In the last post I really discussed GANs (the structure and the steps of the training and the loss function). In this post, I will discuss the limitation and the problem of training a GAN.
1. Introduction
There are many various problems that prevent successful GAN training due to the GANs’ extremely diverse applications. Accordingly, improving the training of the GANs is an open research field for researchers.
Before discussing the problems, let have a quick look at some of the GAN equations.
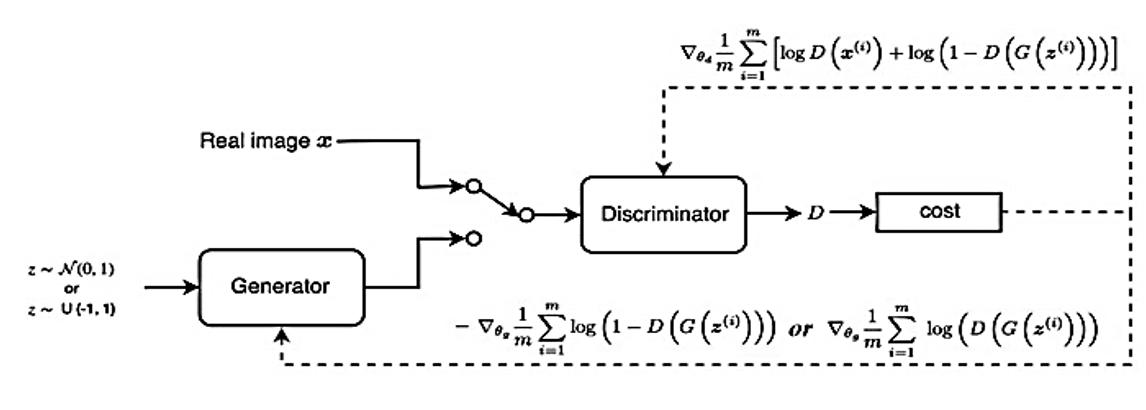
The architecture of the GAN with derivation terms of the loss function
The figure above indicates, the derivation terms of the final loss function for training the discriminator and generator with the corresponding gradient. In the following are some of the basic problems of GAN that lead to hard training.
2. Vanishing gradients
The first problem in the GAN training that should be considered serious is vanishing gradients. Before diving into the Vanishing gradients problem, the KL-divergence and JS-divergence should be explained.
The concept of divergence between two probability distributions can be defined as a measure of the distance between two distributions. Imagine if we minimize the divergence, we also hope that the two distributions are equal.
2.1 KL-Divergence
In many generative models, the goal is to create a model which maximizes the Maximum Likelihood Estimation(shortly MLE) which can be defined as the best model parameters to fit the training data. Maximum likelihood equation is shown in follow.
#kl-and-js-divergence #mode-collapse #nash-equilibrium #problem-of-gan #vanishing-gradient #neural networks