Today, we will study the N-Grams approach and will see how the N-Grams approach can be used to create a simple automatic text filler or suggestion engine.
Automatic text filler is a very useful application and is widely used by Google and different smartphones where a user enters some text and the remaining text is automatically populated or suggested by the application.
Problems with TF-IDF and Bag of Words Approach
Before we go and actually implement the N-Grams model, let us first discuss the drawback of the bag of words and TF-IDF approaches.
In the bag of words and TF-IDF approach, words are treated individually and every single word is converted into its numeric counterpart. The context information of the word is not retained. Consider two sentences “big red machine and carpet” and “big red carpet and machine”. If you use a bag of words approach, you will get the same vectors for these two sentences. However, we can clearly see that in the first sentence we are talking about a “big red machine”, while the second sentence contains information about the “big red carpet”. Hence, context information is very important. The N-Grams model basically helps us capture the context information.
Theory of N-Grams Model
Wikipedia defines an N-Gram as “A contiguous sequence of N items from a given sample of text or speech”. Here an item can be a character, a word or a sentence and N can be any integer. When N is 2, we call the sequence a bigram. Similarly, a sequence of 3 items is called a trigram, and so on.
In order to understand N-Grams model, we first have to understand how the Markov chains work.
Connection of N-Grams with Markov Chains
A Markov chain is a sequence of states. Consider a Markov system with 2 states, X and Y. In a Markov chain, you can either stay at one state or move to the other state. In our example, our states have the following behavior:
- The probability of moving from X to Y is 50% and similarly, the probability of staying at X is 50%.
- Likewise, the probability of staying at Y is 50% while the possibility of moving back to X is also 50%.
This way a Markov sequence can be generated, such as XXYX, etc.
In an N-Grams model, an item in a sequence can be treated as a Markov state. Let’s see a simple example of character bigrams where each character is a Markov state.
Football is a very famous game
The character bigrams for the above sentence will be: fo, oo, ot, tb, ba, al, ll, l, i, is and so on. You can see that bigrams are basically a sequence of two consecutively occurring characters.
Similarly, the trigrams are a sequence of three contiguous characters, as shown below:
foo, oot, otb, tba and so on.
In the previous two examples, we saw character bigrams and trigrams. We can also have bigrams and trigrams of words.
Let’s go back to our previous example, “big red machine and carpet”. The bigram of this sentence will be “big red”, “red machine”, “machine and”, “and carpet”. Similarly, the bigrams for the sentence “big red carpet and machine” will be “big red”, “red carpet”, “carpet and”, “and machine”.
Here in this case with bigrams, we get a different vector representation for both of the sentences.
In the following section, we will implement the N-Grams model from scratch in Python and will see how we can create an automatic text filler using N-Grams like these.
N-Grams from Scratch in Python
We will create two types of N-Grams models in this section: a character N-Grams model and a words N-Gram model.
Characters N-Grams Model
In this section, I will explain how to create a simple characters N-Gram model. In the next section, we will see how to implement the word N-Gram model.
To create our corpus, we will scrape the Wikipedia article on Tennis. Let’s first import the libraries that we need to download and parse the Wikipedia article.
import nltk
import numpy as np
import random
import string
import bs4 as bs
import urllib.request
import re
We will be using the Beautifulsoup4 library to parse the data from Wikipedia. Furthermore, Python’s regex library, re, will be used for some preprocessing tasks on the text.
As we said earlier, we will use the Wikipedia article on Tennis to create our corpus. The following script retrieves the Wikipedia article and extracts all the paragraphs from the article text. Finally, the text is converted into the lower case for easier processing.
raw_html = urllib.request.urlopen('https://en.wikipedia.org/wiki/Tennis')
raw_html = raw_html.read()
article_html = bs.BeautifulSoup(raw_html, 'lxml')
article_paragraphs = article_html.find_all('p')
article_text = ''
for para in article_paragraphs:
article_text += para.text
article_text = article_text.lower()
Next, we remove everything from our dataset except letters, periods, and spaces:
article_text = re.sub(r'[^A-Za-z. ]', '', article_text)
We have preprocessed our dataset and now is the time to create an N-Grams model. We will be creating a character trigram model. Execute the following script:
ngrams = {}
chars = 3
for i in range(len(article_text)-chars):
seq = article_text[i:i+chars]
print(seq)
if seq not in ngrams.keys():
ngrams[seq] = []
ngrams[seq].append(article_text[i+chars])
In the script above, we create a dictionary ngrams. The keys of this dictionary will be the character trigrams in our corpus and the values will be the characters that occur next to the trigrams. Next, since we are creating N-Gram of three characters we declare a variable chars. After that we iterate through all the characters in our corpus, starting from the fourth character.
Next, inside the loop, we extract the trigram by filtering the next three characters. The trigram is stored in the seq variable. We then check if the trigram exists in the dictionary. If it doesn’t exist in the ngrams dictionary we add the trigram to the dictionary. After that, we assign an empty list as the value to the trigram. Finally, the character that exists after the trigram is appended as a value to the list.
