Introduction
AWS or Amazon Redshift is a columnar data warehouse service that is generally used for massive data aggregation and parallel processing of large datasets on the AWS cloud. AWS S3, on the other hand, is considered as the storage layer of AWS Data Lake and can host the exabyte scale of data. Generally, data lands on on-premise sources using various mechanisms on data repositories like S3, from where it is transported to different data repositories like Amazon Redshift for use-case specific processing and consumption. In this article, we will learn how to load data from Amazon S3 to Amazon Redshift cluster using a command from Amazon Redshift.
AWS S3 and AWS Redshift Setup
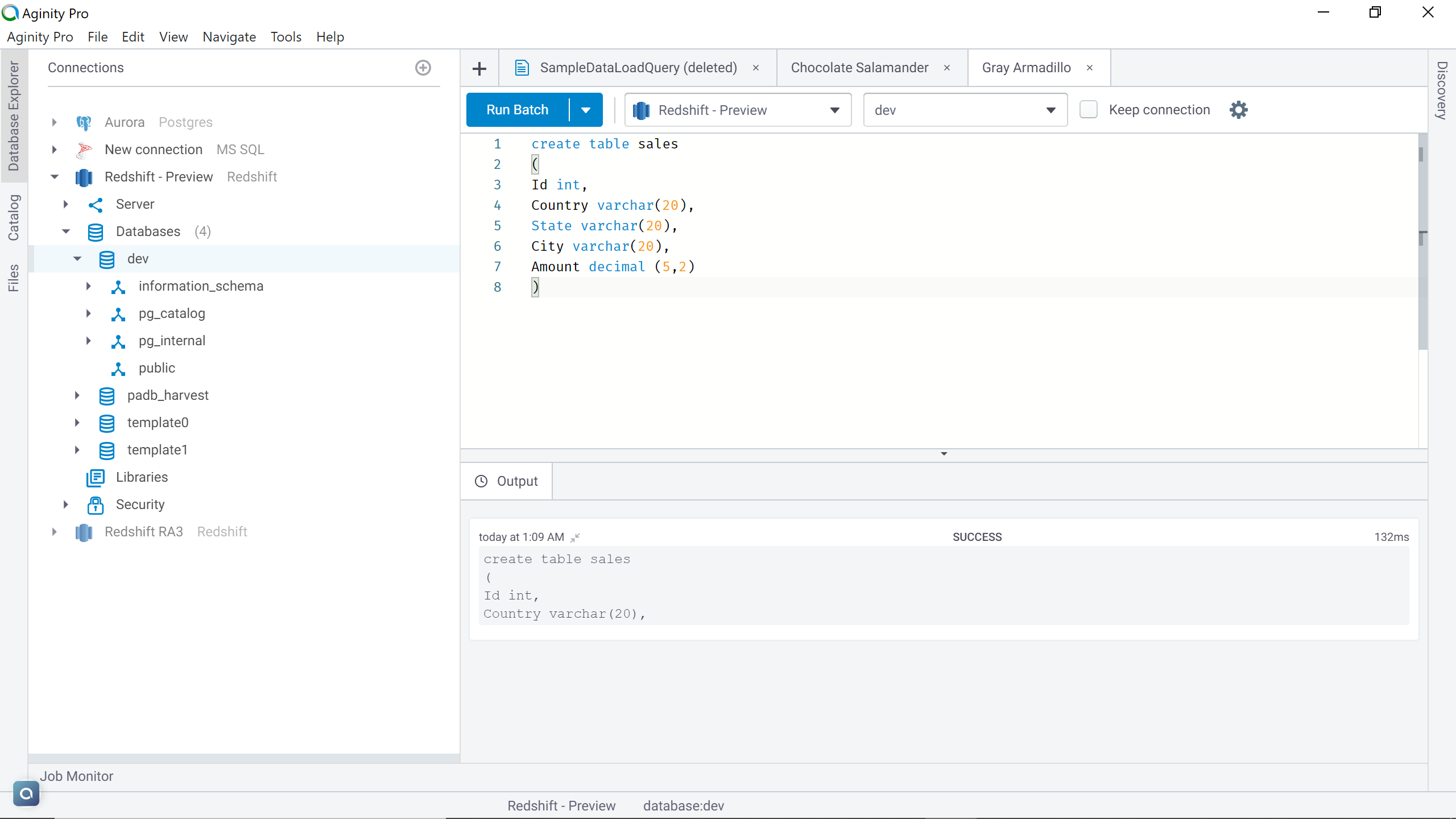
To start with our exercise, we need an AWS S3 bucket, an AWS Redshift cluster as well as a sample data file stored in the Amazon S3 bucket. We learned in my previous articles, Getting started with AWS Redshift and Access AWS Redshift from a locally installed IDE, how to create an AWS Redshift cluster and how to connect to the same using an IDE of choice. It’s recommended to set it up before proceeding with this exercise. Assuming that the setup is in place, we need to create a table in the redshift cluster, which will be used as the destination to copy the data from the Amazon S3 bucket, as shown below.
