Transformer models have become the defacto standard for NLP tasks. As an example, I’m sure you’ve already seen the awesome GPT3 Transformer demos and articles detailing how much time and money it took to train.
But even outside of NLP, you can also find transformers in the fields of computer vision and music generation.
This article was written by Rahul Agarwal (WalmartLabs) and has been reposted with permission
That said, for such a useful model, transformers are still very difficult to understand. It took me multiple readings of the Google research paper first introducing transformers, and a host of blog posts to really understand how transformers work.
So, in this article I’m putting the whole idea down as simply as possible. I’ll try to keep the jargon and the technicality to a minimum, but do keep in mind that this topic is complicated. I’ll also include some basic math and try to keep things light to ensure the long journey is fun.
Here’s what I’ll cover:
- The big picture
- The building blocks of transformer models
- Encoder architecture
- Decoder architecture
- Output Head
- Prediction time
Q: Why should I understand Transformers?
In the past, the state of the art approach to language modeling problems (put simply, predicting the next word) and translations systems was the LSTM and GRU architecture (explained here) along with the attention mechanism. However, the main problem with these architectures is that they are recurrent in nature, and their runtime increases as the sequence length increases. In other words, these architectures take a sentence and process each word in a sequential way, so as the sentence length increases, so does the whole runtime.
The transformer architecture, first explained in the paper “Attention is All You Need”, lets go of this recurrence and instead relies entirely on an attention mechanism to draw global dependencies between input and output.
Below is a picture of the full transformer as taken from the paper. It’s quite intimidating, so let’s go through each individual piece to break it down and demystify it.

The Big Picture
Q: So what does a transformer model do, exactly?
A transformer model can perform almost any NLP task. We can use it for language modeling, translation, or classification, and it does these tasks quickly by removing the sequential nature of the problem. In a machine translation application, the transformer converts one language to another. For a classification problem, it provides the class probability using an appropriate output layer.
Everything depends on the final output layer for the network, but the basic structure of the transformer remains quite similar for any task. For this particular post, let’s take a closer look at the machine translation example.
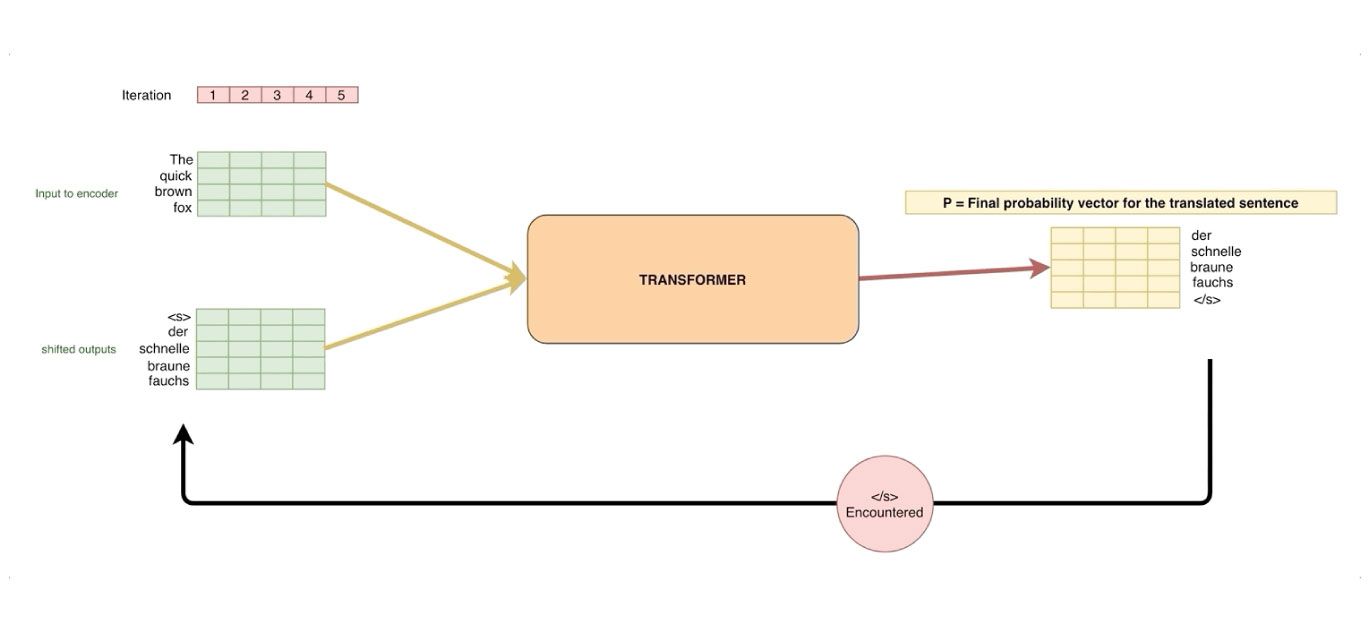
From a distance, the below image shows how the transformer looks for translation. It takes as input an English sentence, and returns a German sentence.

The transformer for translation
#transformers #neural-networks #artificial-intelligence #data-science #machine-learning #ai #language-translation #hackernoon-top-story