The title of this blog post is pretty much the tl;dr of what I have tried (and somewhat succeeded) to do, although I was probably grossly under qualified to try it in the first place. My idea was to collect data from the brain when the subject is thinking about saying certain words. From there, I would train a machine learning categorisation algorithm with the collected data and use the resulting model to then read the subject’s brainwaves in real time and categorise them into words they may be trying to say. The desired result would be an app that is reading the thoughts of a person who is trying to speak and output those words to those they are trying to communicate with.
This came about after my grandmother was diagnosed with a form of Motor Neuron Disease called Bulbar Palsy and it began to affect the way she talked. I began to think of ways that she could be able to communicate as the condition got worse. The doctors she was seeing had provided her with an iPad that was inadequate and just wasn’t working for her. Italian is her first language and when she tries to spell English words they just don’t come out right using Apple’s text to speech engine. I managed to switch an android phone’s text to speech engine to Google’s text to speech engine, this allowed her to use a speaker with an Italian accent that is supposed to be used to convert Italian text into Italian speech. Funnily enough, when she wrote in English using the engine that was supposed to be talking Italian you could understand what she was trying to say.
The next problem to consider was what if she lost the use of her hands, or if someone was trying to use this method who couldn’t spell, like many others my grandmother’s age. This is when I thought of using machine learning to convert brainwaves into words. I don’t know that much about brain waves, also at the time I had only been feverishly reading and evangelizing about Machine Learning, not actually putting it into practice.
Reading Brain Waves
I saw an Electroencephalograph (EEG) readout somewhere and realised that these readings must be comprised of raw numbers coming from the brain, so how hard could it be to parse them with some kind of software. I was half way through a YouTube video that had a guy sticking wet sponges attached to wires to his head when I saw another video about the NeuroSky MindWave Mobile headset. You can read an article from Scientific American about it here, but it’s essentially a device used to make games and meditation apps that fit two of my needs:
-
It reads brainwaves, and
-
It has an API I could use to read those brainwaves in a raw number format.
I didn’t want any internal software playing with my data, and although the MindWave has an internal processor that does that to determine how relaxed or attentive you are, it also allows you to get a raw EEG reading that’s easily split into the correct type of brainwave categories.
I knew from reading Neurosky’s documentation that the SDK would parse the data from the brain and place it in the following frequency bands:
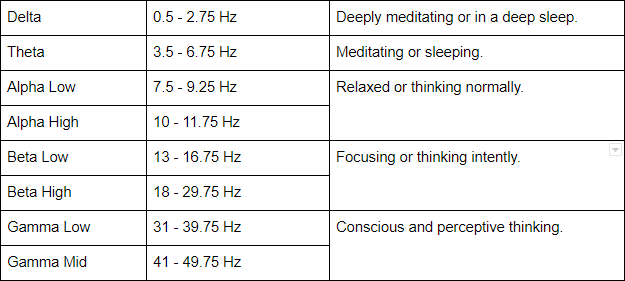
The connection between these values and my idea is that these categories of brain waves are used to interpret different states of the brain, as described in the right column of the table above. More importantly, I could pass these values to a machine learning algorithm to have it predict what a person is thinking when it identifies a certain pattern in these values. The reason I wanted to rely on a machine learning algorithm for categorisation was because I knew there would be noise and variance in the data that I would not reliably be able to filter out myself with basic conditionals within my code.
Python Prototype
Before I forked out $150 for the headset I decided to build a software prototype just to test that my idea would actually go somewhere. I completed a Microsoft Machine Learning Studio course first and then played around with some test experiments involving housing data; predicting house prices etc. Once I was happy navigating around and becoming familiar with the capabilities of the different algorithms, I went into mocking up some EEG data using Python. In Python I used the following script which I have uploaded to GitHub to generate my test data into one csv file which I was then able to upload into my Machine Learning experiment in Azure. I made the data overlap in an attempt to simulate some variance and noise that would occur in real data. I threw together a machine learning experiment to test my simulated data and after I was satisfied with the results I ordered the headset from Neurosky.
The System
I then went on to design an overall system so that I would be able to work towards something and not lose track of what I was doing. I named my project Cerasermo and came up with the following rough system diagram…
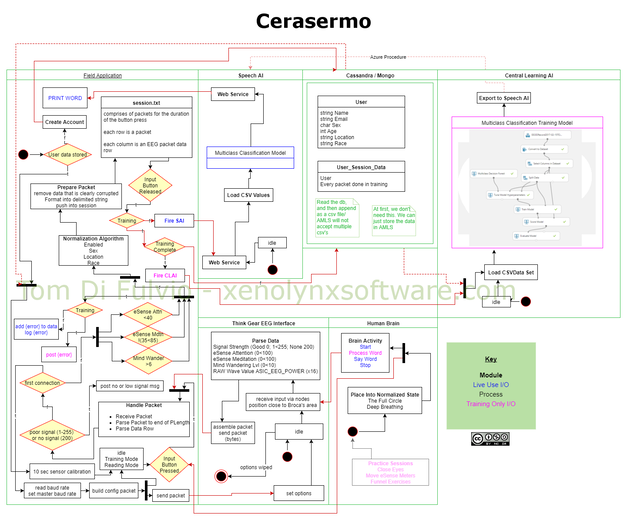
The System includes various sub systems such as a database to hold user data and a potentially large amount of EEG data. I also had a few small subroutines planned to do things that I thought I may need to do when parsing the data from the brain. One such subroutine would handle the fact that I would need to normalise the data depending on the subjects sex and possibly other factors that I was not yet aware of. The idea for this I got from this exchange between Ingrid Nieuwenhuis and Frederic Roux where they discuss that male and female EEG data can different. The actual implementation to normalise the data across subjects that I planned to adapt was posted about on R-Bloggers. For the time being however the implementation was to be specific for single subjects; myself and eventually my grandmother.
