When working with data science and machine learning projects, we will have to spend a lot of time analyzing the data and performing data preprocessing activities to clean the dataset. Pandas is undoubtedly the most widely-used open-source library for data science and analysis, mostly preferred for ad-hoc data manipulation operations. It is very likely that the dataset we use might contain missing data , null values or duplicate data for which we would like to modify the data accordingly , or we might just want to drop the column because we think that the feature is not important for creating the model.
In my last blog, I already discussed dropna() and fillna() functions in Pandas, which can be used to deal with the missing data or NaN values. As a continuation to that, I want to discuss two other powerful in-built functions in Pandas, drop() and drop_duplicates() which are widely used for data preprocessing activities, in this blog.
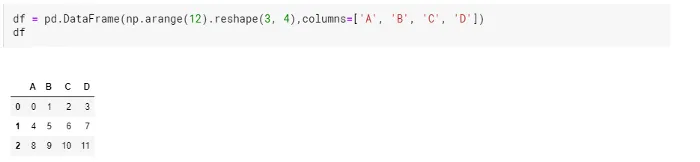
Let’s begin by importing the Pandas library.

Pandas : drop() function
Pandas drop() function is used for removing or dropping required rows and/or columns from dataframe.
Syntax:

The definition of the parameters in the syntax are as follows:
- labels: single label or list — In this parameter index or column names which are required to be dropped are provided.
- axis: default 0 — It refers to the orientation (row or column) in which data is dropped. If specified as 0, it will be dropped from index(rows) and if specified as 1, it will be dropped from columns.
- **inplace: **This parameter takes a boolean value. This makes the changes in the DataFrame itself if True. If false, the original DataFrame is not modified , but a separate copy with the changes (i.e. dropped rows/columns) is returned.
#pandas #drop-pandas #data-preprocessing #data-analysis #data-science