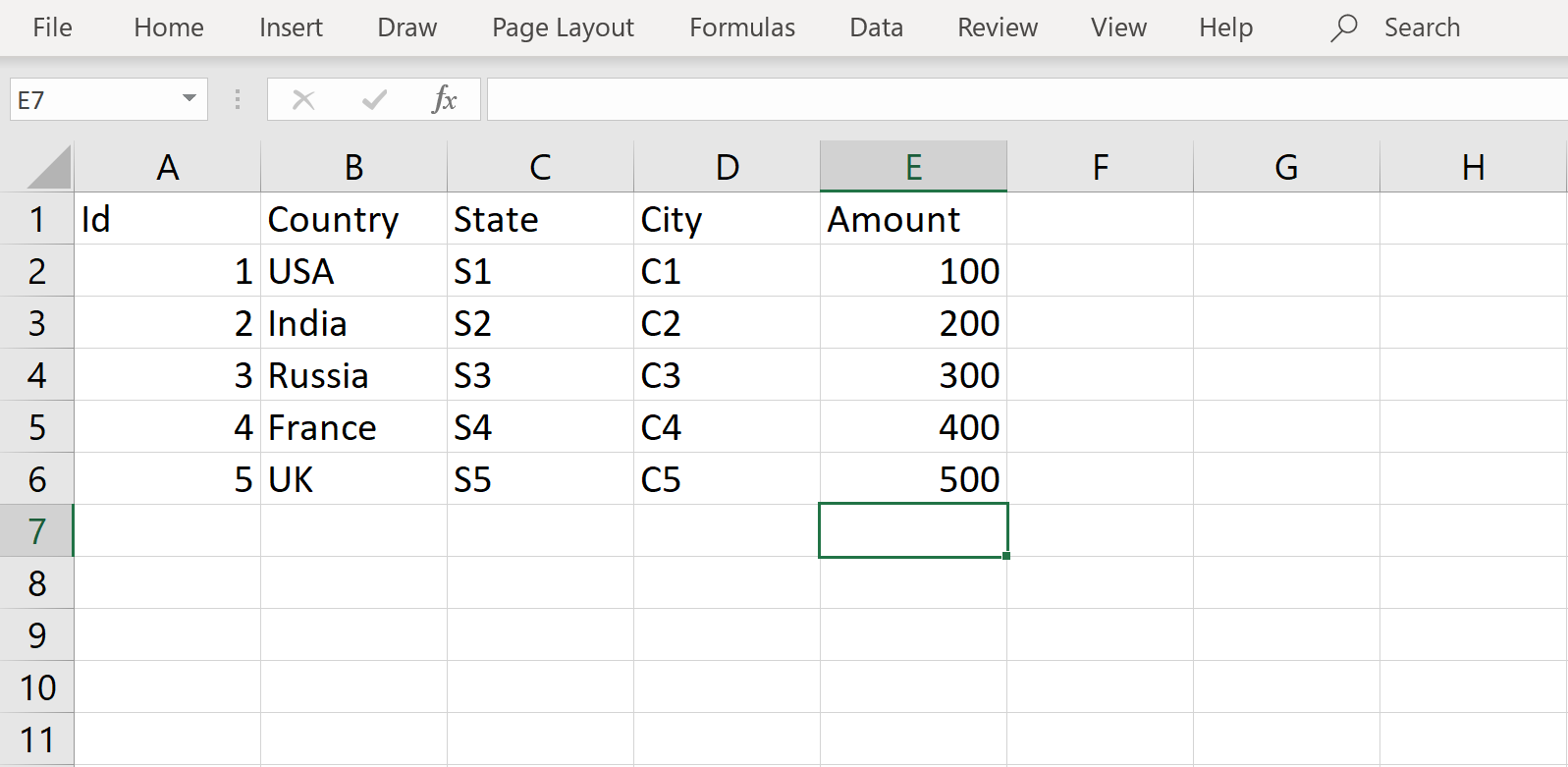
We intend to use a source file from which we would copy the data to the AWS Redshift cluster. Shown below is a sample file that has an identical schema to the table that we created in the previous step. We can have a different schema as well, but to keep the focus on the copying process instead of mapping or transformation techniques, the schema is kept identical here.
Once the file is created, upload the same to an AWS S3 bucket of choice as shown below. Here we have one additional file apart from the one we just uploaded just to demonstrate that we can load the desired file from a list of files that may be stored in the same bucket on Amazon S3.
#aws