If you open the dictionary ngrams in the Spyder variable explorer. You should see something like this:
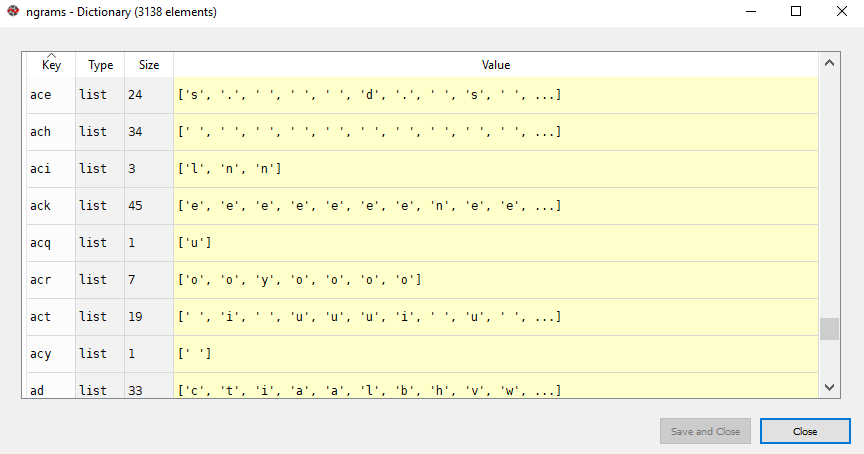
You can see trigrams as keys, and the corresponding characters, which occur after the trigrams in the text, as values. You might see keys with two characters in the dictionary but they are actually not two characters. The third character is actually a space.
Let’s now try to generate text using the first three characters of our corpus as input. The first three characters of our corpus are “ten”. Look at the following script:
curr_sequence = article_text[0:chars]
output = curr_sequence
for i in range(200):
if curr_sequence not in ngrams.keys():
break
possible_chars = ngrams[curr_sequence]
next_char = possible_chars[random.randrange(len(possible_chars))]
output += next_char
curr_sequence = output[len(output)-chars:len(output)]
print(output)
In the script above we first store the first trigram i.e. ten into the curr_sequence variable. We will generate a text of two hundred characters, therefore we initialize a loop that iterates for 200 times. During each iteration, we check if the curr_sequence or the trigram is in the ngrams dictionary. If the trigram is not found in the ngrams dictionary, we simply break out of the loop.
Next, the curr_sequence trigram is passed as key to the ngrams dictionary, which returns the list of possible next characters. From the list of possible next characters, an index is chosen randomly, which is passed to the possible_chars list to get the next character for the current trigram. The next character is then appended to the output variable that contains the final output.
Finally, the curr_sequence is updated with the next trigram from the text corpus. If you print the output variable that contains two hundred characters generated automatically, you should see something like this (It is important to mention that since the next character is randomly chosen, your output can be different):
Output:
tent pointo somensiver tournamedal pare the greak in the next peak sweder most begal tennis sport. the be has siders with sidernaments as was that adming up is coach rackhanced ball of ment. a game and
The output doesn’t make much sense here in this case. If you increase the value of the chars variable to 4. You should see the results similar to the following outputs:
tennis ahead with the club players under.most coaching motion us . the especific at the hit and events first predomination but of ends on the u.s. cyclops have achieved the end or net inches call over age
You can see that the results are a bit better than the one we got using 3-grams. Our text suggestion/filling will continue to improve as we increase the N-Gram number.
In the next section, we will implement the Words N-Grams model. You will see that the text generated will make much more sense in case of Words N-Grams model.
Words N-Grams Model
In Words N-Grams model, each word in the text is treated as an individual item. In this section, we will implement the Words N-Grams model and will use it to create automatic text filler.
The dataset that we are going to use is the same as the one we used in the last section.
Let’s first create a dictionary that contains word trigrams as keys and the list of words that occur after the trigrams as values.
ngrams = {}
words = 3
words_tokens = nltk.word_tokenize(article_text)
for i in range(len(words_tokens)-words):
seq = ' '.join(words_tokens[i:i+words])
print(seq)
if seq not in ngrams.keys():
ngrams[seq] = []
ngrams[seq].append(words_tokens[i+words])
In the script above, we create a Words trigram model. The process is similar to the one followed to use character trigrams. However, in the above script, we first tokenize our corpus into words.
Next, we iterate through all the words and then join the current three words to form a trigram. After that, we check if the word trigram exists in the ngrams dictionary. If the trigram doesn’t already exist, we simply insert it into the ngrams dictionary as a key.
Finally, we append the list of words that follow the trigram in the whole corpus, as the value in the dictionary.