Android App
I began to write a Xamarin application as I am familiar with the framework and had previous experience sending a C# Xamarin Android app to the Google Play store. I ran into problems when I went to add bluetooth to the implementation as Xamarin did not support regular bluetooth at the time (there was only low powered bluetooth implementations). This forced me to switch to Android Studio and consequently to translate the language of my app from C# to Java. I ended up with an extremely simplified version of the planned Cerasermo system; I got my app to a point where it was reading and exporting EEG data from the headset to a file. This entire process, including uploading to my Azure Machine Learning Experiment, was extremely slow and eventually the system will need to be completed if it’s to be used as I planned in day to day conversation.
Azure Machine Learning
I used the following machine learning experiment in which I split my data in two so that I could train and test my two shortlisted algorithms side by side…

My two classification algorithms here are the Multiclass Decision Forest, and the Multiclass Neural Network. I used Microsoft’s Tune Model Hyperparameters Module with entire grid sweeping in order to automatically select the best parameters for the each of the two models. With the help of this fantastic cheat sheet, I decided to go with the Multiclass Decision Forest algorithm as I knew it would be difficult to get a lot of data and I needed a model that would be easy to train in a short amount of time with limited data. Also, from what I understand with the algorithm itself, this model is based on building non-linear decision boundaries and I thought this would work well as a classification model. I chose the Multiclass Neural Network algorithm to test against more out of curiosity.
I initially chose the words ‘yes’ and ‘no’ to detect as I felt they were emotional opposites of each other. After getting near 100% prediction accuracy on both models I decided to add the words ‘water’, ‘food’, ‘happy’, and ‘sad’. I felt the types of words I was trying to detect were opposites of one another in an emotional sense, and therefore would have vastly varying resulting brainwave patterns, making them easier to categorise. I fed the algorithm most of the data coming from the headset including the raw value of the EEG signal, the categorised signal values, and the attention, meditation, and blink values. I recorded data in five 30 second intervals for each word.
The results for the two algorithms are below with the Multiclass Decision Forest on the left and the Multiclass Neural Network on the right…

It’s worth noting that as well as being more accurate than the Multiclass Neural Network, the Multiclass Decision Forest was much faster to train. I am not sure why the Multiclass Neural Network did not do a better job of categorising the EEG data, but I think it has something to do the amount of data I was feeding the model. I may need to record much more data for the algorithm to work with. Applying weightings to the fields in my data set may also help with this.
I removed the Multiclass Neural Network from my experiment and retrained the model before testing it with actual data. When testing, I found that the resulting model was extremely accurate; about 95% with it incorrectly predicting water once in a series of 20 tests. This is perfectly expected when you look the Confusion Matrix above.
Reflection on the Results
Interestingly, when I tested the model again the next morning, my result were less accurate, and I think that this has something to do with the state of the brain being different after some time and at a different time of the day. The brain could be sending out different signals when processing the words depending on factors such as mood, hunger, thirst, and your surroundings. In order to mitigate this, I have thought of including some kind of pre-training ,almost meditation, routine in order to center the mind to provide a more standardised reading. I could achieve this by potentially showing the subject a certain pattern or object along with a sound (in case they lose their vision down the track, they would still have a cornerstone to rely on)
Even though my grandmother will probably not be able to benefit from this endeavour, I think it’s worth continuing this experiment as it may be able to help others who are in a similar or worse situation.I am currently collecting data from my grandmother over a long period of time and at different times of the day in order to counter the inaccuracies I experienced the morning after training. I expect with this new data I will probably need to reconfigure the algorithms.
Although this experiment is amature, I imagine that something like this can be used for many different purposes, such as people who are immobile, or it could even be used as a form of security or a kind of telepathy like communication method. Another way to train the model could be to have it listen and record you all the time. After spending the day with you and hearing you speak it would know what to expect when you think to say certain words, therefore increasing your potential vocabulary.
In a future blog post I plan to go more into the maths of this solution as I one day want to use my own algorithm instead of Microsoft’s one in the interest of cost, and I hope, speed.
Feel free to comment here or get in touch. Having someone actually review and provide feedback on my work would be great and very welcome. I am doing this in my spare time and am somewhat disconnected from others in this field and would love feedback and/or advice.
#machine-learning #python #data-science
