Web scraping allows us to extract information from web pages. In this tutorial, youll learn how to build web scraping with Python.
Introduction
If you are into data analysis, big data, machine learning or even AI projects, chances are you are required to collect data from various websites. Python is very commonly used in manipulating and working with data due to its stability, extensive statistical libraries and simplicity (these are just my opinions). We will then use Python to scrape a the trending repositories of GitHub.
Prerequisites
Before we begin this tutorial, please set up Python environment on your machine. Head over to their official page here to install if you have not done so.
In this tutorial I will be using Visual Studio Code as the IDE on a Windows Machine, but feel free to your IDE of choice. If you are using VS Code, follow the instructions here to set up Python support for VS Code.
We will also be installing Beautiful Soup and Request modules from Python in our virtual environment later.
Request library allows us to easily make HTTP requests while BeautifulSoup will make scraping much easier for us.
Tutorial
Let’s first look into what we will be scraping:
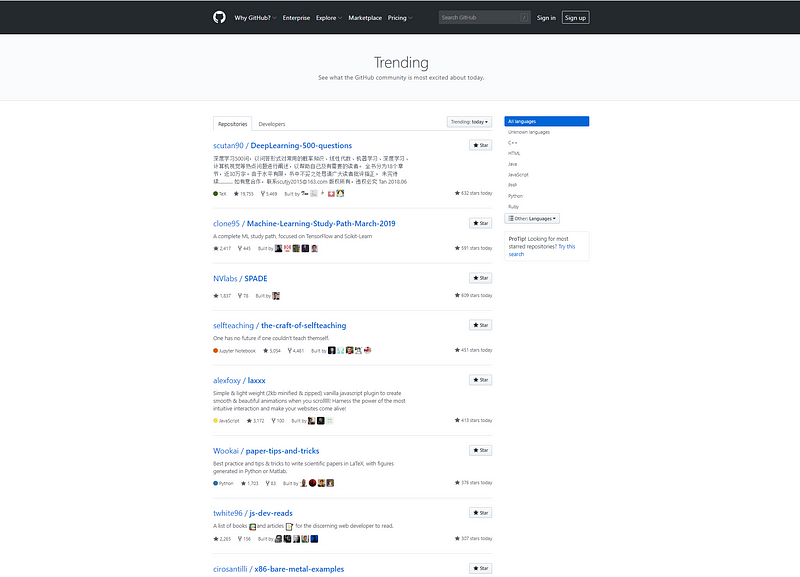
GitHub Trending Page
What we will be doing is extracting all the information about the trending repositories such as name, stars, links etc.
Creating the project
Make a folder somewhere on your disk and let’s call it python-scraper-github. Navigate to the folder and let’s first create a virtual environment.
python -m venv env
Wait for this to be completed, and you will realize that this creates a folder called env in the root of our project. This will contain all the necessary packages that Python would need. All the installation of new modules will be installed into this folder.
A virtual environment is a tool that helps to keep dependencies required by different projects separate by creating isolated python virtual environments for them. This is one of the most important tools that most of the Python developers use.
Typecode .in the command line to open up the folder in VS Code or just find the folder to open in the main VS Code window.
How our project will look
Press ctrl + shift + p to open up all the commands and select the command Python: Select Interpreter like below and select the env


Choose our env folder as the interpreter
Great, now that you have setup the interpreter, we can start a terminal in our folder. Open up a new terminal by Terminal -> New Terminal. You will see that the first line will be something similar to
(env) PS E:\Projects\Tutorials\python-scraper-github>
That is because when we open a new terminal via VS Code, it automatically activates our virtual environment.
Installing Dependencies
While in the terminal, enter the following (pip comes pre-installed with Python 2.7.9 / 3.4 and above) :
pip install requests beautifulsoup4
Now that we are done installing the modules, let’s create a new file and call it scraper-github-trending.py
import requests
from bs4 import BeautifulSoup
# Collect the github pagepage = requests.get('https://github.com/trending')
print(page)
We have imported the libraries, and then make request to get the GitHub trending page. Let’s run this file and see what is the output.
To run a particular python file, right click on the File ->Run Python File In Terminal
<Response [200]>
This will be output we get. Great, response 200 means that the page was fetched successfully. Let’s now use our Beautiful Soup module to create an object. Add the below into the file.
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
print(soup)

Output when running this new file
When we run the file, we can get the entire html page of the GitHub trending page! Let’s now explore how we can extract the useful data.
Extracting data

Highlighted shows ‘repo-list’
Head over to your browser (Chrome in this case) and open up the GitHub Trending Page. Click inspect anywhere, and you can see that the entire body of our wanted data is in the tag <div class="repo-list"> so the class repo-list should be our initial focus.

