Introduction
In the previous articles, we learned about reinforcement learning basics and Monte Carlo Tree Search basics. We covered how MCTS can search all the state-action space and come up with a good action based on statistics that are gathered after sampling search space.
I have to thank Kenny young for his awesome implementation of mopyhex which helped me a lot in my project. This post mostly includes explaining his code.
Before getting our hands dirty with the code, to give an overview of the project, let me describe each module’s functionality. There are essentially 6 classes to implement for the initial framework:
GameState: This module simply provides every essential information about the state of the game in each node of the tree.UnionFind: This module is a utility module that helpsGameStateto check if 2 sides are connected or not. In other words, with the help of this module, we can detect the game-winner in any state of the game if there exists any.Node: This one implements each node of the tree indicating each game state. Each node has an evaluation function based on the UCT algorithm.UctMctsAgent: This one handles the tree structure for the Monte Carlo Tree Search algorithm.Gui: This module implements a simple graphical user interface usingTkintermodule to enable human and computer interaction in gameplay.MCTSMetaandGameMeta: These modules simply store some constants.
I have implemented some algorithms which use the concept of Rapid Action Evaluation and are stronger than the UCT algorithm in short-period searches. and make it even stronger. I am going to cover the concept of those algorithms later.
Gamestate module:
In each game state tree search agent needs three things to know to be able to transit from one state to another:
- Which player turn it is.
- The unoccupied board cells (The available moves to choose).
- Ability to detect the connection between both sides for both black and white players.
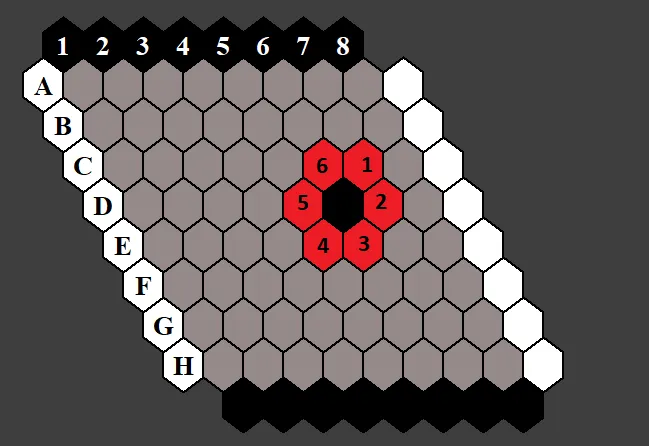
The latter one is pretty tricky to implement. Because to detect connections, we have to keep track of the disjoint groups of cells. So we have to make use of a data structure namely as Disjoint sets (also called Union find). But the fact that HEX game board cells are connected to its neighbors from 6 sides, makes it even trickier to implement. Check out the below image:
#data-science #ai #reinforcement-learning #python #machine-learning