Now if you look at the ngrams dictionary, in the variable explorer, it will look like this:
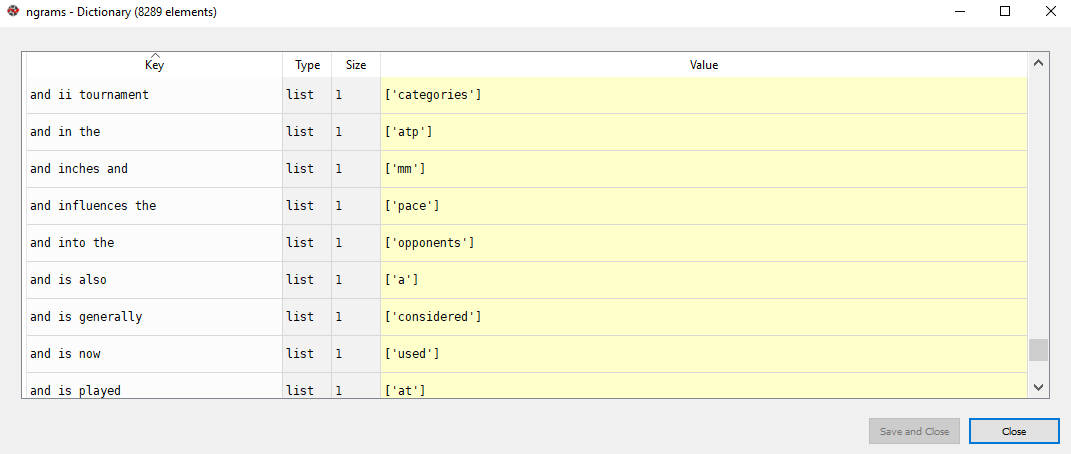
You can see trigrams as dictionary keys and corresponding words as dictionary values.
Let’s now create an automatic text filler, using the word trigrams that we just created.
curr_sequence = ' '.join(words_tokens[0:words])
output = curr_sequence
for i in range(50):
if curr_sequence not in ngrams.keys():
break
possible_words = ngrams[curr_sequence]
next_word = possible_words[random.randrange(len(possible_words))]
output += ' ' + next_word
seq_words = nltk.word_tokenize(output)
curr_sequence = ' '.join(seq_words[len(seq_words)-words:len(seq_words)])
print(output)
In the script above, we initialize the curr_sequence variable with the first trigram in the corpus. The first trigram is “tennis is a”. We will generate 50 words using the first trigram as the input. To do so, we execute a for loop that executes for 50 times. During each iteration, it is first checked if the word trigram exists in the ngrams dictionary. If not, the loop breaks. Otherwise the list of the words that are likely to follow the trigram are retrieved from the ngrams dictionary by passing trigram as the value. From the list of possible words, one word is chosen randomly and is appended at the end of the out. Finally, the curr_sequence variable is updated with the value of the next trigram in the dictionary.
The generated text looks like this. You can see that in the case of word trigrams, the automatically generated text makes much more sense.
Output:
tennis is a racket sport that can be played individually against a single opponent singles or between two teams of two players each doubles. each player uses a tennis racket include a handle known as the grip connected to a neck which joins a roughly elliptical frame that holds a matrix of
If you set the value of words variable to 4 (use 4-grams) to generate text, your output will look even more robust as shown below:
tennis is a racket sport that can be played individually against a single opponent singles or between two teams of two players each doubles . each player uses a tennis racket that is strung with cord to strike a hollow rubber ball covered with felt over or around a net and into the opponents
You can see the output makes even more sense with 4-grams. This is largely because our generator is mostly regenerating the same text from the Wikipedia article, but with some slight improvements to the generator, and a larger corpus, our generator could easily generate new and unique sentences as well.
Conclusion
N-Grams model is one of the most widely used sentence-to-vector models since it captures the context between N-words in a sentence. In this article, you saw the theory behind N-Grams model. You also saw how to implement characters N-Grams and Words N-Grams model. Finally, you studied how to create automatic text filler using both the approaches.
Originally published by Usman Malik **** at stackabuse.com**
============================================
Thanks for reading :heart: If you liked this post, share it with all of your programming buddies! Follow me on Facebook | Twitter
Learn More
☞ PyTorch for Deep Learning and Computer Vision
☞ Practical Deep Learning with PyTorch
☞ Data Science, Deep Learning, & Machine Learning with Python
☞ Deep Learning A-Z™: Hands-On Artificial Neural Networks
☞ Machine Learning A-Z™: Hands-On Python & R In Data Science
☞ Python for Data Science and Machine Learning Bootcamp
☞ Machine Learning, Data Science and Deep Learning with Python
☞ [2019] Machine Learning Classification Bootcamp in Python
☞ Introduction to Machine Learning & Deep Learning in Python
☞ Machine Learning Career Guide – Technical Interview
☞ Machine Learning Guide: Learn Machine Learning Algorithms
☞ Machine Learning Basics: Building Regression Model in Python
☞ Machine Learning using Python - A Beginner’s Guide
#python #deep-learning #machine-learning #data-science