Each individual repository information
Next, we can see that each of the repositories are defined in the <li class='col-12 d-block width-full py-4 border-bottom'> This is what we will retrieve next
import requests
from bs4 import BeautifulSoup
page = requests.get('https://github.com/trending')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
# get the repo list
repo = soup.find(class_="repo-list")
# find all instances of that class (should return 25 as shown in the github main page)
repo_list = repo.find_all(class_='col-12 d-block width-full py-4 border-bottom')
print(len(repo_list))
scraper-github-trending.py hosted with ❤ by GitHub
Your code should now look like this. If you run this script now, the output should show 25
Next we will iterate through each of the list to retrieve the desired information.
Repository Name
Highlighted shows the tag that displays full repository name
The above snip shows that the full repository name occurs under the very first <a> tag. We can extract the text from. Since the it returns a string with / in between them, we can split the string using / to get an array of string. First index will have the developer name and the next index will have the repository name.
Number of Stars
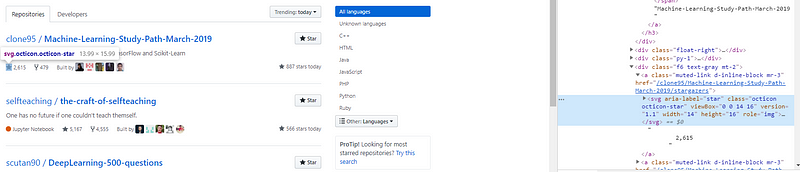
Stars are defined using tag with class
Since not all repository contain the number of stars as the first element, we cannot use the position to retrieve the number of stars. However, we can see that the <svg> that defines the star and the number of stars itself are under the same parent. So if we get the <svg> by using the class octicon octicon-star we can get the parent and then extract the text (which will be the number of stars).
For loop
import requests
from bs4 import BeautifulSoup
page = requests.get('https://github.com/trending')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
# get the repo list
repo = soup.find(class_="repo-list")
# find all instances of that class (should return 25 as shown in the github main page)
repo_list = repo.find_all(class_='col-12 d-block width-full py-4 border-bottom')
print(len(repo_list))
for repo in repo_list:
# find the first <a> tag and get the text. Split the text using '/' to get an array with developer name and repo name
full_repo_name = repo.find('a').text.split('/')
# extract the developer name at index 0
developer = full_repo_name[0].strip()
# extract the repo name at index 1
repo_name = full_repo_name[1].strip()
# find the first occurance of class octicon octicon-star and get the text from the parent (which is the number of stars)
stars = repo.find(class_='octicon octicon-star').parent.text.strip()
# strip() all to remove leading and traling white spaces
print('developer', developer)
print('name', repo_name)
print('stars', stars)
scraper-github-trending.py hosted with ❤ by GitHub
I have already implemented the loop as shown above. For each item in our repo_list (which contains 25 items), let’s find the developer, repo name and the stars.
Run the above code and the output should be something like this:

Output showing the 3 field information requested
Great! We can print what we have set out to achieve. Printing is good on its own, but it would be even better if we can store it somewhere, such as on a csv file. So let’s save this information there.
Saving it as CSV
First we need to import the built-in csv module as such:
import csv
Then we need to open a file and write the headers into our csv file:
# Open writer with name
file_name = "github_trending_today.csv"
# set newline to be '' so that that new rows are appended without skipping any
f = csv.writer(open(file_name, 'w', newline=''))
# write a new row as a header
f.writerow(['Developer', 'Repo Name', 'Number of Stars'])
Next, in the for loop, we need to write a new row into our csv file
f.writerow([developer, repo_name, stars])
That is all you need to save the trending information onto our csv file!
import requests
from bs4 import BeautifulSoup
import csv
page = requests.get('https://github.com/trending')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
# get the repo list
repo = soup.find(class_="repo-list")
# find all instances of that class (should return 25 as shown in the github main page)
repo_list = repo.find_all(class_='col-12 d-block width-full py-4 border-bottom')
print(len(repo_list))
# Open writer with name
file_name = "github_trending_today.csv"
# set newline to be '' so that that new rows are appended without skipping any
f = csv.writer(open(file_name, 'w', newline=''))
# write a new row as a header
f.writerow(['Developer', 'Repo Name', 'Number of Stars'])
for repo in repo_list:
# find the first <a> tag and get the text. Split the text using '/' to get an array with developer name and repo name
full_repo_name = repo.find('a').text.split('/')
# extract the developer name at index 0
developer = full_repo_name[0].strip()
# extract the repo name at index 1
repo_name = full_repo_name[1].strip()
# find the first occurance of class octicon octicon-star and get the text from the parent (which is the number of stars)
stars = repo.find(class_='octicon octicon-star').parent.text.strip()
# strip() all to remove leading and traling white spaces
print('developer', developer)
print('name', repo_name)
print('stars', stars)
print('Writing rows')
# add the information as a row into the csv table
f.writerow([developer, repo_name, stars])
This is what our script looks like finally. Once you run in, you will a new file github_trending_today.csv appear in our folder. If you open it it will look like this:
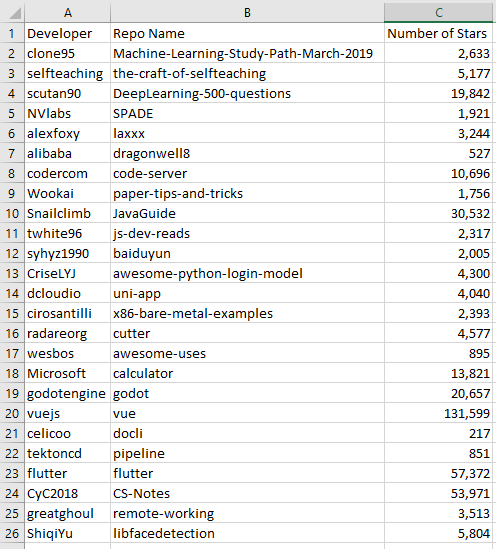
Scraped Information
Great! You have completed a simple tutorial to extract website information using python!
Final Thoughts
The availability of various useful modules makes it incredibly simple for us to scrape data from websites for our projects. However, there is still a lot of work that needs to go into extracting the data accurately and cleaning up the data before it can be used to yield useful results.
Furthermore, if the structure of the website, such as the class names, tags or id change, the script needs to be changed accordingly, thus we need to further think about the maintainability of the script.
I hope this has been useful for those looking to extract various information on your own from scratch! You can create multiple scripts for each web page you wish to scrape, all in the same project.
If anyone finds these useful, feel free to share this or let me know should there be an error / bad practice / implementations.
#python #web-development
