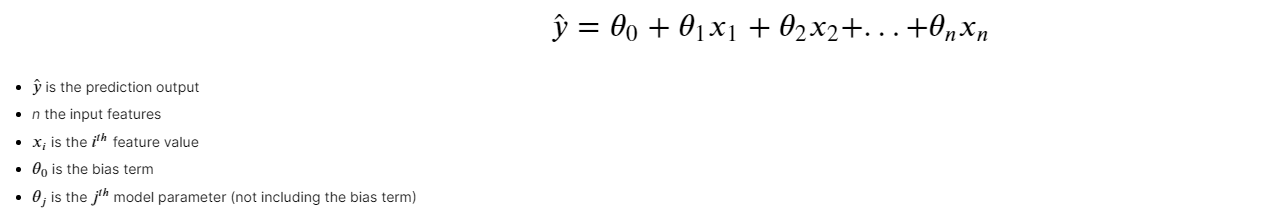
Figure 1: Multiple Linear Regression
When we train a model we are attempting to set the parameters to get a line that best fits the training data. Therefore, when we train a Linear Regression model we are trying to find the value of theta that best minimizes the cost function. The most common cost function of a regression models is the RMSE, however, it is much easier to minimize the MSE as it leads to the same result.
Creating the Model
If you have never written a Machine Learning algorithm from scratch, I greatly encourage you to do so. John Sullivan wrote a very useful story titled 6 Steps To Write Any Machine Learning Algorithm From Scratch: Perceptron Case Study_ w_hich is the best advice I have managed to find on the internet about writing algorithms from scratch.Chunking the Algorithm
- Randomly initialize parameters for the hypothesis functionCalculate the Partial Derivative (Read more about this here)Update parametersRepeat 2–3 for n number of iterations (Until cost function is minimized otherwise)Inference
ImplementationFor this section, I will be leveraging 3 Python packages. NumPy for Linear algebra, Scikit-Learn which is a popular Machine Learning framework and Matplotlib to visualize our data.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
First, we need a dataset. To do this I will sklearn.datasets.make_regression which allows you to generate a random regression problem — see Documentation. Next, I will split my data into training and test sets with sklearn.model_selection.train_test_split — Documentation.
# creating the data set
X, y = make_regression(n_samples=100, n_features=1, n_targets=1, noise=20, random_state=24)
# splitting training and test
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=24)
Lets use matplotlib.pyplot to see how our data looks — Documentation.
# visualize
plt.scatter(X, y)
plt.show()
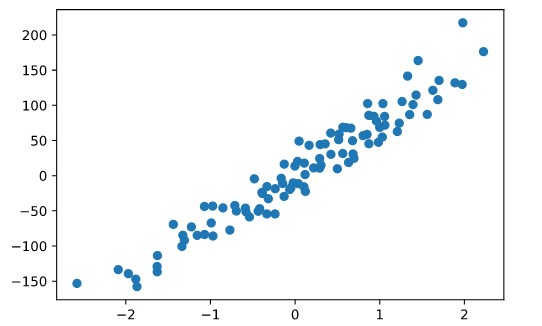
Figure 2: Our generated regression problem
Now we can begin our implementation of Linear Regression. The first step of our chunk is to randomly initialize parameters for our hypothesis function.
def param_init(X):
"""
Initialize parameters for linear regression model
__________________
Input(s)
X: Training data
__________________
Output(s)
params: Dictionary containing coefficients
"""
params = {} # initialize dictionary
_, n_features = X.shape # shape of training data
# initializing coefficents to 0
params["W"] = np.zeros(n_features)
params["b"] = 0
return params
Excellent. Next we want to calculate the partial derivatives and update our parameters. We do this using a very important Machine Learning algorithm called Gradient Descent. Ergo, we can implement steps 2–4 with Gradient Descent.
#algorithms-from-scratch #machine-learning #data-science #algorithms