The Problem Statement
We are trying to render a 3D animation of a person by tracking their motion from 2D video.
Why did we choose this statement?
Animating a person in 3D graphics requires a huge set up with motion trackers to track the person’s movements and also takes time to animate each limb manually. We aim to provide a time-saving method to do the same.
How did we solve it?
Our solution to this problem involves the following steps:
- **2D Pose Estimation: **The human body requires at least 17 landmark points to fully describe their pose.
- DeepSORT+FaceReID: To track the movement of the poses.
- Uplifting 2D to 3D: The coordinates we get from the previous step are in 2D. To animate them in 3D, we need to map these 2-dimensional coordinates into a 3-dimensional space.
- Rendering to 3D: The coordinates of these 17 landmark points detected in the previous step will now be the positions of the joints of limbs of the 3D character required to be animated.
Let’s talk about these steps in detail in the rest of the article.
2D Pose Estimation
As mentioned above, a human pose can be fully described by specifying just 17 key essential points (known as landmark points in the deep learning community). You may have guessed, we are estimating the humans’ poses (i.e. tracking a human’s pose across frames of a video) using deep learning. There are quite a few state-of-the-art frameworks (such as PoseFlow and AlphaPose) that can be found online (and by online, I mean on Github) that have already implemented pose estimation to a decent level of accuracy.
- PoseFlow: The first framework is PoseFlow which was developed by Yuliang Xiu et al. The basic overview of PoseFlow’s algorithm is that the framework first builds poses by maximizing overall confidence across all frames of the video. The next step is to remove redundant poses detected using a technique called non-maximum suppression (commonly abbreviated as NMS).
- AlphaPose: You can see in the GIF attached below, that poses being estimated using PoseFlow (on the left) have minor glitches in some of the frames. This brings us to the next framework: AlphaPose. AlphaPose was developed by Hao-Shu Fang et al. This framework draws bounding boxes around people detected in the frame and estimates their pose in each frame. It can also detect poses even when a person is partially occluded by another person.
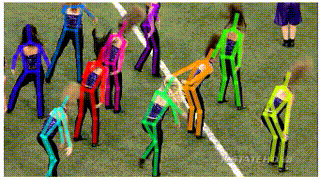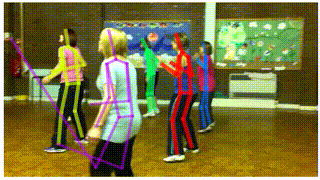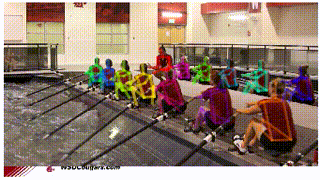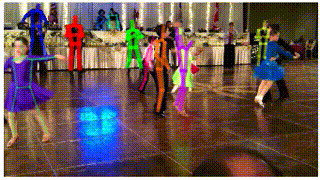

PoseFlow on the left. AlphaPose on the right. GIFs Source: https://github.com/MVIG-SJTU/AlphaPose
The code for the AlphaPose framework can be found here.
DeepSORT + FaceReID
We’ve used Alpha Pose to detect the poses of humans present in a video. The next step is to track their movements to be able to build a smooth moving animation. The research paper for the DeepSORT framework can be found here.
Using the output of DeepSORT and FaceReid bounding boxes, we segregate the poses of different persons in the following manner.
#deep-learning #unity #computer-vision #human-pose-estimation
