Shilpa was immensely happy with her first job as a data scientist in a promising startup. She was in love with SciKit-Learn libraries and especially Pandas. It was fun to perform data exploration using the Pandas dataframe. SQL like interface with quick in-memory data processing was more than a budding data scientist can ask for.
As the journey of startup matured, so did the amount of data and it started the chase of enhancing their IT systems with a bigger database and more processing power. Shilpa also added parallelism through session pooling and multi-threading in her Python-based ML programs, however, it was never enough. Soon, IT realized they cannot keep adding more disk space and more memory, and decided to go for distributed computing (a.k.a. Big Data).
What should Shilpa do now? How do they make Pandas work with distributed computing?
Does this story look familiar to you?
This is what I am going to take you through in this article: the predicament of Python with Big Data. And the answer is PySpark.
What is PySpark?
I can safely assume, you must have heard about Apache Hadoop: Open-source software for distributed processing of large datasets across clusters of computers. Apache Hadoop process datasets in batch mode only and it lacks stream processing in real-time. To fill this gap, Apache has introduced Spark (actually, Spark was developed by UC Berkley amplab): a lightning-fast in-memory real-time processing framework. Apache Spark is written in the Scala programming language. To support Python with Spark, the Apache Spark community released PySpark.
PySpark is widely used by data science and machine learning professionals. Looking at the features PySpark offers, I am not surprised to know that it has been used by organizations like Netflix, Walmart, Trivago, Sanofi, Runtastic, and many more.
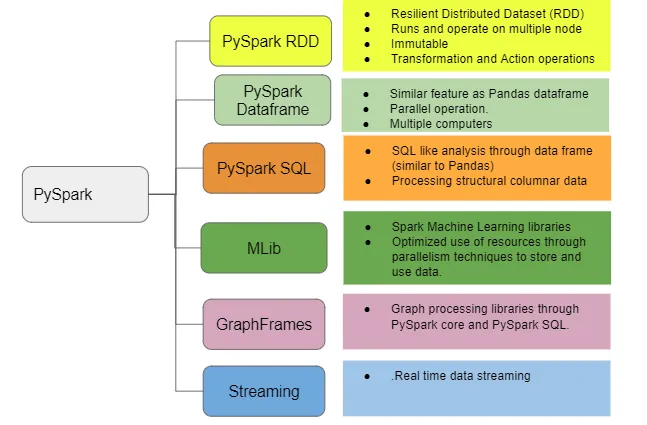
The below image shows the features of Pyspark.
#big-data #data-science #pyspark #python #spark